Hello everyone, I am Xuan Jie.
Before we dive into the main content, let me promote myself a bit. The New Year is approaching, to give back to the support from my fans the “3-Day AI Agent Project Practical Live Training Camp” originally priced at 199 yuan, is now directly reduced to 19 yuan, and today we are opening one more day for registration, limited to 99 spots.
I have always had an idea to build a comprehensive intelligent retrieval-enhanced generation workflow using LLM (Large Language Model) + Agent + RAG (Retrieval-Augmented Generation) + FastAPI, known as the Agentic RAG Workflow. To achieve this goal, I chose a customer support project for practice, during which I faced many challenges (mainly continuously encountering and solving various issues). After some time of effort, I have basically succeeded in setting up and running this workflow. Now, I am eager to share my experiences and summaries with everyone.
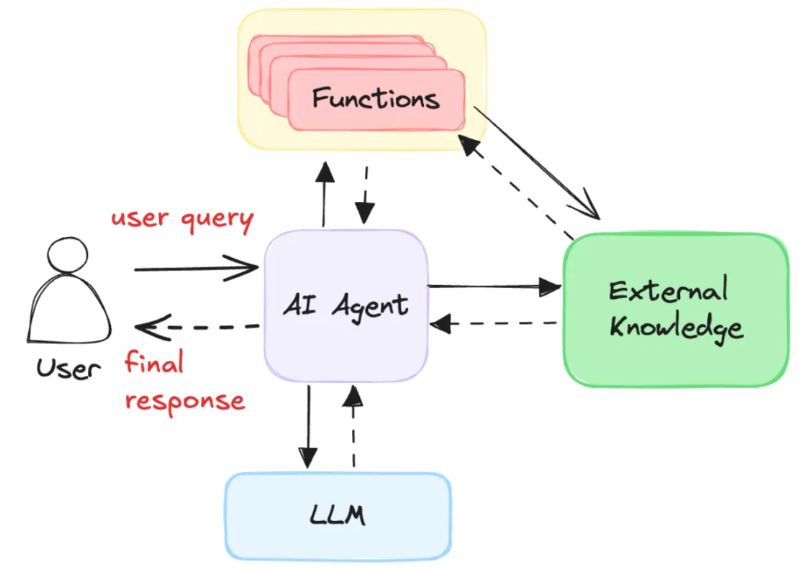
Agentic RAG, which stands for Intelligent Agent RAG, is a model that combines the architecture of AI Agents with RAG (Retrieval-Augmented Generation).
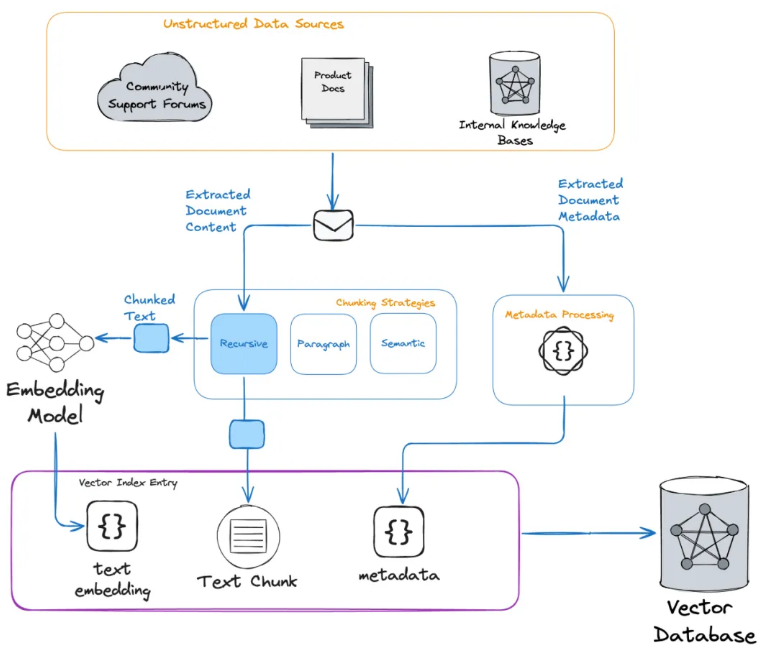
Whether using traditional RAG or Agentic RAG, we can enrich the search index using the RAG Pipeline. The process is as follows:
—1—
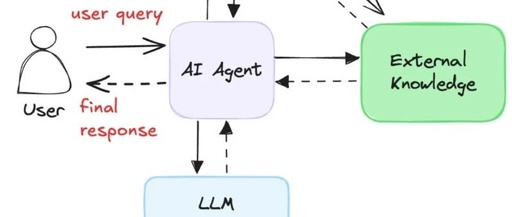
Intelligence of AI Agent
First, the application needs to possess a certain level of autonomous decision-making ability, meaning it should have intelligence. If you have written a program that executes a series of steps, including calling an LLM (Large Language Model) — then congratulations, you have successfully built a program workflow that calls an LLM. There is nothing wrong with this, but such a program cannot be called an AI Agent. A true AI Agent does not act according to predefined exact steps. Instead, it uses the AI large model to decide how to solve problems, rather than hardcoding these steps in the code. This capability grants it intelligence.
Second, the AI Agent needs to have the ability to interact with the external environment. For software applications, this usually means being able to make API calls, retrieve data, send prompts to the LLM, etc. Providers of LLMs give us the mechanisms to achieve these interactions, which we call “tools”. Most LLMs actually only support one type of tool: functions.
The basic application architecture of an AI Agent can be summarized as follows:
—2—
Agentic RAG Processing Loop
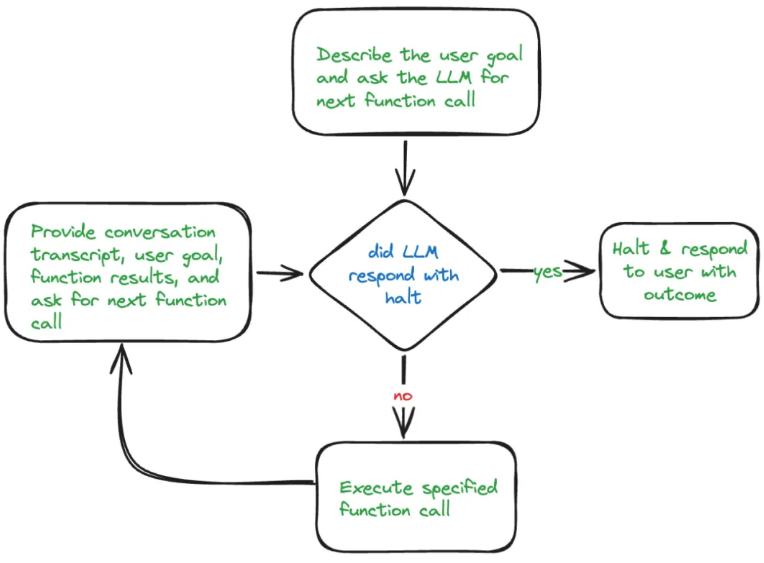
In my customer support project, I wanted the LLM to use the following tools to perform tasks:
-
Retrieve product documentation for product information;
-
Search customer support forums for data similar to user issues;
-
Filter relevant information from the internal knowledge base that may help solve the problem;
-
Terminate the resolution process as a solution has been found;
-
If the AI Agent has made an effort but still cannot solve the problem, escalate the issue to human customer support.
—3—
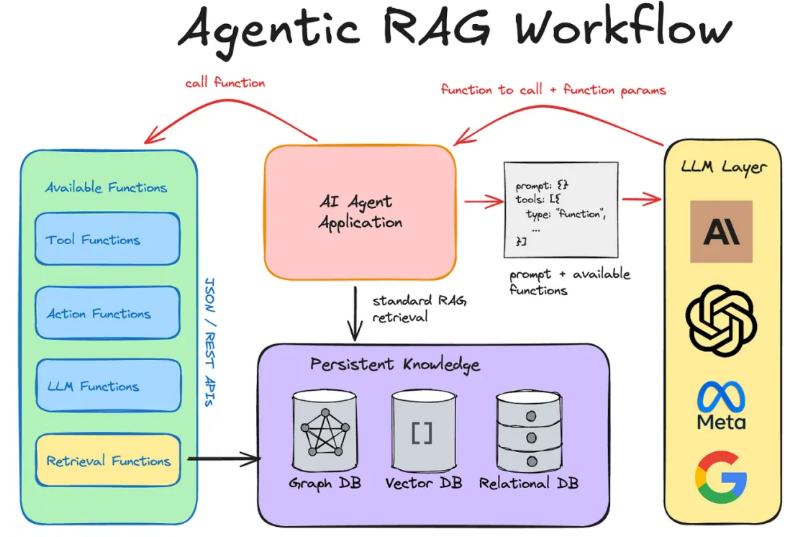
Key to Agentic RAG System: Retrieval Function
The key design difference between traditional RAG systems and Agentic RAG systems lies in the understanding of the retrieval function.
In both systems, we still rely on the RAG Pipeline to populate the vector database.
However, in the process of building the search index, we must anticipate the functions that will interact with the search index.
The design of these functions needs to foresee the operations that the AI Agent may perform to assist the agent in solving the problems we want it to solve.
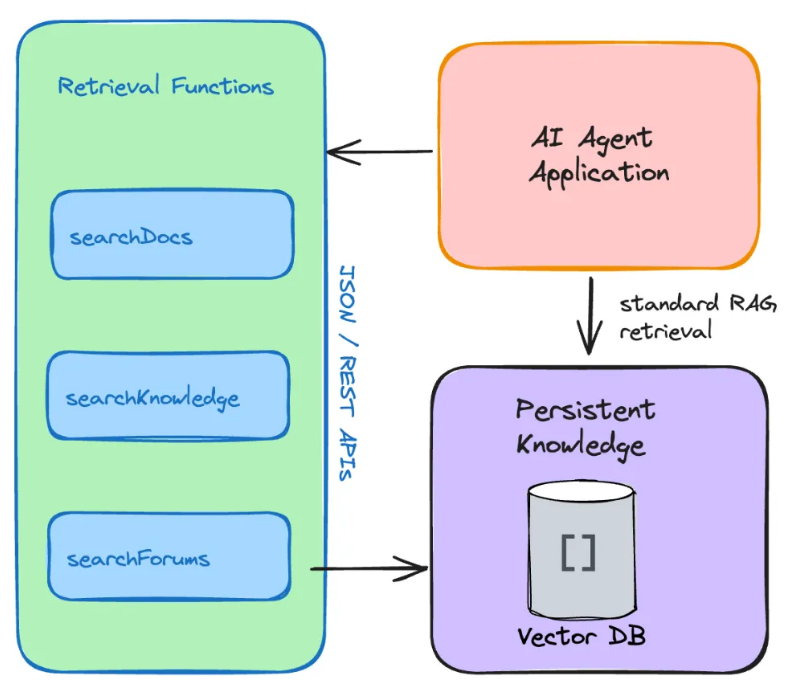
In my first implementation of Agentic RAG, I implemented a function that directly interacts with the vector database I used.
I integrated three unstructured data sources into the same vector index and retrieved information from multiple documents in each system by filling in metadata. For instance, by setting the metadata filter source=docs, I can limit the search scope to the context of internal documents.
However, the initial approach I adopted did not yield satisfactory results. Using this direct method, the function call requests received from the LLM often lacked logic. It might incorrectly set the metadata filter, attempting to search documents in external data sources, or even unreasonably combine various metadata fields, leading to poor search results.
It is understandable that when the quality of retrieved data is low, the quality of generated results will also not be good.
The first significant optimization I made was to break down the direct functions supporting complex queries into smaller, more specific functions. This approach abstracts the underlying data sources, making it easier for the LLM to identify and call the appropriate tools to execute the next tasks.
For example, creating a function named search_docs that accepts a query string and presets the necessary metadata is much more effective than letting the LLM infer using the vector_search function and set source=docs to search internal documents.
Even when I used descriptive JSON schema definitions to clarify the allowable values for the source parameter, the situation remained the same.
In summary:
Direct functions are unreliable: Allowing the LLM to directly interact with the underlying database and handle complex metadata filtering logic can lead to chaotic search behavior and meaningless function calls.
Small dedicated functions are more efficient: By breaking down functions that support complex queries into smaller dedicated functions (like search_docs), the LLM can more easily identify and call the appropriate tools, thus enhancing the accuracy of retrieval and the quality of generated results.
This approach effectively alleviates the reasoning burden on the LLM, guiding it to use specific functionalities in a more structured manner, which not only improves retrieval efficiency but also significantly enhances the quality of generated results.
—4—
Building AI Agents Using LLM
The reasoning ability of LLM in default settings is often weak, although some large models perform relatively well. The smallest model I have tried is Llama 3.1 8B, which performed the worst.
First, JSON Mode
This model often ignores function call instructions and outputs invalid JSON during generation, causing the AI Agent application to frequently encounter JSON parsing exceptions.
The 70B version of the Llama large model performs slightly better but still does not meet ideal standards.
When I initially launched this project, OpenAI’s latest public model was gpt-4-turbo. Even with JSON mode enabled, one out of every four to five generated responses still outputs invalid JSON.
Second, Prompt Engineering
Prompt engineering is a crucial aspect of any RAG system, and the Agentic RAG system is no exception.
Although efficient data management strategies help improve information retrieval performance, this alone is not enough to ensure ideal results.
As a benchmark, I tried providing the LLM with extensive instructions to respond to user queries and handed over function definitions to the LLM to observe how much this approach could drive task completion. My initial prompt was as follows:
You are an automated AI technical support assistant for a software platform company. Your task is to help users solve technical problems and inquiries.Here is the user’s input.Your goal is to assist users in achieving their objectives to the best of your ability.
Of course, calling the chat API also included a set of function definitions.
As mentioned earlier, at this stage, I broke down the retrieval functions into more specific, finer-grained functions.
Based on the initial prompt, Claude and gpt-4-turbo often generate incorrect responses when handling input queries.
To address this issue, I updated the prompt to clearly inform the LLM that it should not generate a response unless it is certain that the answer is correct.
You are an automated AI technical support assistant for a software platform company. You are responsible for helping users solve technical problems.
You can access product documentation to understand detailed information about the company’s products and services. You can consult the internal knowledge base containing operational guide articles. You can also access community forums where users frequently seek help. You can use the information from these resources to assist users in solving problems.
Unless you are confident that you have an accurate answer to the user’s question, please use the escalate_to_human function to transfer the issue to human support. If you are unsure, do not fabricate answers.
Here is the user’s input. Your goal is to do your utmost to help users achieve their objectives.
Using the chain of thought (CoT) of the Agentic RAG system
In this scenario, the LLM needs to possess the following reasoning abilities:
-
Decide the next action steps to get closer to solving the user’s problem.
-
Determine when a solution to the problem has been found.
-
Decide when to give up and escalate the problem to human handling.
My first thought was to refer to CoT research to see if these advanced reasoning mechanisms could be applied here. However, the CoT method did not show significant results for my use case.
CoT techniques are typically used in academic papers to solve mathematical application problems that involve repeatable step-by-step solutions and have clear correct answers. However, the scenarios faced by my AI Agent are different, as it needs to make decisions in uncertain environments, rather than just looking for a “correct answer.”
—5—
Iteratively Building a Usable Agentic RAG Solution
First, Clearly Record Historical Interaction Information
Although I included chat records in each processing loop, I noticed that the LLM sometimes ignored information it had previously discovered. For example, the LLM might:
-
Search documents through Agentic RAG and get a result;
-
Then look for related information in the knowledge base;
-
Yet later return to search the same or extremely similar queries in the documents.
To overcome this issue, I added a new instruction:
Please review the historical interaction records to understand what you discovered previously.
The purpose of this instruction is to remind the LLM to recall and utilize previous search results before executing redundant searches, thus reducing unnecessary repetitive operations.
Second, Breakthrough: Structured Responses
While I was implementing the Agentic RAG for this case, OpenAI launched their gpt-4o model and introduced the feature of structured responses.
This allows the AI Agent to perform better in ensuring data integrity in responses and retrieving necessary information through information retrieval. Nevertheless, I still frequently encounter situations where the LLM generates invalid JSON responses, interrupting the processing loop.
Using structured responses set to strict=true helps improve this issue. OpenAI seems to have made progress in this area through scientific research.
With structured output, the AI Agent built using the Agentic RAG approach began to generate reliable and trustworthy output.
—6—
Lessons Learned from Building Agentic RAG
First, Many Lessons from Traditional RAG Apply to Agentic RAG
Just like traditional RAG, Agentic RAG also relies on contextually relevant content to assist the LLM in generating more comprehensive responses. The quality of data is crucial.
To address the issues faced by Agentic RAG, building downstream RAG pipelines from unstructured data sources for comprehensive information retrieval is indispensable. Like traditional RAG, Agentic RAG also needs to acquire up-to-date information.
Second, Do Not Over-Rely on the Reasoning Ability of LLM
Our Agentic RAG system can also make mistakes. The development of Agentic RAG is often more of an art than a science. We need to establish continuous quality assurance mechanisms and other external tools to monitor the performance of the AI Agent over time.
Third, The Core Challenge of Agentic RAG Remains the RAG Pipeline
I have similar feelings about every RAG framework I have tried. They often focus on the easiest parts of the problem (data retrieval and interaction with the LLM are relatively simple).
Handling the many details and challenges of non-structured data sources in data engineering to provide the most recent information optimized for information retrieval is the complex and tedious part of the retrieval-augmented generation process.
—7—
Looking Ahead: Autonomous Agents and Multi-Agent Systems
First, Promote Collaboration Among Multiple AI Agents
Building a single AI Agent’s Agentic RAG system faces numerous design and implementation challenges. As task complexity increases, it becomes logical to assign responsibilities to a multi-agent AI system. When multiple AI Agents come together to build an intelligent system, we must consider a series of new architectural issues.
We still need to address common requirements such as secure communication protocols and handling sensitive or confidential data. When implementing an Agentic RAG architecture that requires multiple AI Agents, managing system resources, access control, and implementing robust data protection measures become critical tasks.
Second, Autonomy in Agentic RAG
In many application scenarios of Agentic RAG, there is no direct interaction between the end user and the AI Agent. Instead, autonomous AI Agents identify and solve problems on their own.
For instance, content moderation, copyright infringement detection, and quality assurance systems require autonomously operating Agentic RAG agents.
This introduces a new dimension to the processing loop. These Agentic RAG agents are often event-driven, and they need to determine not only the best way to achieve specific goals but also to identify the goals themselves.
In this case, the Agentic RAG system needs to access textual and visual data, vast knowledge graphs, and natural language understanding capabilities. The Agentic RAG approach still relies on information retrieval, integration with large language models, and the use of external tools. Additionally, it may involve more complex queries and processing logic to support the autonomous operation of Agentic RAG agents.
In summary, how can we systematically master the importance of AI Agent technology? My team and I have spent two years implementing large model projects, helping over 60 companies land nearly 100 projects based on our enterprise-level practical experience, creating a 3-day AI Agent project practical live training camp, which has seen 20,000 students registered to date, such a hot trend! Originally priced at 199 yuan, now as a gesture of gratitude for fan support, the price is directly reduced to 19 yuan, and today we are opening registration for just one more day, limited to 99 spots, after which it will immediately return to 199 yuan.
—8—
Why Are AI Agents So Important?
First, this is an unstoppable trend, we are experiencing a major technological transformation, unlike the rise of the internet back in the day; this is a disruptive change, falling behind means elimination, as all future applications will be rewritten by AI Agents;

The courseoriginally priced at 199 yuan, now only 19 yuan to get it! At the end of the article, we will also offer 4 registration benefits! Once they are gone, it will immediately return to 199 yuan!
—9—
What Can You Gain from the 3-Day Live Training Camp?
In this 3-day live course, you will quickly master the core technologies of AI Agents and practical experience in enterprise projects.
Module 1: Principles of AI Agent Technology
Comprehensively dismantle the principles of AI Agent technology, deeply understand the three major capabilities of AI Agents and their operational mechanisms.
Module 2: Practical Development of AI Agents
In-depth explanation of AI Agent technology selection and development practice, learn to develop the core technical capabilities of AI Agents.
Module 3: Enterprise-Level Case Practice of AI Agents
From demand analysis, architecture design, technical selection, hardware resource planning, core code implementation, to service governance, learn to solve key difficulties throughout the entire process of enterprise-level AI Agent projects.

Limited Time Offer:
—10—
Today, sign up and receive 4 matching benefits
Benefit One: AI Agent training camp matching study materials, including: PPT courseware, practical code, enterprise-level intelligent agent cases, and supplementary study materials.
Benefit Two:AI Agent training camp learning notes, containing all the highlights of the 3-day live session.
Benefit Three:100 Real Interview Questions from Major Companies for AI Agents! Covering 100 real questions from major companies like Baidu, Alibaba, Tencent, ByteDance, Meituan, Didi, etc., which are significant for both job changes and promotions!
Benefit Four: 2024 China AI Agent Industry Research Report! AI Agents are a new application form, the “APP” of the large model era, and the technological paradigm has also changed significantly. This research report explores the new generation of human-computer interaction and collaboration paradigms, covering technology, products, business, and enterprise landing applications, and is very worth reading!
Originally priced at 199 yuan, now 19 yuan!
—11—
Add Teaching Assistant for Live Learning
After purchasing, add the assistant for live learning👇
After signing up, add the assistant using the QR code above to immediately receive 4 benefits!
Reference: https://mp.weixin.qq.com/s/dfHQ3Z6ym6pblVWTtuN7SA
END