Author: Artem Shelamanov
Translator: Chen Zhiyan
Proofreader: Zhao Ruxuan
This article is about 2800 words long, recommended reading time is 5 minutes.
This article introduces machine learning libraries, and once you master the model architectures, you can train models to solve real-world problems.
If you are a junior or mid-level machine learning engineer or data scientist, this article is very suitable for you. Once you have selected your preferred machine learning libraries, such as PyTorch or TensorFlow, and mastered the model architectures, you can train models to solve real-world problems.
In this blog post, I will introduce five Python libraries that I believe every machine learning engineer and data scientist should be familiar with, which will be a valuable addition to your skill set. By simplifying the machine learning development process, it makes you a more competitive candidate.
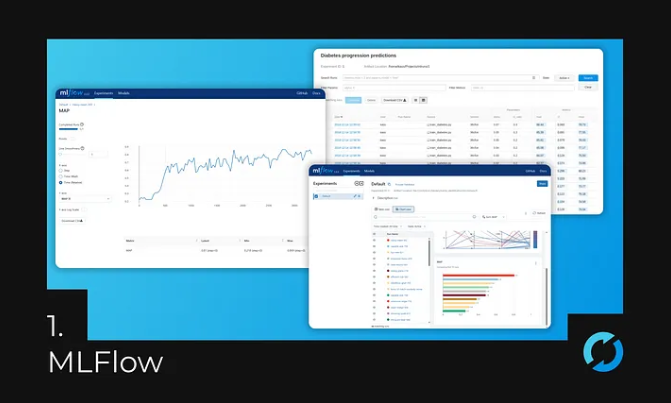
1. MLFlow — Experiment and Model Tracking
Image source: Author, example from https://mlflow.org
Imagine you are a machine learning developer working on a project to build a customer churn prediction model. You need to use a Jupyter notebook to explore the data and try different algorithms and hyperparameters. As the project progresses, the notebook becomes increasingly complex, filled with code, results, and visualizations, making it more challenging to track project progress and identify what works and what doesn’t.
At this point, MLflow comes into play. MLflow is a platform that helps manage machine learning experiments from start to finish, ensuring traceability and reproducibility. It provides a centralized repository for storing code, data, and model components, as well as a tracking system that records all experiment details, including hyperparameters, metrics, and outputs.
MLflow helps you avoid the pitfalls of using Jupyter notebooks by:
1. Centralized Repository: MLflow keeps your code, data, and model artifacts organized and easily accessible, allowing you to quickly find the resources you need and avoid getting lost in the notebook maze.
2. Experiment Tracking: MLflow records every experiment, including the exact code, data, and hyperparameters used. This allows you to easily compare different experiments and identify the factors that lead to the best results.
3. Reproducibility: MLflow makes it possible to reproduce the best models using the same code, data, and environment. This is crucial for ensuring consistency and reliability in experimental results.
So, if you want to build effective machine learning models, ditch the chaos of Jupyter notebooks and embrace the power of MLflow.
2. Streamlit — Small and Fast Web Applications
Streamlit is the most popular front-end framework among data scientists. It is an open-source Python framework that allows users to quickly and easily create interactive data applications, especially beneficial for data scientists and machine learning engineers without web development background.
With Streamlit, developers can build and share engaging user interfaces and deploy models without needing in-depth front-end experience or knowledge. The framework is free and open-source, making it possible to create shareable web applications in just a few minutes.
If you have small projects involving machine learning, using Streamlit to add a user interface can be done quickly with many ready-made templates, allowing you to complete the front end in minutes. Sharing it is also very easy, making it a highlight of your resume.
If you want to learn about other Python front-end libraries, be sure to check out my article “Top-5 Python Front-End Libraries for Data Science”.
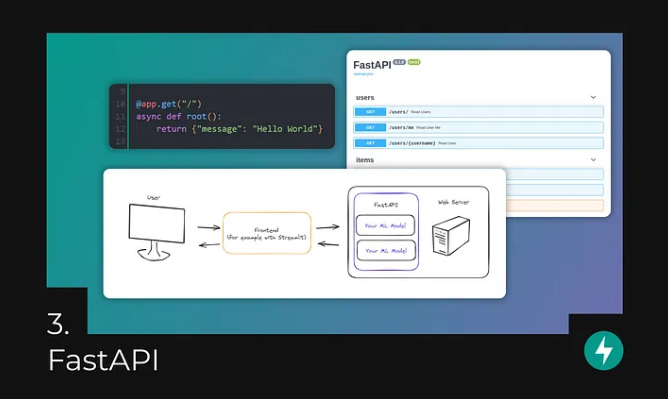
3. FastAPI — Easy and Fast Model Deployment
After training and validating a good model, deployment is necessary so that other applications can use it, which is where FastAPI comes in.
FastAPI is a high-performance web framework for building RESTful APIs, known for its simplicity, ease of use, and speed. This is why it has become an ideal choice for deploying machine learning models to production.
Here are some reasons why ML engineers and data scientists should learn FastAPI:
-
Speed: FastAPI is very fast. It uses modern asynchronous programming models, efficiently handling multiple requests simultaneously, which is crucial for deploying machine learning models that need to process large amounts of data.
-
Simplicity: FastAPI is easy to learn and use. Its syntax is clear and concise, making it easier to write clean and maintainable code, which is important for ML engineers and data scientists without extensive web development experience.
-
Usability: FastAPI offers many features that make building and deploying APIs easy. For example, it has built-in support for automatic documentation, data validation, and error handling, allowing ML engineers to focus on their core work—building and deploying models, saving time and effort.
-
Production-Ready: FastAPI is designed for production, supporting features like multiple backends, encryption, and deployment tools, making it a reliable choice for deploying machine learning models.
In summary, FastAPI is a powerful and versatile tool for deploying machine learning models to production. Its usability, speed, and production readiness make it an ideal choice for ML engineers and data scientists.
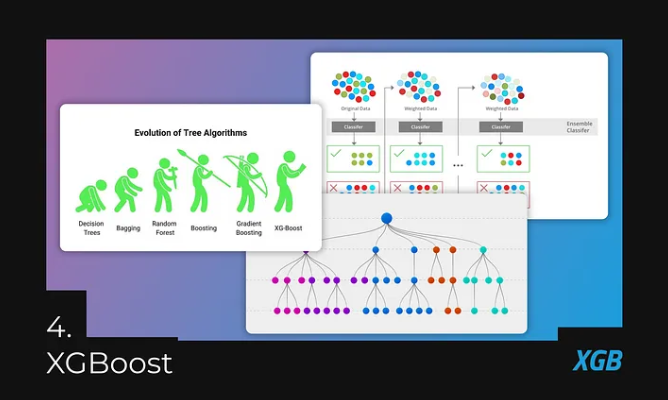
4. XGBoost — Fast and Accurate Predictions for Tabular Data
Image source: Author, source 1 and source 2
XGBoost is a powerful machine learning algorithm known for its accuracy, speed, and scalability. It is based on the gradient boosting framework, combining multiple weak learners into a strong learner. In simple terms, it uses multiple small models, like random forests, combining them into a larger model, resulting in a faster model (compared to neural networks) that is scalable and less prone to overfitting.
Here are some reasons why ML engineers and data scientists should learn XGBoost:
-
Accuracy: XGBoost is one of the most accurate machine learning algorithms, having won many machine learning competitions and consistently ranking high across various tasks.
-
Speed: XGBoost is very fast, capable of training and predicting efficiently on large datasets. This makes it a good choice for applications where speed is paramount (like real-time fraud detection or financial modeling).
-
Scalability: XGBoost is highly scalable. It can handle large datasets and complex models without sacrificing accuracy, making it a great choice for applications with large volumes of data or high model complexity.
If your task involves tabular data (like predicting house prices based on the number of rooms or calculating the likelihood of a customer purchasing a product based on their last purchase/account data), XGBoost is the algorithm you should try first before resorting to neural networks like Keras or PyTorch.
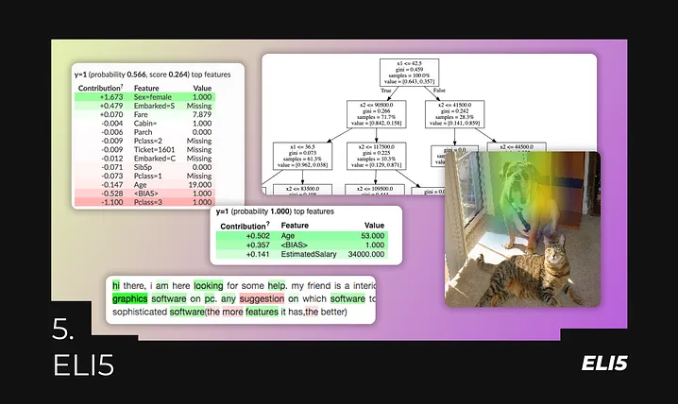
5. ELI5 — Making Models More Interpretable and Transparent
Image source: Author, source 1, source 2
After training a model, it can be deployed for use, at which point the model resembles a “black box”—input something and get an output. How does the model work? No one knows. There are numbers here and there, and it finally produces an answer.
If a client/boss asks you how the model arrived at a particular answer, you would have no idea; you might not even know which parameters were most important during training and which just added noise.
All these questions can be answered using ELI5. This library makes models transparent, interpretable, and easier to understand. It provides more information about the model, data, training process, weight distribution, and input parameters. Additionally, it allows you to “debug” the model and gain insights into what architectures might work better and what issues the current model has.
ELI5 supports many libraries, such as Scikit-Learn, Keras, and XGBoost. Models can be used for classification of image, text, and tabular data.
Conclusion
We explored five leading data science frameworks, and if you master these libraries, you will gain multiple advantages:
1. Compared to other data scientists, you will have more job opportunities because you will have multiple skills across various aspects of machine learning.
2. You will be able to work on full-stack projects, as you can not only develop models but also deploy them using FastAPI and allow users to interact with them through a Streamlit front end.
3. You will not get lost in “Jupyter notebook hell” because all machine learning experiments will be traceable and reproducible through MLFlow, and all models will be properly versioned.
4. Tabular data will not be a problem for you because you know how to use XGBoost to train scalable, fast, and accurate models.
5. Most models will no longer be a “black box” for you because you can gain deeper insights into them, debug their thought processes, and explain their predictions using ELI5.
All these libraries will make your life easier, adding many useful and important skills to your arsenal. Happy coding!
3. https://blog.streamlit.io/building-a-streamlit-and-scikit-learn-app-with-chatgpt/
4. https://fastapi.tiangolo.com
5. https://www.geeksforgeeks.org/xgboost/
6. https://xgboost.readthedocs.io/en/stable/
7. https://github.com/TeamHG-Memex/eli5
8. https://eli5.readthedocs.io/en/latest/overview.html#basic-usage
9. https://www.analyticsvidhya.com/blog/2020/11/demystifying-model-interpretation-using-eli5/
Original Title:
5 Python Libraries Every Data Scientist Should Know About
https://medium.com/python-in-plain-english/5-python-libraries-every-data-scientist-should-know-about-ce04bf19d58d
Chen Zhiyan, graduated with a Master’s degree in Engineering from Beijing Jiaotong University, majoring in Communication and Control Engineering. He has worked as an engineer at Great Wall Computer Software and Systems Company and Datang Microelectronics Company. He is currently a technical support at Beijing Wuyi Chaoqun Technology Co., Ltd. He is engaged in the operation and maintenance of intelligent translation teaching systems and has accumulated experience in artificial intelligence deep learning and natural language processing (NLP). In his spare time, he enjoys translation work, with notable translations including IEC-ISO 7816, Iraq Oil Engineering Project, and New Fiscal Taxism Declaration, among others. His translation of “New Fiscal Taxism Declaration” was officially published in GLOBAL TIMES. He hopes to join the translation volunteer group of THU Data Party platform in his spare time to share and communicate with others for mutual progress.
Recruitment Information for Translation Team
Job Description: A meticulous heart is needed to translate well-selected foreign articles into fluent Chinese. If you are an international student in data science/statistics/computer science, or working overseas in related fields, or confident in your language skills, you are welcome to join the translation team.
What You Will Gain: Regular translation training to improve volunteers’ translation skills, enhance awareness of cutting-edge data science, and allow overseas friends to stay in touch with domestic technological applications. The background of THU Data Party’s industry-university-research collaboration brings good development opportunities for volunteers.
Other Benefits: You will have the chance to work with data scientists from well-known companies and students from top universities such as Peking University, Tsinghua University, and overseas institutions.
Click “Read Original” at the end to join the Data Party team~
Reprint Notice
If you need to reprint, please prominently indicate the author and source at the beginning of the article (Reprinted from: Data Party ID: DatapiTHU) and place a prominent QR code for Data Party at the end of the article. For articles with original identification, please send [Article Name – Pending Authorized Public Account Name and ID] to the contact email to apply for whitelist authorization and edit according to requirements.
After publication, please provide the link feedback to the contact email (see below). Unauthorized reprints and adaptations will be pursued according to legal responsibilities.
Click “Read Original” to embrace the organization