
[Improving 1% daily leads to a 37.78x increase in a year]
Core Insights
Agentic AI is the future direction of the enterprise software stack, but its realization is not an overnight process; rather, it is a gradual evolution spanning a decade.
Key Supporting Technologies
-
Cloud Scalability: Possessing elastic scaling capabilities similar to cloud computing to handle the massive data and computational demands generated by Agentic AI.
-
Unified Metadata Model: Establishing unified data description and management standards to break down data silos and achieve data sharing and interoperability.
-
Data Mesh Organizational Principles: Adopting the concept of a data mesh, treating data as a product to achieve distributed management and autonomy.
-
Deep Integration of Data and Business Process Logic: Closely integrating data with business processes to achieve data-driven business process optimization and automation.
-
Orchestration Framework Integrating Governance, Security, and Observability: Establishing a comprehensive governance, security, and observability system to ensure the reliable operation and management of Agentic AI.
Development Path
The explosion of Agentic AI requires a lengthy development process; 2025 may only be the beginning, and true transformation may take 2 to 10 years to unfold completely.
Transformation of the Software Stack
-
Transfer of Control: Control will shift from Database Management Systems (DBMS) to the Governance Layer.
-
Value Reshaping: New competitive focus and value will center on the unity of business logic and business processes.
-
Architectural Transformation: Traditional applications and data silos will be abstracted, and enterprise software will be reshaped around a multi-repository CRUD database architecture, with all business logic integrated into the AI layer.
Challenges and Opportunities
-
Challenges: How to break down existing technology silos, achieve the unity of data and business processes, and avoid fragmentation risks during the development of Agentic AI.
-
Opportunities: Agentic AI is expected to bring a tenfold increase in productivity for enterprises, achieving end-to-end operations and unified planning, integrating enterprise management into software systems for continuous optimization.
Vendor Roles
-
Data Platform Providers: Snowflake and Databricks lead the data characterization work of core business entities.
-
Cross-Silo Business Process Layer Builders: Relational AI, Celonis, and EnterpriseWeb focus on building business process layers that span different data silos.
-
Business Process Coordinators: Palantir, Oracle, and Salesforce coordinate business processes within their ecosystems.
-
Intelligent Agent Orchestration Layer Builders: Google, Microsoft, and UiPath are dedicated to building orchestration and communication frameworks for intelligent agents.
—— The Next Decade of Enterprise Software Stack

The development path of Agentic AI will be firmly established by a series of interrelated key technologies. Our research indicates that Agentic AI will not emerge out of thin air; it must be built on a solid data foundation, including:
-
1) Capability for cloud-like scalability;
-
2) Unified metadata model;
-
3) Data mesh organizational principles;
-
4) Deep integration of data and business process logic;
-
5) Orchestration framework integrating governance, security, and observability.
While some believe that 2025 will be the year of the explosion of Agentic AI, we predict that achieving this goal will be a long journey lasting a decade, with no shortcuts available. The ideal path to intelligent agent automation is gradual and requires steady integration of various technological capabilities.
In this article, we integrate past research to reveal the significant changes that the enterprise software technology stack is about to undergo. We will elaborate on how this technological evolution path unfolds, analyze the key elements of emerging enterprise software architectures, and discuss the high-value technological hierarchies still shaping this system.
Research Background Review
Over the past two years, we have continuously researched the impact of AI on the enterprise software technology stack, aiming to cut through the marketing fog surrounding the concept of “intelligent agents” and highlight the necessary conditions for achieving Agentic AI. We explored the evolution of the data technology stack, noting that it is no longer limited to the separation of computation and storage but further emphasizes the decoupling of computation and data, and analyzed the innovations brought by open table formats such as Iceberg and their potential integration with Delta. Additionally, we studied the necessity of unified metadata and the trend of the control layer shifting from databases to governance layers, a change that is reshaping the entire technology stack (e.g., the open governance frameworks of Unity and Polaris). All of this is built upon Zhamak Dehghani’s early proposal of the data mesh concept, which aims to break down data silos.
Earlier, our research focused on metadata-centric configurable business processes, using Salesforce Data Cloud as an example. Recently, we further explored the integration of data and shared business logic, examining how technologies like Celonis, Palantir, and RelationalAI achieve collaborative optimization of data and logic.
AI Needs a New Software Technology Stack
AI is accelerating transformation and disrupting the enterprise software technology stack that has existed for fifty years.

Many believe that the current wave of AI is one of the most influential transformations in the history of technology, and we agree, likening it to the revolutionary impact of mobile computing driving the migration of on-premises workloads to the cloud. However, we believe the impact of AI is even more profound. To fully leverage the role of AI agents, we must completely reshape the software technology stack, breaking down the technology silos that have formed over the past fifty years. The rise of data lakehouses does not truly solve this problem; they merely represent larger data silos. Instead, the SaaS (Software as a Service) model itself will also be fundamentally redefined.
Two well-known CEOs of enterprises have expressed agreement on this. At the recent AWS re:Invent conference, we spoke with Amazon CEO Andy Jassy, who shared the following insights on the future of SaaS:
At the same time, Satya Nadella discussed this topic in-depth on the BG2 podcast (BG2 Pod). He described it as follows:
Jassy believes that the combination of cloud computing and AI is the core driving force of transformation, while Nadella emphasizes that future enterprise software will be reshaped around a multi-repository CRUD database architecture, with all business logic integrated into the AI layer. When Nadella talks about “replacing the backend,” he aligns with Jassy’s view that the SaaS field will undergo significant changes.
Nadella’s vision is essentially a ten-year long-term plan; he did not detail the intermediate steps to achieve this vision. Perhaps one day in the future, we will be able to convert all decisive rules and business logic into a non-deterministic neural network, i.e., in the form of an intelligent agent. However, current technologies have not reached this level. Therefore, before moving from the current state to the future described by Nadella, we need to go through multiple stages of development.
In short, Nadella’s viewpoint implies that we can “kneecap” each SaaS application, reducing it to merely a component of a database architecture. But doing so will trigger a new “Tower of Babel” dilemma, where a group of AI agents cannot effectively communicate with one another—despite the vision of enabling agents to interact across databases.
The Modern Cloud Data Stack: The Starting Point of the Journey
Let us begin with the current architecture of modern data platforms. A few years ago, we began exploring the concept of sixth-generation data platforms, which gradually evolved from the existing five modern data platforms (such as Snowflake and Databricks).
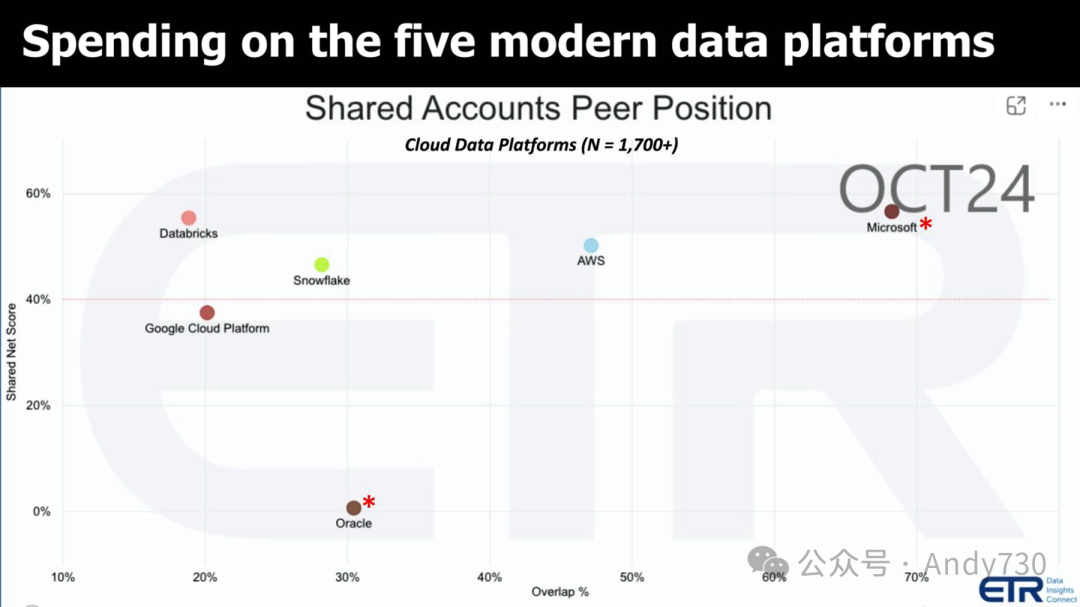
The above figure displays data statistics, with the vertical axis representing Net Score (Net Score) or spending momentum, and the horizontal axis representing Overlap (Overlap) or penetration within a dataset of over 1,700 IT decision-makers. We plotted the performance of Snowflake, Databricks, and Google, AWS, and Microsoft, adding Oracle as a representative company in the traditional database market for comparison. The red dashed line indicates a Net Score of 40% as the critical point for high spending momentum. Although Microsoft and Oracle have also made inroads into the data field, they do not fully represent the direction of modern data stack development and are therefore not the main focus of today’s discussion. However, it is worth emphasizing that they are both at the core of this technological transformation, facing both opportunities and challenges.
The starting point of the ideal path
As shown in the above figure, the cloud data platform is the starting point of our ideal path.
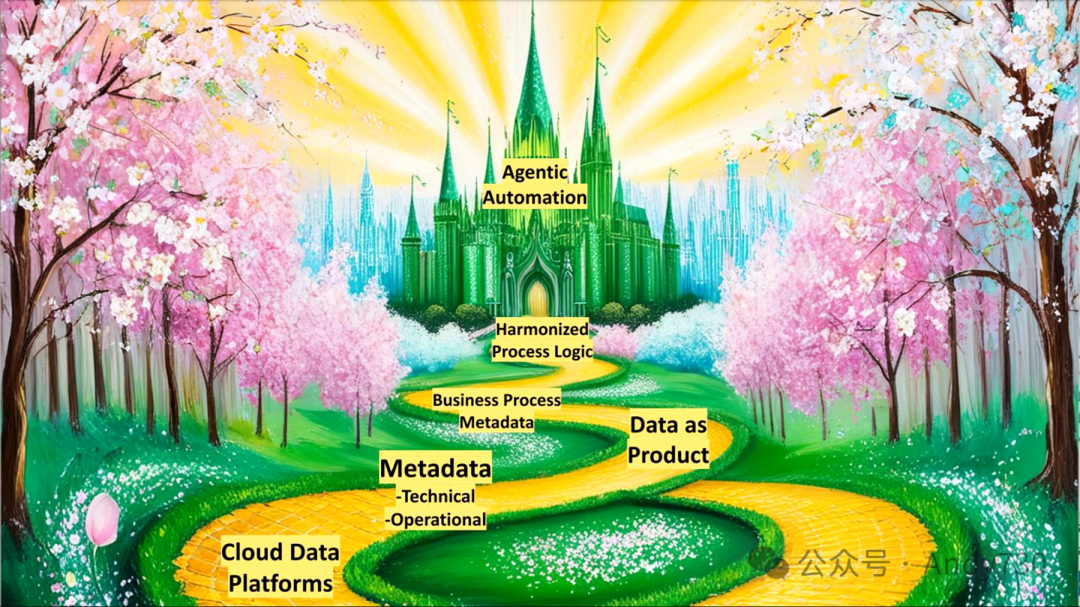
As revealed in our previous research, the industry is experiencing a trend of shifting from database layer control to governance catalogs. In the above figure, this governance catalog is labeled as “operational metadata,” which is laying a solid foundation for new application platforms. For example, Snowflake’s Horizon and its open-source catalog Polaris, Databricks’ Unity, as well as mature governance platforms like Informatica, Collibra, and Alation, all play significant roles in this transformation. Enterprises are rethinking how to organize around data, adopting concepts such as data mesh and managing data as a product. They are fully utilizing information about people, places, and things to optimize data flow in distributed organizations. The real transformation lies in the integration of business processes and the collaboration of data and processes to support a series of intelligent agents working together to achieve goal tasks.
The earliest cloud data platform, Snowflake, was the first to achieve the separation of compute and storage. As the industry continues to evolve, more enterprises are realizing the need for further decoupling of computation and data. The rise of open table formats (OTFs) allows multiple computing engines to access the same dataset, which requires independent metadata storage to support, including technical and operational metadata (such as data lineage information). This metadata forms the basis of data pipelines and defines key concepts such as “customer,” “product,” or “lead.” However, these concepts are still static entities at this stage.
For example, the current approach simulates the actual business processes of enterprises through business process metadata, from customer interactions to prospect mining, and finally to lead follow-up, ultimately achieving conversion. Although this approach provides a static configurable model that can somewhat adapt to different customer needs, its flexibility remains limited.
Salesforce’s Data Cloud excels in customer data management, supporting a Customer 360 view, achieving a unified representation of the entire customer journey, thereby providing strong support for analysis and applications. This approach is not just about sharing data tables; it is about sharing the concept of “customer” and their entire journey. The next challenge lies in transcending static metadata to achieve the sharing of business process logic, allowing it to flow freely between multiple applications, thereby achieving ultimate flexibility.
If business process logic can be unified, intelligent agents will be able to communicate efficiently across the Customer 360 view and the entire customer journey, using a unified language for interaction. However, in the current environment, agents still need to painstakingly search for information between discrete data tables. For instance, a large financial institution (like JP Morgan) may have 6,000 different tables to store customer information, creating a modern version of the “Tower of Babel” phenomenon, resulting in severe data silo issues that hinder intelligent automation.
This is closely related to the viewpoint that future SaaS applications may be simplified to a database schema. Currently, enterprises still possess thousands of independent tables, each with different definitions of “customer,” making connections difficult. Existing technologies are not yet capable of automatically coordinating such complex semantic differences among AI agents. Therefore, there is an urgent need for symbolic harmonization, allowing agents to communicate using the same language. This unified logic is crucial for achieving true automation. While there may come a time in the future when we can completely eliminate the logic layer, that remains a distant goal.
Transformation of the Enterprise Software Stack: Transfer of Control and Value
Next, let us delve into the changes in the enterprise software stack.
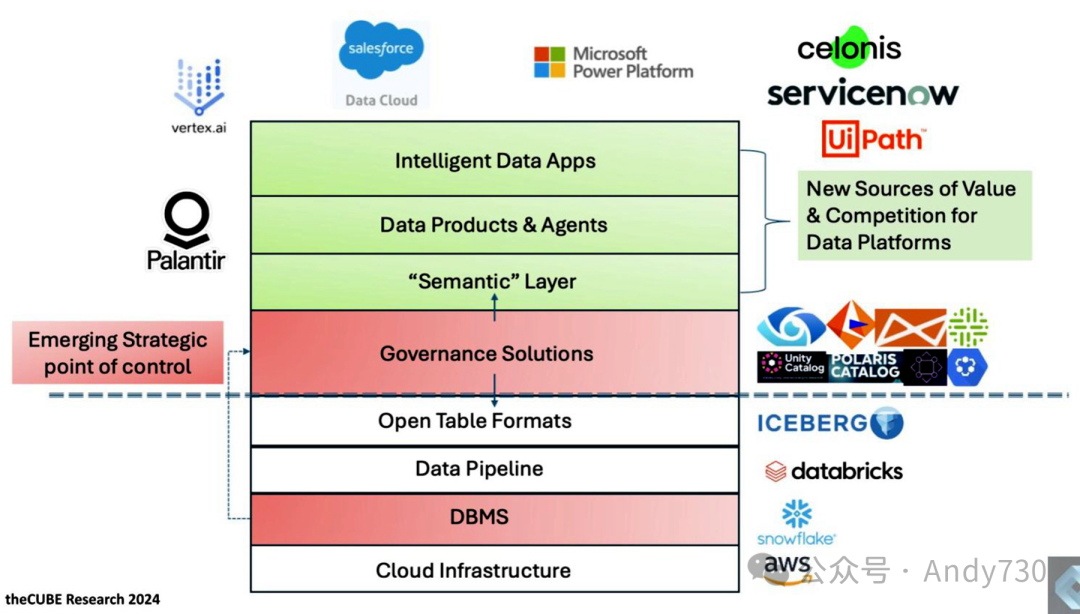
This concept was proposed earlier this year. At the bottom layer of the software stack, AWS provides foundational cloud infrastructure, while cloud vendors such as Google, Microsoft, and Oracle (via OCI) are also actively involved. Snowflake was the first to promote the separation of compute and storage, enabling cloud data warehouses with near-infinite scalability. Databricks focuses on data science and data pipeline areas, driving the development of open table formats (such as Iceberg). Databricks also acquired Tabular and is working to unify Delta and Iceberg formats. Additionally, AWS announced support for S3 tables and open table formats at the re:Invent conference, further promoting the integration of data readability and governance capabilities.
The most significant change (as shown in the left chart) is the transfer of control from database management systems (DBMS) to the governance layer. This governance layer is becoming increasingly open source and elevating the importance of the so-called “green layer.” The green layer includes the semantic layer, which serves to unify the definition of data. However, as previously discussed, the current focus is no longer solely on the data itself but on how to unify business logic and business processes. This is the new competitive focus and value. Salesforce, Palantir, Celonis, and other companies are actively participating in this emerging ecosystem and striving to create a new competitive landscape.
In the past, the core competitiveness of data platforms lay in the control of storage by DBMS. However, with the emergence of open table formats, DBMS can no longer monopolize the state information of tables, as multiple computing engines can read and write data. Therefore, control is gradually shifting to the operational catalog. Databricks’ Unity Catalog, launched in 2023, has already become a strong competitor in this field. Although Databricks has stated plans to open-source Unity Catalog, it has not yet fully realized this. However, Databricks’ execution is strong, and the unification process of Iceberg and Delta may happen faster than initially anticipated, with completion expected in the first quarter of 2025.
Snowflake’s Horizon Catalog has become the new “single source of truth” within its ecosystem, still running on the Snowflake engine but capable of synchronizing with Polaris. This means that governance policies set in Horizon can extend to the open Iceberg ecosystem.
On top of this, we enter the discussion of the semantic layer. At this layer, we need to define key business concepts such as “customer,” “product,” “lead,” and “campaign.” This is the first step of the semantic layer’s work. More challenging is the unification of business processes, which requires fundamental changes to decades-old database architectures. If this goal is achieved, future AI agents will be able to operate efficiently in this new environment.
What will the future software stack look like?
Let us envision the software stack in a future stable state.
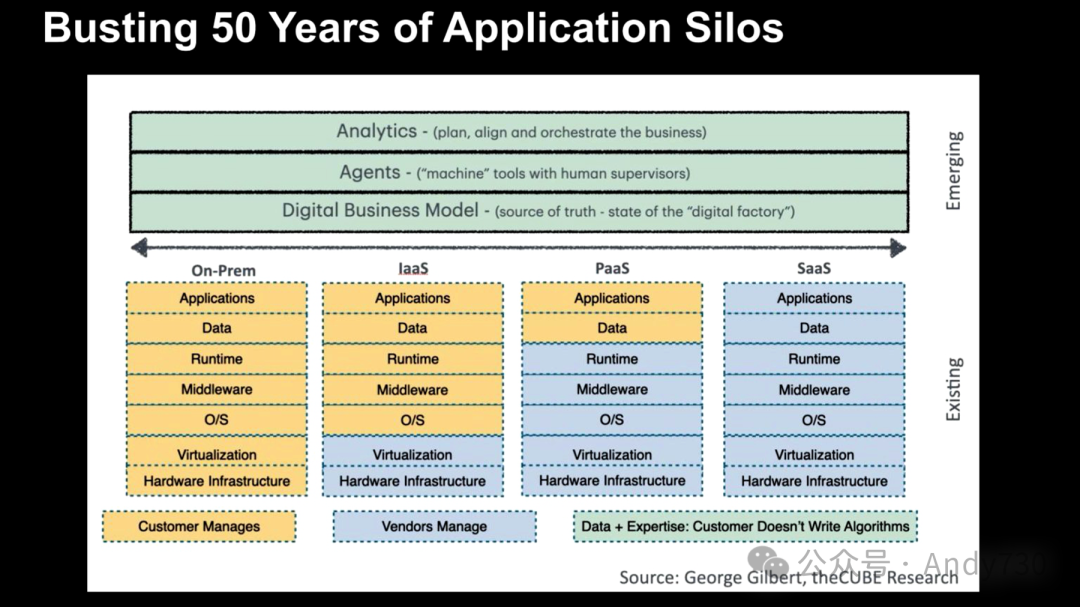
The journey of enterprises migrating from on-premises environments to the cloud began with the IaaS phase, greatly alleviating the burden of infrastructure management. Subsequently, the rise of PaaS and SaaS transformed more infrastructure management tasks into managed services, tasks that vendors like Amazon see as “undifferentiated heavy lifting.” However, the true innovative value is gradually emerging at the top layer of the stack—the green layer.
Within this green layer, three core levels are covered: digital representation of a business, network of agents, and a new analytical layer driven by top-down organizational goals. This architecture enables the system to interpret enterprise objectives and adjust based on market changes or human guidance. Ultimately, the system takes action in a controlled manner through collaboration among intelligent agents and interactions with humans, achieving bottom-up business outcomes.
This entirely new software stack architecture integrates the application and data silos built over the past 50 years. These silos can now be abstracted and transformed into what Satya Nadella refers to as “sediment.” Nadella’s viewpoint focuses on the data layer, while this article’s perspective emphasizes the application logic layer that carries intelligent agents.
The business drivers for this transformation are clear. In the future, the competitive advantage of enterprises will depend on how tightly they can integrate end-to-end operations with a unified planning system. From three-year strategic demand forecasts to real-time decision-making (e.g., how to pick, pack, and ship orders to achieve long-term goals), enterprises need to plan and allocate resources across different time scales. However, traditional management methods overly rely on human experience, and past software systems cannot seamlessly execute these plans.
To achieve end-to-end integration, the primary task is to construct a harmonized digital representation of the business as a foundation. Based on this, the analytical system can collaboratively schedule intelligent agents, enabling them to operate not only in siloed environments but also in collaboration with humans. Thus, enterprise management will gradually integrate into software systems, becoming a continuously optimized, evergreen capital project. Enterprises will no longer rely solely on the tacit knowledge of management teams but will gradually transform this knowledge into a highly integrated software product.
The Emerging High-Value Layers in the Software Stack
Let us delve into the rapidly rising high-value layers within the software stack, which have been mentioned in previous discussions but deserve further exploration.
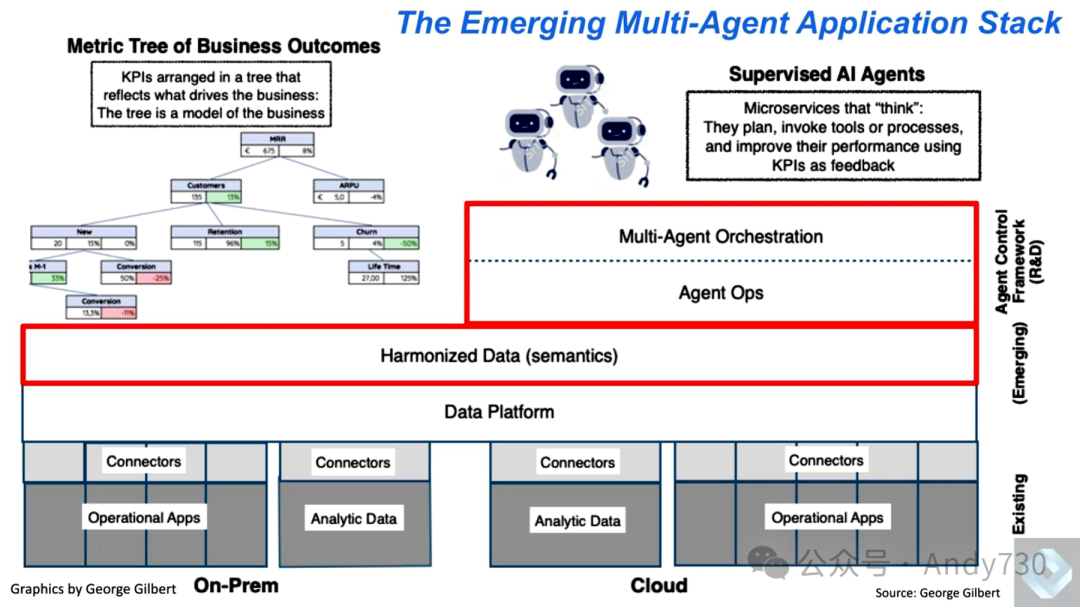
Our envisioned direction of development is to connect backend systems (both analytical and operational) to extract business logic that has been locked within applications, making it more accessible in real-time environments. The goal of this approach is not only to rely on historical data analysis systems to provide retrospective snapshots but also to achieve continuous decision-making and automate workflows. In this architecture, there are two key layers that require special attention, highlighted in red in the following diagram:
The unifying layer, responsible for harmonizing data and business logic.
The agent control framework, used for orchestration and communication among intelligent agents and between agents and humans.
At the top layer of the software stack, organizational goals drive the entire process. For example, a company’s high-level goal might be to increase market share, which further breaks down into specific requirements regarding profit margins, pricing constraints, revenue targets, and execution strategies. Intelligent agents can understand these goals and make bottom-up decisions within the established guidance framework. Agents collaborate with each other and incorporate human input to dynamically adjust market strategies while ensuring compliance with the top-down business framework.
This architecture is crucial because business objectives are often represented in the form of a “metric tree.” This metric tree structure is not just a dashboard or historical report; it is the “dials on a management system” of a dynamic management system. The relationships between the various metrics require long-term learning and optimization. Through predictive and process-centric platforms, enterprises can conduct experiments, observe outcomes, and continuously refine their understanding of strategies such as demand shaping.
When this architecture is combined with AI models and training cycles, intelligent agents can learn from human interventions and business execution results. If an agent encounters an unmanageable exception, a human can intervene and guide the problem-solving process. Over time, agents will accumulate experience from these “teachable moments” and gradually become capable of independently resolving similar issues. Similarly, when agents attempt to shape market demand and measure its impact on business metrics, they can gain deeper insights, thereby continuously enhancing their capabilities.
This learning framework—unifying data, business processes, and metric-driven goals—constitutes a scarce and highly valuable layer within the enterprise software stack. In the future, while enterprises may deploy numerous intelligent agents, only a very few within any organization will achieve this level of business process platform. Ultimately, as intelligent agents learn from direct human interventions and the outcomes of their actions, their capabilities will continuously improve, driving leaps in enterprise innovation and operational efficiency.
Which technology vendors are leading the Agentic era?
Currently, many enterprises are actively participating in this transformation, and here are some key vendors we are focusing on, along with their value contributions in the emerging software stack.
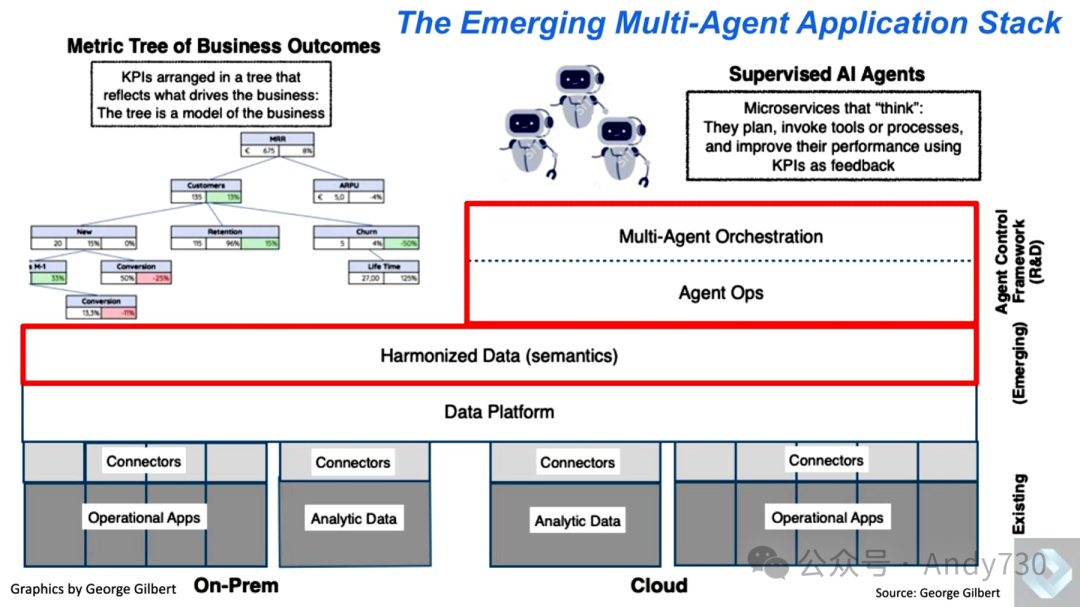
At the bottom of the software stack, data platform providers like Snowflake and Databricks are leading the data characterization work of core business entities. Other companies like Relational AI, Celonis, and EnterpriseWeb focus on building the business process layer that spans across silos. Above this layer, companies like Palantir, Oracle, and Salesforce are harmonizing business processes within their respective ecosystems. Further up, a new intelligent agent orchestration layer is forming, represented by Google, Microsoft, and UiPath, with the industry widely believing that AWS will also play a key role in this evolution, as indicated by its recent announcements and development trends.
It is noteworthy that the transition from business entity representation (i.e., people, places, assets, etc.) to the definition and alignment of cross-silo business processes is a highly challenging task. Over the past decades, the industry has invested significant energy into developing data and application logic technologies to integrate these core elements. For instance, Relational AI employs relational knowledge graphs, allowing enterprises to define application logic declaratively, similar to how SQL statements express demands, greatly simplifying the logic description process. Celonis provides foundational components for business processes, enabling customers to conduct process mining and configuration with minimal coding. Palantir excels in deep integration with core transaction systems but requires more procedural coding since it does not provide out-of-the-box application templates. Salesforce leverages its Data Cloud to cover the entire Customer 360 realm, including customer journeys and touchpoints, and adapts to its models through configurable business logic. UiPath specializes in automating processes, including those lacking API support.
These approaches reveal the complexity of coordinating business logic across multiple platforms. To build a complete metric tree to measure business outcomes, enterprises must have a consistent representation of business processes. This is not simply about connecting the schemas of different applications; more importantly, it involves establishing a complete enterprise “business physics,” i.e., its behavior and logic, allowing high-level goals (such as increasing market share) to be associated with more specific operational metrics. If the underlying application logic fails to achieve unified coordination, it will be challenging to build a coherent representation of business outcomes.
In short, while enterprises have made significant progress in the large-scale integration of data, the next frontier challenge lies in fully integrating data and business processes within a unified software stack. This breakthrough will unleash the potential of intelligent agent orchestration, bringing enterprises new automation, insight capabilities, and adaptability.
How AI Achieves a Tenfold Increase in Productivity
Erik Brynjolfsson reveals the enormous opportunities of the AI era through a power law curve, annotated by George Gilbert.
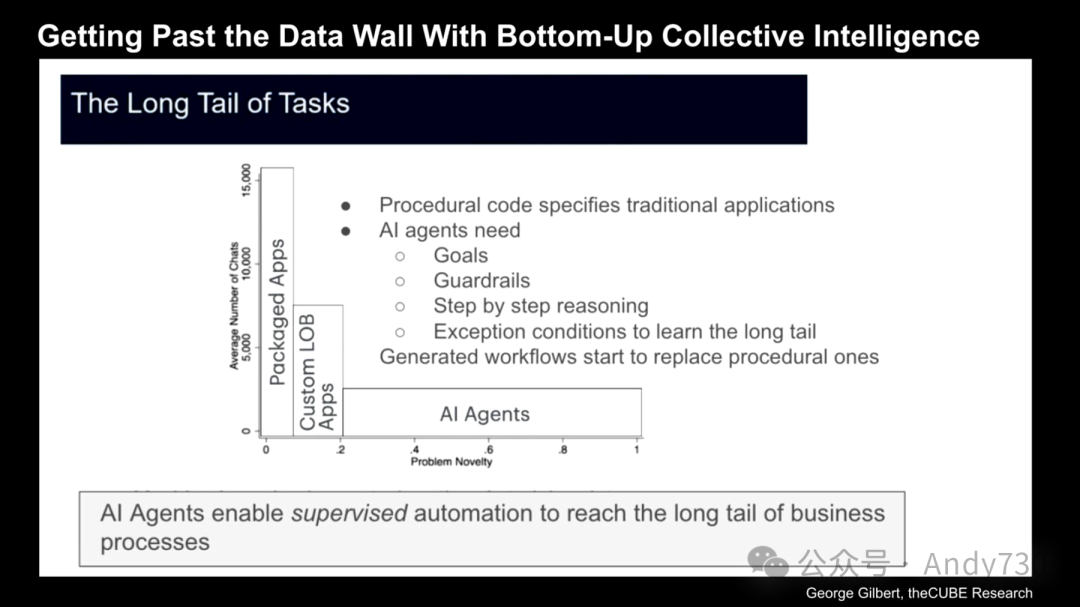
The core of the current enterprise AI frenzy is productivity enhancement. On the surface, this means achieving the same or higher business outcomes with fewer people. Many industry observers, such as David Floyer, often discuss how AI can achieve the same business goals with fewer employees. However, the key lies in how AI can truly play a role in the enterprise environment.
Historically, enterprise software has primarily been used to automate high-frequency, repeatable business functions, typically focused on back-office or other clearly defined areas. Enterprises then gradually introduced customized modifications and proprietary applications to meet specific industry, specialized datasets, or unique organizational needs, thereby expanding the coverage of automation.
However, aside from these predefined automation scenarios, there remains a vast number of uncovered long-tail workflows. These workflows often involve complex exceptions and unstructured tasks, in which AI agents are demonstrating exponential potential for productivity enhancement. Compared to traditional software, which relies solely on pre-coded deterministic logic, the next generation of intelligent agents will possess dynamic learning capabilities. They will be able to observe execution outcomes, incorporate human feedback, and continuously adjust and optimize their decisions.
In other words, on the left side of the curve, enterprises achieved automation of highly repetitive tasks through deterministic logic. Meanwhile, in the long tail, there are numerous low-frequency but important processes that are difficult to automate comprehensively using predefined rules. By deploying sustainable learning AI agents, enterprises can gradually take control of these complex unstructured processes. However, current technology still cannot fully replace deterministic rules, and relying solely on numerous independent intelligent agents would lead to chaos, trapping the system in a “Tower of Babel effect” where agents struggle to understand each other’s roles and responsibilities.
The right direction for the future is to combine traditional deterministic systems with learning intelligent agents, allowing them to handle standardized tasks while also adapting to dynamically changing scenarios. As agents continuously learn from execution results and human interventions, more business processes will be automated, leading to significant productivity gains.
Looking Ahead to 2025 and the Future of Intelligent Agent AI
Finally, let us look forward to 2025 and beyond.

As previously mentioned, 2025 may witness a wave of “agent washing.” Many vendors will package single agents or lightweight AI solutions as complete intelligent agent systems, but in-depth analysis will reveal that this is merely a preliminary attempt. Although some vendors claim that intelligent agent AI will be widely applied by 2025, in reality, this evolution will still require a long time. This is not a short-term trend but a process that needs years of accumulation. While some initial applications may emerge in 2025, true transformation may take 2 to 10 years to unfold fully.
A major concern is that vendors may develop proprietary intelligent agents within their application silos, leading to further fragmentation and turning this round of technological transformation into yet another unfulfilled industry promise. In the past, attempts such as Customer 365, certain data warehouse initiatives, and the Big Data craze have failed to fully realize their original visions. Although cloud computing has succeeded in terms of performance, many data-related promises remain unfulfilled or only partially realized. The current risk is that the industry may simply add intelligent agents to existing traditional architectures rather than genuinely restructuring the architecture. This approach is essentially just “paving the cow paths” and will not bring about true transformation.
The real opportunity lies in reinventing the application stack rather than maintaining the status quo. While industry leaders like Andy Jassy and Satya Nadella recognize the necessity for change, they also acknowledge that this process is fraught with challenges and uncertainties. To achieve a tenfold increase in productivity driven by intelligent agents, the key lies in constructing end-to-end business processes, ensuring that intelligent agents and humans can collaborate efficiently and operate within a unified business logic framework.
Different vendors are adopting different strategies. Cloud computing giants are advancing their respective plans, while data platforms like Snowflake and Databricks are actively positioning themselves, and enterprise application vendors (such as ServiceNow, Salesforce, Oracle, and SAP) are exploring their own paths. At the same time, intelligent agent startups are attracting significant investment. The key question is whether these emerging companies will help integrate the software stack or create new silos.
Therefore, the industry must avoid skipping critical steps and instead focus on building new infrastructure layers to achieve true business logic coordination. Although realizing this vision will take time, if the industry can concentrate on filling the critical gaps in the current architecture and driving its implementation, then the productivity revolution promised by the era of intelligent agents may truly be realized.
References: Vellante, D., & Gilbert, G. (2024, December 21). Breaking Analysis | The Yellow Brick Road to Agentic AI. The Cube Research. https://thecuberesearch.com/260-breaking-analysis-the-yellow-brick-road-to-agentic-ai/
—【End of Article】—
Recently Popular Articles:
-
Breaking Through the Memory Wall: The Evolution of DRAM Technology and the 3D DRAM Revolution -
11 Industry Leaders Look Ahead to 2025: Key Trends in Data Infrastructure -
The “Capability” Challenge of HPC-AI Storage Systems: Considerations Beyond Performance -
AI-Driven Data Storage Transformation: Five Trend Outlooks for 2025 -
[Meta] Tectonic File System: Efficiency Optimization at Massive Scale (Paper)
For more communication, please add me on WeChat
(Please include your Chinese name/company/field of interest)
