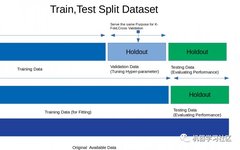
In any supervised machine learning project, the purpose of training a model is to learn the optimal values of weights and biases from labeled examples.
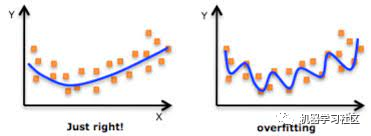
If we use the same labeled examples to test our model, it would be a methodological error, as a model that simply repeats the labels of the samples it has just seen will achieve perfect scores but will not be able to predict anything useful—future data. This situation is known as overfitting.
To overcome the problem of overfitting, we use cross-validation. So, what is cross-validation? And how does it address the issue of overfitting?
What Is Cross-Validation?
Cross-validation is a statistical method used to estimate the performance of machine learning models. It is a way to assess how the results of statistical analyses generalize to an independent dataset.
How Does It Solve the Overfitting Problem?
In cross-validation, we generate multiple small training-test splits from the training data and use these splits to tune your model. For example, in standard k-fold cross-validation, we divide the data into k subsets. We then iterate the training algorithm on k-1 subsets while using the remaining subset as the test set. This way, we can test our model on data that was not involved in training.In this article, I will share 7 commonly used cross-validation techniques along with their advantages and disadvantages. I will also provide code snippets for each technique, encouraging you to bookmark and study them, and please like and support.The following techniques are listed:
- HoldOut Cross-Validation
- K-Fold Cross-Validation
- Stratified K-Fold Cross-Validation
- Leave P Out Cross-Validation
- Leave-One-Out Cross-Validation
- Monte Carlo (Shuffle-Split)
- Time Series (Rolling Cross-Validation)
1. HoldOut Cross-Validation
In this cross-validation technique, the entire dataset is randomly split into a training set and a validation set. Empirically, about 70% of the entire dataset is used as the training set, and the remaining 30% is used as the validation set.
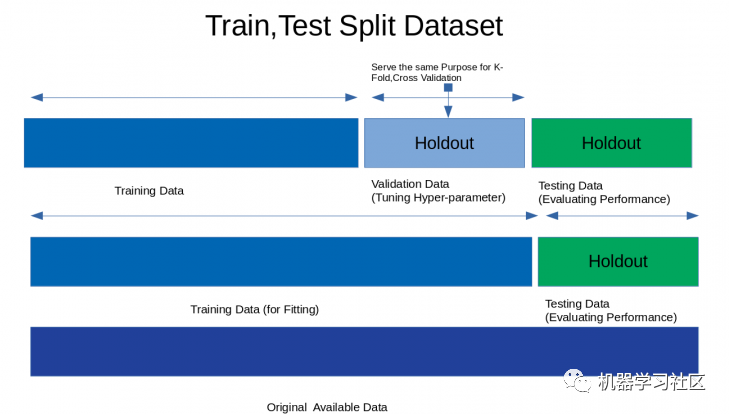
Advantages:1. Quick execution: Because we only need to split the dataset into a training set and a validation set once, and the model will only be built once on the training set, it can be executed quickly.Disadvantages:1. Not suitable for imbalanced datasets: Suppose we have an imbalanced dataset with classes “0” and “1”. Assume 80% of the data belongs to class “0” and the remaining 20% belongs to class “1”. When training with a training set size of 80% and a test size of 20%, it is possible that all 80% of the class “0” data is in the training set, while all the data of class “1” is in the test set. Therefore, our model cannot generalize well to our test data because it has never seen data from class “1”; 2. Large amounts of data cannot train the model. In the case of a small dataset, retaining a portion for testing may miss important features that our model could have learned from the data.Code snippet:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
iris=load_iris()
X=iris.data
Y=iris.target
print("Size of Dataset {}".format(len(X)))
logreg=LogisticRegression()
x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=42)
logreg.fit(x_train,y_train)
predict=logreg.predict(x_test)
print("Accuracy score on training set is {}".format(accuracy_score(logreg.predict(x_train),y_train)))
print("Accuracy score on test set is {}".format(accuracy_score(predict,y_test)))

2. K-Fold Cross-Validation
In this K-Fold cross-validation technique, the entire dataset is divided into K equal-sized parts. Each partition is called a “fold”. Therefore, since we have K parts, we call it K-fold. One fold is used as the validation set, and the remaining K-1 folds are used as the training set.This technique is repeated K times until each fold is used as the validation set, and the remaining folds are used as the training set.The final accuracy of the model is calculated by taking the average accuracy of k models on the validation data.
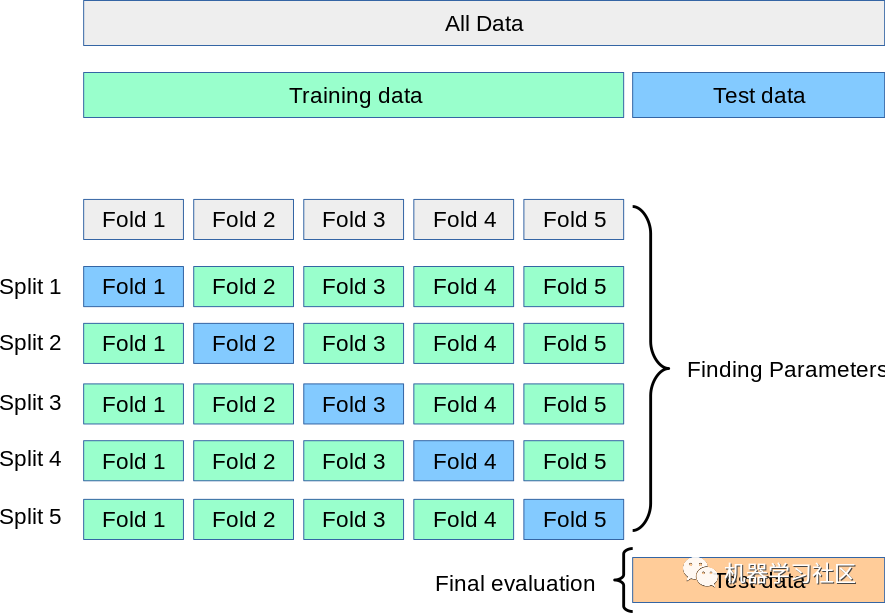
Advantages:1. The entire dataset is used as both the training set and the validation set.Disadvantages:1. Not suitable for imbalanced datasets: As discussed in the case of HoldOut cross-validation, the training set may contain all samples of one class “1”, while the validation set will have samples of class “0”; 2. Not suitable for time series data: The order of samples is crucial for time series data. However, in K-Fold cross-validation, samples are selected in random order.Code snippet:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,KFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
logreg=LogisticRegression()
kf=KFold(n_splits=5)
score=cross_val_score(logreg,X,Y,cv=kf)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))

3. Stratified K-Fold Cross-Validation
Stratified K-Fold is an enhanced version of K-Fold cross-validation, mainly used for imbalanced datasets. Like K-Fold, the entire dataset is divided into K equal-sized folds.However, in this technique, each fold will have the same ratio of target variable instances as the entire dataset.
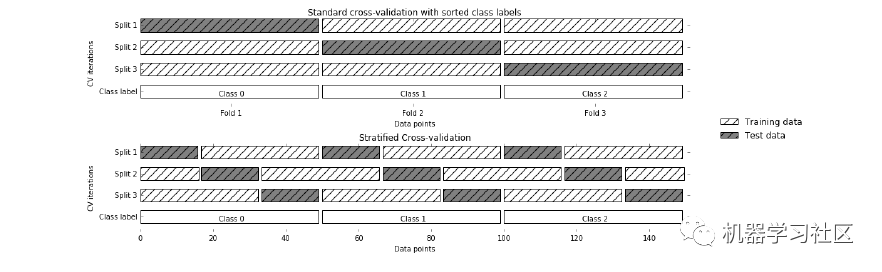
Advantages:1. Very effective for imbalanced data: Each fold in stratified cross-validation represents all categories of data in the same ratio as in the entire dataset.Disadvantages:1. Not suitable for time series data: For time series data, the order of samples is crucial. However, in stratified cross-validation, samples are selected in random order.Code snippet:
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score,StratifiedKFold
from sklearn.linear_model import LogisticRegression
iris=load_iris()
X=iris.data
Y=iris.target
logreg=LogisticRegression()
stratifiedkf=StratifiedKFold(n_splits=5)
score=cross_val_score(logreg,X,Y,cv=stratifiedkf)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))

4. Leave P Out Cross-Validation
Leave P Out cross-validation is a comprehensive cross-validation technique where p samples are used as the validation set, and the remaining n-p samples are used as the training set.Assuming we have 100 samples in the dataset. If we use p=10, then in each iteration, 10 values will be used as the validation set, and the remaining 90 samples will be used as the training set.This process is repeated until the entire dataset is partitioned into p samples and n-p training samples.Advantages:1. All data samples are used as training and validation samples.Disadvantages:1. Long computation time: Since the above technique is repeated until all samples are used as the validation set, the computation time will be longer; 2. Not suitable for imbalanced datasets: Similar to K-Fold cross-validation, if we only have samples of one class in the training set, our model will not generalize to the validation set.Code snippet:
from sklearn.model_selection import LeavePOut,cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
iris=load_iris()
X=iris.data
Y=iris.target
lpo=LeavePOut(p=2)
lpo.get_n_splits(X)
tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(tree,X,Y,cv=lpo)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))

5. Leave-One-Out Cross-Validation
Leave-One-Out cross-validation is a comprehensive cross-validation technique where 1 sample point is used as the validation set, and the remaining n-1 samples are used as the training set.Assuming we have 100 samples in the dataset. Then in each iteration, 1 value will be used as the validation set, and the remaining 99 samples will be used as the training set. Thus, this process is repeated until every sample in the dataset is used as a validation point.It is the same as LeavePOut cross-validation with p=1.
Code snippet:
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import LeaveOneOut,cross_val_score
iris=load_iris()
X=iris.data
Y=iris.target
loo=LeaveOneOut()
tree=RandomForestClassifier(n_estimators=10,max_depth=5,n_jobs=-1)
score=cross_val_score(tree,X,Y,cv=loo)
print("Cross Validation Scores are {}".format(score))
print("Average Cross Validation score :{}".format(score.mean()))
6. Monte Carlo Cross-Validation (Shuffle Split)
Monte Carlo cross-validation, also known as Shuffle Split cross-validation, is a very flexible cross-validation strategy. In this technique, the dataset is randomly divided into training and validation sets.We have determined the percentage of the dataset to be used as the training set and the percentage to be used as the validation set. If the total percentage of the training and validation set sizes does not equal 100, the remaining dataset will not be used for either the training or validation set.Assuming we have 100 samples, where 60% of the samples are used as the training set and 20% are used as the validation set, then the remaining 20% (100-(60+20)) will not be used.This split will be repeated the number of times we must specify.

Advantages:1. We can freely choose the sizes of the training and validation sets; 2. We can choose the number of repetitions without relying on the number of folds to repeat.Disadvantages:1. May not select very few samples for the training or validation set; 2. Not suitable for imbalanced datasets: After we define the sizes of the training and validation sets, all samples are randomly selected, so the training set may not contain data categories that appear in the test set, and the model will not generalize to unseen data.Code snippet:
from sklearn.model_selection import ShuffleSplit,cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
logreg=LogisticRegression()
shuffle_split=ShuffleSplit(test_size=0.3,train_size=0.5,n_splits=10)
scores=cross_val_score(logreg,iris.data,iris.target,cv=shuffle_split)
print("cross Validation scores:n {}".format(scores))
print("Average Cross Validation score :{}".format(scores.mean()))

7. Time Series Cross-Validation
What Is Time Series Data?Time series data is data collected at different time points. Since the data points are collected at adjacent time periods, there may be correlations between observations. This is one of the characteristics that distinguishes time series data from cross-sectional data.How to Perform Cross-Validation on Time Series Data?In the case of time series data, we cannot randomly select samples and assign them to the training or validation set, as it makes no sense to use values from future data to predict values from past data.Since the order of data is crucial for time series-related issues, we split the data into training and validation sets based on time, also known as the “forward chaining” method or rolling cross-validation.We start with a small portion of the data as the training set. Based on that set, we predict later data points and check accuracy.Then the predicted samples are included as part of the next training dataset, and predictions are made for subsequent samples.
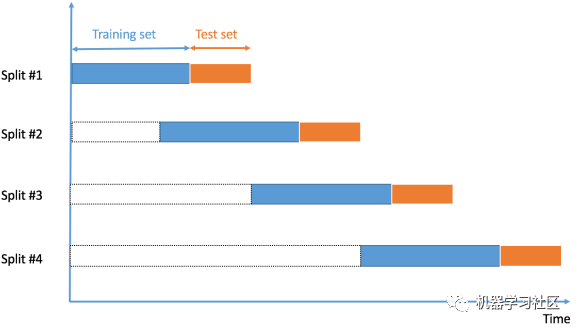
Advantages:1. One of the best techniques.Disadvantages:1. Not suitable for validation of other data types: Like other techniques, we select random samples as training or validation sets, but in this technique, the order of the data is very important.Code snippet:
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
time_series = TimeSeriesSplit()
print(time_series)
for train_index, test_index in time_series.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
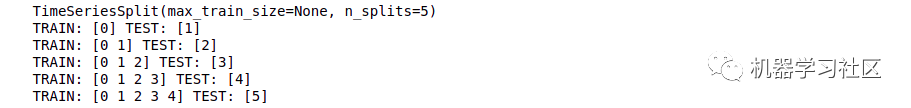
Conclusion
In this article, I aimed to outline how various cross-validation techniques work and what we should keep in mind when implementing these techniques. I sincerely hope this is helpful in your data science journey.