For most data analysts, regression models are undoubtedly one of the fundamental skills. At the beginning of this century, many investment banks used the application of regression models as a standard for evaluating analysts. For over a decade, regression models have maintained a significant presence in all analyses and predictions.
However, in recent years, a research team at the University of Washington developed a new algorithm based on ensemble machine learning with decision trees, using Gradient Boost as its framework. The related paper, once published, caused a stir, winning multiple Kaggle competitions and being applied in various cutting-edge industries.
(Content sourced from the internet)
XGBoost and GBM are both ensemble tree methods that enhance weak learners using gradient descent architecture. However, XGBoost improves upon the basic GBM framework through systematic optimization and algorithm enhancement. Decision trees are algorithms that are easy to visualize and have relatively strong interpretability, but establishing an intuitive understanding of the next-generation algorithm can be somewhat tricky.
So what exactly is XGBoost?XGBoost is similar to GDBT, but differs in the definition of the objective function. The excellence of XGBoost stems from its systematic optimization and algorithmic improvements, refining the foundational GBM framework.

(Content sourced from the internet)
The red arrow points to L, which is the loss function (for example, the logistic loss function: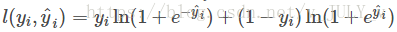 );
);
The red box encloses the regularization term (including L1 regularization and L2 regularization);
The red circle encompasses the constant term;
For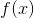 , xgboost uses a Taylor expansion to approximate it;
, xgboost uses a Taylor expansion to approximate it;
We can clearly see that the final objective function only depends on the first and second derivatives of the error function for each data point.
Since XGBoost is so excellent, will linear models (such as linear regression models and logistic regression models) become obsolete?
As researchers in the field of data, we must test all algorithms capable of handling production environment data to determine which is the best. Moreover, merely selecting the correct algorithm is not enough. We must adjust hyperparameters based on the dataset we are working with to choose the appropriate configuration. Additionally, we must consider other factors such as computational complexity, interpretability, and ease of implementation.

Linear models, as foundational models, have been tested and developed over a long time, providing relatively complete functionalities. To a certain extent, they are one of the most practical models in production environments—simple, unified, and easy to understand. They remain quite applicable in most real-life production settings. However, our exploration must not stop here; the demand for accuracy and personalization is increasing. Mastering linear models while continuously learning, enriching, optimizing, and improving is the long-term path for future data analysis.
Thank you for reading!
If you have more questions, feel free to consult us.

(Content sourced from the internet)