
1
1958: The Rise of the Perceptron
In 1958, Frank Rosenblatt invented the perceptron, a very simple machine model that later became the core and origin of today’s intelligent machines.
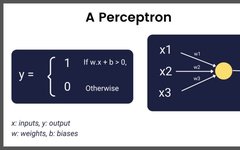
The perceptron is a very simple binary classifier that can determine whether a given input image belongs to a given class. To achieve this, it uses a unit step activation function. Using the unit step activation function, if the input is greater than 0, the output is 1; otherwise, it is 0.
The following image shows the algorithm of the perceptron.
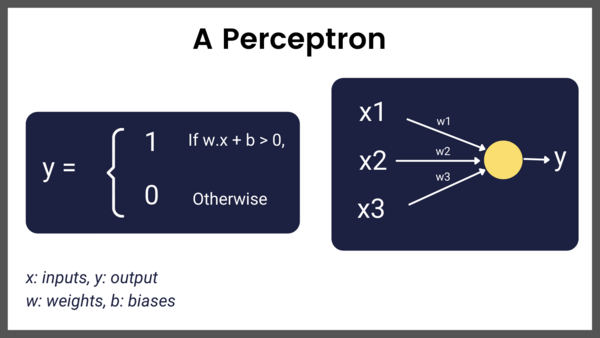
Perceptron
Frank’s intention was not to build the perceptron as an algorithm, but as a machine. The perceptron was implemented in hardware called the Mark I Perceptron. The Mark I Perceptron was a purely electric machine. It had 400 photoelectric tubes (or photodetectors), whose weights were encoded into potentiometers, and the weight updates (which occur during backpropagation) were executed by motors. The following image shows the Mark I Perceptron.

Mark I Perceptron. Image from the National Museum of American History
Just like the news you see today about neural networks, the perceptron was also headline news at the time. The New York Times reported, “[The Navy] expects the initial models of electronic computers to walk, talk, observe, write, self-replicate, and be aware of their existence.” Today, we all know that machines still struggle to walk, talk, observe, write, replicate themselves, and consciousness is another matter entirely.
The goal of the Mark I Perceptron was simply to recognize images, and at that time it could only recognize two categories. It took some time for people to realize that adding more layers (the perceptron is a single-layer neural network) could enable the network to learn complex functions. This further led to the development of multilayer perceptrons (MLPs).
2
1982-1986: Recurrent Neural Networks (RNNs)
After multilayer perceptrons demonstrated the potential to solve image recognition problems, people began to think about how to model sequential data such as text.
Recurrent neural networks are a class of neural networks designed to process sequences. Unlike feedforward networks like multilayer perceptrons (MLPs), RNNs have an internal feedback loop responsible for remembering the information state at each time step.
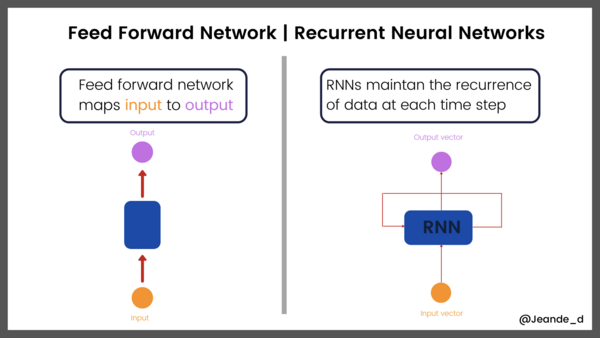
Feedforward Networks vs Recurrent Neural Networks
The first RNN unit was discovered between 1982 and 1986, but it did not attract much attention because simple RNN units were significantly affected when used with long sequences, mainly due to short memory and unstable gradient problems.
3
1998: LeNet-5, The First CNN Architecture
LeNet-5 is one of the earliest convolutional network architectures, used for document recognition in 1998. LeNet-5 consists of three parts: two convolutional layers, two subsampling or pooling layers, and three fully connected layers. There are no activation functions in the convolutional layers.
As stated in the paper, LeNet-5 has been commercialized and reads millions of checks daily. Below is the architecture of LeNet-5. This image is taken from its original paper.
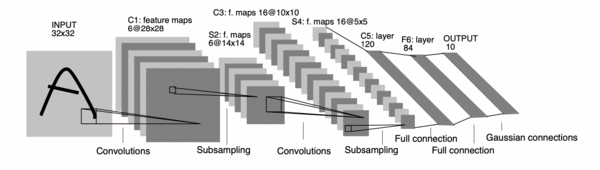
LeNet-5 was indeed an influential study at the time, but it (the conventional convolutional network) did not gain attention until 20 years later! LeNet-5 was built on early work, such as the first convolutional neural network proposed by Kunihiko Fukushima, backpropagation (Hinton et al., 1986), and backpropagation applied to handwritten postal code recognition (LeCun et al., 1989).
4
1998: Long Short-Term Memory (LSTM)
Due to gradient instability issues, simple RNN units could not handle long sequence problems. LSTMs are a version of RNNs that can handle long sequences. LSTMs are essentially extreme cases of RNN units.
One special design difference of LSTM units is that they have a gating mechanism, which is the basis for controlling the flow of information across multiple time steps.
In short, LSTMs use gates to control the flow of information from the current time step to the next time step in the following four ways:
-
The input gate identifies the input sequence. -
The forget gate removes all irrelevant information contained in the input sequence and stores relevant information in long-term memory. -
The LSTM unit updates the state value of the “update unit”. -
The output gate controls the information that must be sent to the next time step.
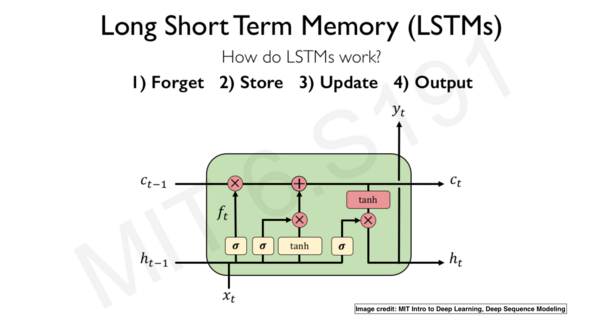
LSTM Architecture. Image taken from MIT’s course “6.S191 Introduction to Deep Learning”
The ability of LSTMs to handle long sequences makes them suitable neural network architectures for various sequential tasks, such as text classification, sentiment analysis, speech recognition, image captioning, and machine translation.
LSTMs are a powerful architecture, but they have high computational costs. The GRU (Gated Recurrent Unit) introduced in 2014 can address this issue. Compared to LSTMs, GRUs have fewer parameters and perform well.
5
2012: ImageNet Competition, The Rise of AlexNet and ConvNets
It would be nearly impossible to discuss the history of neural networks and deep learning without mentioning the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) and AlexNet.
The sole goal of the ImageNet competition was to evaluate image classification and object detection architectures on large datasets. It brought many new, powerful, and interesting visual architectures.
The competition began in 2010, but it changed in 2012 when AlexNet won with a Top-5 error rate of 15.3%, nearly half of the previous winners’ error rates. AlexNet consists of five convolutional layers, followed by max pooling layers, three fully connected layers, and a Softmax layer. AlexNet proposed the idea that deep convolutional neural networks could handle visual recognition tasks well. However, at that time, this idea had not yet penetrated other applications!
In the following years, ConvNet architectures continued to grow larger and perform better. For example, VGG with 19 layers won the challenge with a 7.3% error rate. GoogLeNet (Inception-v1) went further, reducing the error rate to 6.7%. In 2015, ResNet (Deep Residual Networks) expanded on this, lowering the error rate to 3.6% and showing that through residual connections, we could train deeper networks (over 100 layers), which was previously impossible. It was found that deeper networks performed better, leading to the emergence of other new architectures such as ResNeXt, Inception-ResNet, DenseNet, Xception, and more.
Readers can find a summary and implementation of these architectures and other modern architectures here: https://github.com/Nyandwi/ModernConvNets
ModernConvNets Library
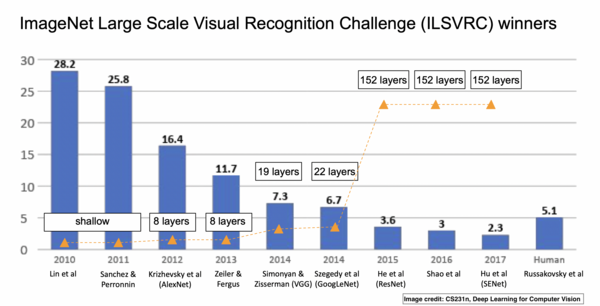
ImageNet Competition. Image from the course “CS231n”
6
2014: Deep Generative Networks
Generative networks are used to generate or synthesize new data samples, such as images and music, from training data.
There are many types of generative networks, but the most popular is the Generative Adversarial Network (GAN) created by Ian Goodfellow in 2014. GAN consists of two main components: a generator that generates fake samples and a discriminator that distinguishes between real samples and samples generated by the generator. The generator and discriminator can be said to be in a competitive relationship. They are both trained independently, and during training, they play a zero-sum game. The generator continuously generates fake samples that deceive the discriminator, while the discriminator strives to identify those fake samples (referencing real samples). In each training iteration, the generator gets better at generating samples that are close to real, while the discriminator must raise its standards to distinguish between fake and real samples.
GANs have been one of the hottest research topics in the deep learning community, known for generating fake images and Deepfake videos. If readers are interested in the latest developments in GANs, they can read introductions to StyleGAN2, DualStyleGAN, ArcaneGAN, and AnimeGANv2. For a complete list of GAN resources: https://github.com/nashory/gans-awesome-applications.
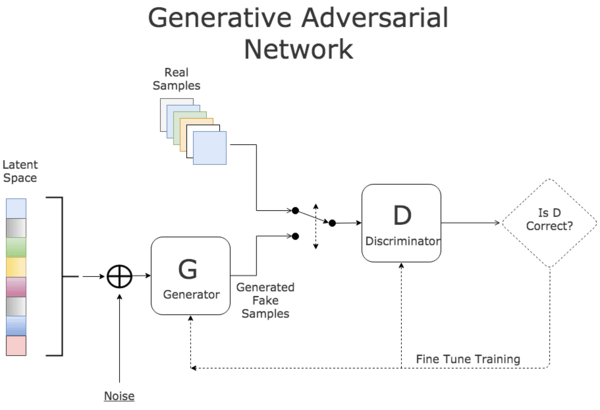
Generative Adversarial Network (GAN)
GAN is a type of generative model. Other popular types of generative models include Variational Autoencoders (VAEs), Autoencoders, and diffusion models.
7
2017: Transformers and Attention Mechanisms
Fast forward to 2017. The ImageNet competition has concluded. New convolutional network architectures have also been created. Everyone in the computer vision community was excited about the current progress. Core computer vision tasks (image classification, object detection, image segmentation) were no longer as complex as before. People could use GANs to generate realistic images.
NLP seemed to be lagging behind. But then something happened and became headline news across the network: a completely new neural network architecture based solely on attention mechanisms emerged. And NLP was inspired again, with attention mechanisms continuing to dominate other directions (most notably visual) in the following years. This architecture is called the Transformer.
In the five years since then, we are now talking about this greatest innovation. Transformers are a class of neural network algorithms purely based on attention mechanisms. Transformers do not use recurrent networks or convolutions. They consist of multi-head attention, residual connections, layer normalization, fully connected layers, and positional encoding to retain the sequence order in the data. The following image illustrates the Transformer architecture.

Image from “Attention Is All You Need”
Transformers have revolutionized NLP, and they are currently also transforming the field of computer vision. In the field of NLP, they are used for machine translation, text summarization, speech recognition, text completion, document search, and more.
Readers can learn more about Transformers in their paper “Attention is All You Need”.
8
2018-Present
Since 2017, deep learning algorithms, applications, and technologies have advanced rapidly. For clarity, the later introductions are categorized. In each category, we will revisit major trends and some of the most important breakthroughs.
Vision Transformers
Shortly after Transformers demonstrated excellent performance in NLP, some innovators eagerly applied attention mechanisms to the image domain. In the paper “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale,” several researchers from Google showed that slight modifications to the standard Transformer running directly on sequences of image patches could yield substantial results on image classification datasets. They called this architecture the Vision Transformer (ViT), which performs well on most computer vision benchmark tests (as of the writing of this article, ViT is the state-of-the-art classification model on Cifar-10).
The designers of ViT were not the first to attempt using attention mechanisms in recognition tasks. The first record of using attention mechanisms can be found in the paper Attention Augmented Convolutional Networks, which attempted to combine self-attention mechanisms with convolutions (moving away from convolutions mainly due to the spatial inductive bias introduced by CNNs).
Another example can be found in the paper Visual Transformers: Token-based Image Representation and Processing for Computer Vision, which runs Transformers on filter-based tokens or visual tokens.
These two papers and many others not listed here broke some baseline architectures (mainly ResNet) but did not surpass current benchmarks at the time. ViT is indeed one of the greatest papers. One of the most important insights of this paper is that the ViT designers actually used image patches as input representations. They did not make significant changes to the Transformer architecture.
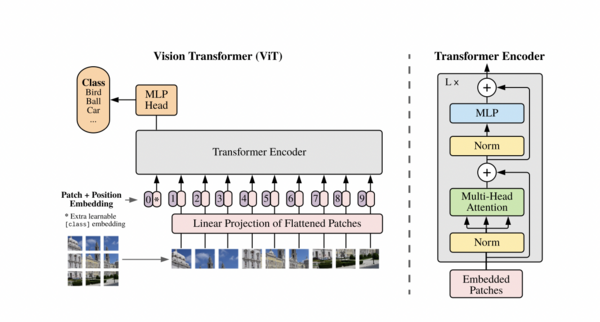
Vision Transformer (ViT)
Besides using image patches, what makes the Vision Transformer a powerful architecture is the Transformer’s super parallelism and its scaling behavior. But like everything in life, nothing is perfect. Initially, ViT performed poorly on visual downstream tasks (object detection and segmentation).
After the introduction of Swin Transformers, Vision Transformers began to be used as backbone networks for visual downstream tasks such as object detection and image segmentation. The core highlight of Swin Transformer’s superior performance is due to the use of shifted windows between successive self-attention layers. The following image describes the differences between Swin Transformer and Vision Transformer (ViT) in building hierarchical feature maps.

Image from the original Swin Transformer paper
The Vision Transformer has been one of the most exciting areas of research recently. Readers can learn more in the paper “Transformers in Vision: A Survey.” Other recent visual Transformers include CrossViT, ConViT, and SepViT.
Visual and Language Models
Visual and language models are often referred to as multimodal. They are models that involve both vision and language, such as text-to-image generation (given text, generate an image that matches the text description), image captioning (given an image, generate its description), and visual question answering (given an image and a question about the content in the image, generate an answer). To a large extent, the success of Transformers in the visual and language domains has contributed to multimodal as a single unified network.
In fact, all visual and language tasks leverage pre-training techniques. In computer vision, pre-training requires fine-tuning networks trained on large datasets (usually ImageNet), while in NLP, it often involves fine-tuning pre-trained BERT models. To learn more about pre-training in V-L tasks, readers can refer to the paper “A Survey of Vision-Language Pre-Trained Models.” For a general overview of visual and language tasks and datasets, see the paper “Trends in Integration of Vision and Language Research: A Survey of Tasks, Datasets, and Methods.”
Recently, OpenAI released DALL·E 2 (an improved version of DALL·E), a visual-language model that can generate realistic images based on text. There are many existing text-to-image models, but DALL·E 2 excels in resolution, image caption matching, and realism.
DALL·E 2 has not yet been made public, and here are some examples of images created by DALL·E 2.

The images generated by DALL·E 2 presented above were created by some OpenAI employees, such as @sama, @ilyasut, @model_mechanic, and openaidalle.
Large Language Models (LLMs)
Language models have various uses. They can be used to predict the next word or character in a sentence, summarize a document, translate given text from one language to another, recognize speech, or convert a piece of text into speech.
Jokingly, the inventors of Transformers must be blamed for the progress of language models toward large-scale parameterization (but in reality, no one should be blamed; Transformers are one of the greatest inventions of the past decade, and the astonishing thing about large models is that: given enough data and computation, they always perform better). Over the past five years, the size of language models has been continuously increasing.
A year after the introduction of the paper “Attention is all you need,” large language models began to emerge. In 2018, OpenAI released GPT (Generative Pre-trained Transformer), which was one of the largest language models at the time. A year later, OpenAI released GPT-2, a model with 1.5 billion parameters. Another year later, they released GPT-3, which has 175 billion parameters and was trained on 570GB of text. This model has 175B parameters and is 700GB in size. According to lambdalabs, training GPT-3 using the cheapest GPU cloud available on the market would take 366 years and cost 4.6 million dollars!
The GPT-n series models are just the beginning. There are other larger models approaching or even exceeding the size of GPT-3. For example, NVIDIA’s Megatron-LM has 8.3B parameters; the latest DeepMind Gopher has 280B parameters. On April 12, 2022, DeepMind released another language model called Chinchilla with 70B parameters. Although smaller than Gopher, GPT-3, and Megatron-Turing NLG (530B parameters), its performance surpasses many language models. Chinchilla’s paper indicates that existing language models are undertrained, specifically stating that if the model size is doubled, the data should also be doubled. However, almost in the same week, the Google Pathways Language Model (PaLM) emerged with 540 billion parameters!
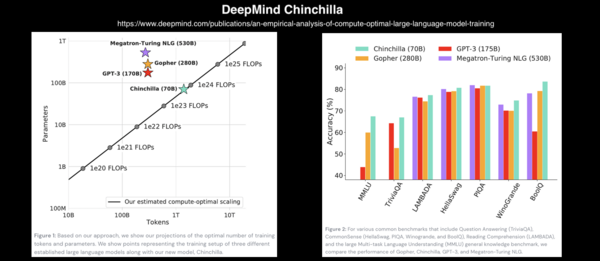
Chinchilla Language Model
Code Generation Models
Code generation is a task that involves completing given code or generating code based on natural language or text, or simply put, it is an AI system that can write computer programs. It can be confidently said that people have started to consider letting computers write their own programs (just like we dream of teaching computers to do everything else), but code generators gained attention after OpenAI released Codex.
Codex is a fine-tuned version of GPT-3 trained on public repositories on GitHub and other public source code. OpenAI states: “OpenAI Codex is a general-purpose programming model, which means it can basically be applied to any programming task (although results may vary). We have successfully used it for compiling, interpreting, and refactoring code. But we know we have only scratched the surface of what can be done.” Currently, GitHub Copilot, powered by Codex, plays the role of a pair programmer.
After using Copilot, I was very surprised by its capabilities. As someone who does not write Java programs, I used it to prepare for my mobile application (using Java) exam. It was so cool to have AI help me prepare for an academic exam!
Months after OpenAI released Codex, DeepMind released AlphaCode, a language model based on Transformers that can solve competitive programming problems. A blog post about AlphaCode stated: “AlphaCode ranks in the top 54% of participants in programming competitions by solving problems that require combining critical thinking, logic, algorithms, coding, and natural language understanding.” Solving programming problems (or general competitive programming) is very difficult (anyone who has done a technical interview agrees), and as Dzmitry said, beating “human level is still a long way off.”
Recently, scientists from Meta AI released InCoder, a generative model that can generate and edit programs. More papers and models related to code generation can be found here: https://paperswithcode.com/task/code-generation/codeless
Back to the Perceptron
For a long time before the rise of convolutional neural networks and Transformers, deep learning revolved around the perceptron. ConvNets have shown excellent performance in various recognition tasks, replacing MLPs. Vision Transformers are currently also showing promise as an architecture. But has the perceptron completely died? The answer may be no.
In July 2021, researchers published two papers based on perceptrons. One is MLP-Mixer: An all-MLP Architecture for Vision, and the other is Pay Attention to MLPs (gMLP).
MLP-Mixer claims that neither convolutions nor attention are necessary. This paper achieved high accuracy on image classification datasets using only multilayer perceptrons (MLPs). An important highlight of MLP-Mixer is that it contains two main MLP layers: one applied independently to image patches (channel mixing) and another applied across layers (spatial mixing).
gMLP also shows that high accuracy can be achieved in various image recognition and NLP tasks by avoiding the use of self-attention and convolutions (the practical usage in current NLP and CV).

Readers will obviously not use MLPs to achieve state-of-the-art performance, but their comparability with state-of-the-art deep networks is indeed fascinating.
Using Convolutional Networks Again: Convolutional Networks of the 2020s
Since the introduction of Vision Transformers (2020), research in computer vision has revolved around Transformers (in the NLP field, Transformers have already become the norm). Vision Transformers (ViT) achieved state-of-the-art results in image classification, but performed poorly in visual downstream tasks (object detection and segmentation). With the launch of Swin Transformers, Vision Transformers quickly took over visual downstream tasks as well.
Many people (including myself) love convolutional neural networks. Convolutional neural networks do work, and it is hard to give up something that has proven effective. This love for the architecture of deep network models has led some outstanding scientists to return to the past and explore how to modernize convolutional neural networks (specifically ResNet) to have the same appealing features as Vision Transformers. In particular, they explored the question, “How do design decisions in Transformers affect the performance of convolutional neural networks?” They wanted to apply the secrets that shaped Transformers to ResNet.
Meta AI’s Saining Xie and his colleagues adopted the roadmap they explicitly stated in their paper, ultimately forming a ConvNet architecture called ConvNeXt. ConvNeXt achieved results comparable to Swin Transformer in various benchmark tests. Readers can learn more about the roadmap they adopted through the ModernConvNets library (a summary and implementation of modern CNN architectures).
9
Conclusion
Deep learning is a very vibrant and broad field, making it difficult to summarize everything that has happened. The author has only scratched the surface, and there are so many papers that one person cannot read them all, making it hard to track everything. For example, we have not discussed reinforcement learning and deep learning algorithms, such as AlphaGo and protein folding AlphaFold (one of the biggest scientific breakthroughs), the evolution of deep learning frameworks (like TensorFlow and PyTorch), and deep learning hardware. Perhaps there are many other important things that make up a significant part of the history, algorithms, and applications of deep learning that we have not discussed.
As a small disclaimer, readers may have noticed that the author leans towards deep learning in computer vision, and may not have covered other important deep learning techniques specifically designed for NLP.
Furthermore, it is difficult to know exactly when a particular technology was published or who published it first, as most novel things are often inspired by previous works. If there are any discrepancies, readers can discuss them with the author in the comments section of the original text.
(Original link:
https://www.getrevue.co/profile/deeprevision/issues/a-revised-history-of-deep-learning-issue-1-1145664)
This article is reprinted from WeChat public account: Machine Heart.
More exciting:
Yan Shi│Reflections and Suggestions on the “Predicament” of Young Teachers in Colleges and Universities
Academician Zheng Weimin: Why Computer Science Majors Have Become a Hot Choice for Candidates
[Directory] Computer Education, Issue 4, 2022
[Directory] Computer Education, Issue 3, 2022
[Directory] Computer Education, Issue 2, 2022
[Directory] Computer Education, Issue 1, 2022
[Editorial Board Message] Professor Li Xiaoming of Peking University: Reflections on the “Year of Classroom Teaching Improvement”…
Professor Chen Daoxu of Nanjing University: Which is more important, teaching students to ask questions or teaching students to answer questions?
[Yan Shi Series]: Development Trends of Computer Disciplines and Their Impact on Computer Education
Professor Li Xiaoming of Peking University: From Fun Mathematics to Fun Algorithms to Fun Programming—A Path for Non-specialist Learners to Experience Computational Thinking?
Reflections on Several Issues in Building First-class Computer Disciplines
Professor Liu Yunhao of Tsinghua University Answers 2000 Questions about AI
Professor Zhan Dechen of Harbin Institute of Technology: A New Model for Ensuring Teaching Quality in Colleges and Universities—Synchronous and Asynchronous Blended Teaching
[Principal Interview] Accelerating the Advancement of Computer Science Education—An Interview with Professor Zhou Aoying, Vice President of East China Normal University
New Engineering and Big Data Major Construction
Other countries’ stones can help to attack jade—A Compilation of Research Articles on Computer Education at Home and Abroad