Skip to content

Years ago, Google created a wave of artificial intelligence (AI) with the stunning performance of AlphaGo. However, in the past year, Google has been under pressure due to the AI wave triggered by OpenAI’s ChatGPT, and they urgently need a phenomenal AI product to prove their strength.
Since the release of ChatGPT, people have been very curious about the capabilities of Google’s claimed competitor, the Gemini model. This large model was rumored to be in the works as early as March this year and was in the “coming soon” state during the I/O conference in May.
However, in November, there were (false) reports claiming that the release date of Google’s large model had been postponed to January 2024 due to the discovery that “the AI model could not reliably handle some non-English queries,” and support for multiple languages is crucial for Gemini’s global success.
Was it just a distraction, or was it actually released?
In the early hours of December 7, Google finally released its “natively multimodal” large model, Gemini. Google CEO Sundar Pichai officially announced that Gemini 1.0 was officially launched and stated that it is “the largest and most powerful AI model Google has ever created.”
It seems that Google knows how to create smoke screens and surprises. In Sundar Pichai’s official blog about Gemini, he wrote:
“It has state-of-the-art performance on many leading benchmark tests. Google’s first version, Gemini 1.0, is optimized for different sizes: Ultra, Pro, and Nano. These are the first models of the Gemini era and represent the first realization of the vision established when Google DeepMind was formed earlier this year. This new era of models represents one of the largest scientific and engineering efforts made by Google as a company. I am genuinely excited about the future and the opportunities that Gemini will bring to people around the world.”
What are the differences between Gemini and ChatGPT?
The so-called multimodal large model can summarize and fluently understand, manipulate, and combine different types of information, including text, code, audio, images, and videos, compared to existing large models on the market. In terms of flexibility, it can operate from data centers to mobile devices without requiring additional specialized processing or conversion.
If you ask what the difference between Gemini and GPT-4 is, you can compare GPT-4 to a poet who excels at writing poetry but also paints; writing poetry is his profession, while painting is just a side job. GPT-4 can handle text (writing poetry) and images (painting), but it is primarily strong in text processing.
On the other hand, Gemini, which possesses “natively multimodal capabilities,” is a dual talent as both a poet and a painter, excelling equally in both writing poetry and painting, with no weakness in either area. Gemini can handle text and images simultaneously and performs well in both without prioritizing one over the other.
Before the release of Gemini, Google’s two main models in generative AI and large language models (LLM), PaLM 2 and LaMDA, received low evaluations from users and lagged significantly behind the industry-leading GPT-4.
For Gemini, Google claims: “It is more powerful than all AI systems on the market, even surpassing the technology developed by OpenAI, the creator of ChatGPT.”
Reportedly, Gemini is also the first significant product after the merger of Google Brain and DeepMind to form Google DeepMind. With the precedent of AlphaGo defeating the human world champion in Go, people no longer find it surprising that AI can surpass humans in certain fields. However, under the “deterrent” of AGI and strong AI brought by ChatGPT, any AI that claims to surpass humans will inevitably attract attention.
The first large model to surpass human experts in MMLU evaluation
MMLU (Massive Multitask Language Understanding) is a test set that combines 57 subjects, including mathematics, physics, history, law, medicine, and ethics. Compared to other test sets, MMLU has stronger breadth and depth, testing AI models’ ability to understand natural language through a large number of diverse tasks, particularly in complex and variable real-world scenarios. This makes MMLU a highly challenging evaluation framework that can comprehensively assess and promote the development of large language models.
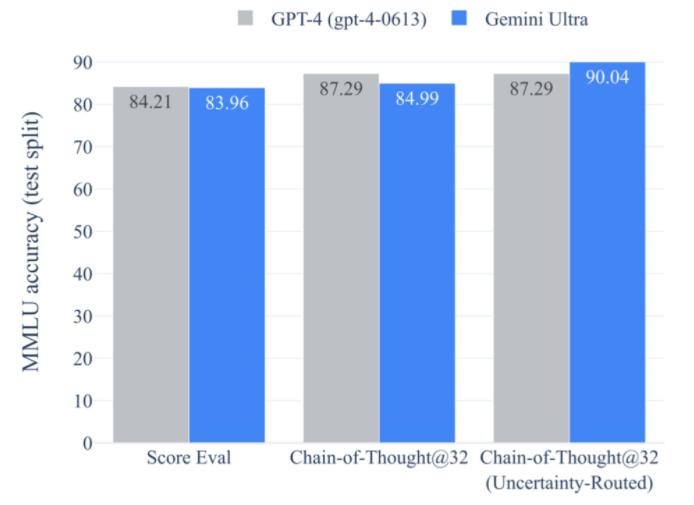
Comparison of GPT-4 and Gemini in the MMLU test set
This framework typically includes thousands of different tasks covering a wide range of themes and challenges. The purpose of MMLU is to provide a comprehensive and diverse approach to testing and evaluating language models’ performance in various complex and real-world scenarios. The test tasks may include understanding jokes, answering questions about world history, explaining scientific phenomena, and many other projects that are closer to human knowledge, common sense, and understanding ability.
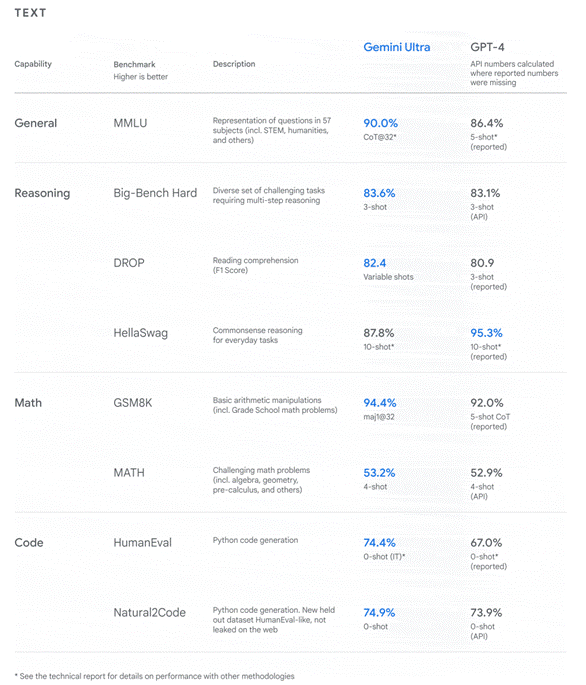
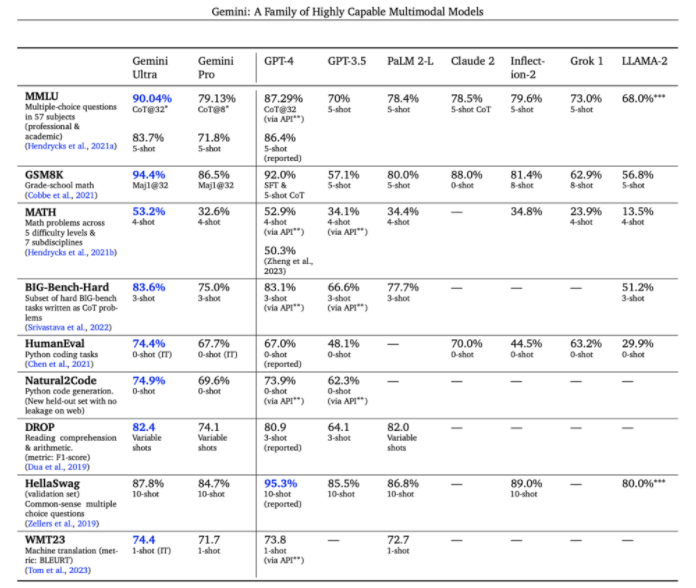
Gemini Ultra is the first large model to surpass human experts in the MMLU evaluation, achieving a score of 90.0%. In comparison, human experts scored 89.8%, while GPT-4 scored 86.4%.
Google stated on its official blog: “Gemini utilizes the MMLU benchmark method to enable it to think more carefully before answering difficult questions, resulting in significant improvements over relying solely on first impressions.”
The mainstream evaluation datasets for LLMs include GLUE, SuperGLUE, SQuAD, CommonsenseQA, CoQA, LAMBADA, etc. These are usually used to assess models’ capabilities in language understanding, reasoning, reading comprehension, and common sense reasoning.
Gemini Ultra achieved 30 SOTA (state-of-the-art) results in 32 multimodal benchmarks used in LLM development, almost completely surpassing GPT-4.
In a series of benchmark tests, including text and coding, Gemini’s performance exceeded the current state-of-the-art level.
Additionally, Gemini Ultra achieved a state-of-the-art score of 59.4% in the new MMMU (Massive Multidisciplinary Multimodal Understanding and Reasoning for AGI) benchmark test, which consists of multimodal tasks that require thoughtful reasoning across different fields.
The test results indicate that Gemini Ultra outperforms previously state-of-the-art models without the assistance of object character recognition (OCR) systems that extract text from images for further processing. These benchmarks highlight Gemini’s inherent multimodality and indicate early signs of its more complex reasoning capabilities.
Gemini’s performance in a series of benchmark tests including text and coding
Can help programmers and students solve a multitude of problems
It is reported that after training, Gemini can exhibit a more human-like way of functioning. “Gemini can understand the world around us like we do,” said Google DeepMind CEO Demis Hassabis.
In a demonstration video at the launch event, a man performed a slow-motion backward dodge, and the AI immediately guessed: this is a scene from “The Matrix” featuring “bullet time.”
When a human drew a duck on a piece of paper and colored it blue, the AI commented: “That’s not a common color for a duck.”
Three empty cups are placed side by side on a table, and a blue paper ball is stuffed into one of the cups. After a flurry of operations by a human, the AI accurately guessed: “The paper ball is in the leftmost cup!”
By uploading images of ingredients and voice input, the AI can not only guide you in cooking but also provide corresponding suggestions at different stages.
After the video demonstration, Google DeepMind Vice President of Products Eli Collins stated, “We are getting closer to the vision of the next generation of AI models. This is the most powerful and versatile large model Google has ever created.”
Programming is an important dimension for measuring the capabilities of large models and is a necessity for many programmers. Gemini Ultra has performed excellently in multiple coding benchmark tests, including HumanEval (an important industry standard for assessing coding task performance) and Natural2Code (a Google internal dataset that uses author-generated source code instead of information from the web).
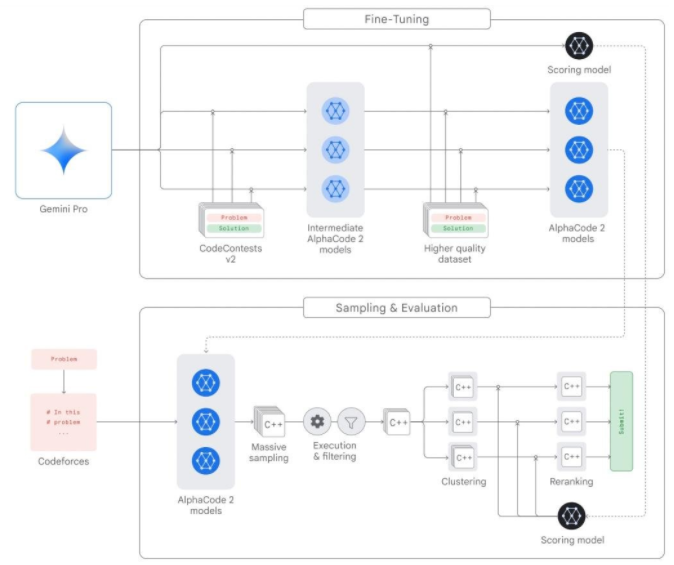
Two years ago, Google launched AlphaCode, the first AI code generation system to reach competitive levels in programming competitions. Based on Gemini, Google also launched a more advanced programming system, AlphaCode 2, which can understand, explain, and generate high-quality code in programming languages such as Python, Java, C++, and Go.
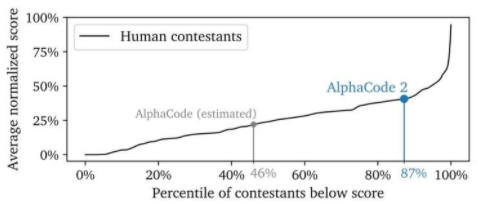
Compared to the previous generation product AlphaCode, AlphaCode 2 solves nearly twice the number of problems, outperforming 85% of competition participants, while AlphaCode’s ratio is close to 50%. If programmers collaborate with AlphaCode 2 by defining certain attributes for code examples, its performance will improve further.
Gemini is also adept at solving programming competition problems that go beyond coding, involving complex mathematics and theoretical computer science. For example, in a problem-solving scenario, Gemini’s multimodal reasoning ability allows the AI to read messy handwriting, correctly understand the problem statement, convert both the problem and solution into numerical typesetting, identify specific reasoning steps where humans made mistakes, and provide the correct solution step by step.
For example, a teacher drew a physics problem of a skier coming down a slope, while a student proposed a solution to calculate the skier’s speed at the bottom of the slope. Utilizing Gemini’s multimodal reasoning ability, the model can read messy handwriting, correctly understand the problem statement, convert both the problem and solution into mathematical formulas, identify specific reasoning steps where the student made mistakes, and then provide the correct solution to the problem.
Three major versions, each with its strengths
This release includes three versions:
Ultra is the most powerful model, suitable for highly complex tasks, operating in the cloud;
Pro is the best general-purpose model that can be scaled for various tasks;
Nano is a small model designed for edge devices, such as running on mobile phones and various consumer devices. Nano is further divided into two model sizes: Nano-1 (1.8 billion parameters) and Nano-2 (3.25 billion parameters), targeting low-memory and high-memory devices, respectively.
Among them, Gemini Pro and Gemini Nano have been integrated into the chatbot Bard and the smartphone Pixel 8 Pro, respectively, while the most powerful Gemini Ultra will be released next year. At that time, its Ultra model will be used to launch the enhanced version of the chatbot “Bard Advanced,” initially available only to a test audience.
Google stated that they will first conduct early experiments and feedback sessions with customers, developers, partners, and safety and responsibility experts, and the Ultra version is expected to be available to developers and enterprise customers in early 2024.
From the day of release, Bard will use a fine-tuned version of Gemini Pro to perform more advanced reasoning, planning, and understanding. This is Bard’s biggest upgrade since its launch, and after integrating Gemini Pro, it has already provided English services in over 170 countries and regions.
Google has also tested the Pro version against many industry-standard benchmarks. The results showed that Gemini Pro outperformed GPT-3.5 in 6 out of 8 benchmark tests. To showcase how powerful the upgraded Bard is, Google even invited a YouTube educational influencer, Mark Rober, to use Bard as an assistant tool to design and build a large paper airplane from scratch!
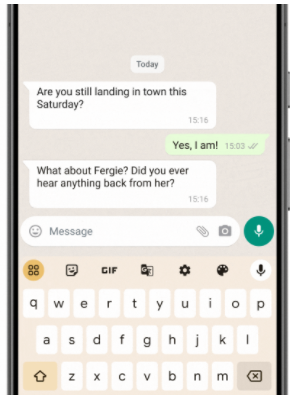
Although it is the weakest in capability, Gemini Nano has garnered the most attention due to its clear usage prospects. According to reports, users of the Pixel 8 Pro can already use the recording app to summarize recorded content and provide suggested automatic replies for messaging services like WhatsApp. The Pixel 8 Pro is also the first Google smartphone designed for Gemini Nano, with many features callable directly without the need for internet access.
In the coming months, Gemini will appear in more Google products and services, such as search, advertising, Chrome, and Duet AI.
One of the reasons for its strength: dedicated TPU training
Google stated that one of the reasons Gemini is stronger than its competitors is its powerful computing capabilities.
It is reported that Google used internally designed Tensor Processing Units (TPUs) v4 and v5e to conduct large-scale training on Gemini 1.0 within an AI-optimized infrastructure, designed to be the most reliable, scalable training model and the most efficient service model.
On TPUs, Gemini runs significantly faster than earlier smaller-scale and weaker models. These custom-designed AI accelerators are at the core of Google’s AI products, serving billions of users across services like search, YouTube, Gmail, Google Maps, Google Play, and Android. They also help companies around the world efficiently train large-scale AI models.
In terms of training optimization, Gemini has increased the utilization of model parallelism and data parallelism, optimizing for network latency and bandwidth. Gemini also uses Jax and Pathways programming models to provide optimized support for complex mathematical operations common in machine learning.
Jax is particularly suitable for efficiently performing large-scale array operations. Pathways refers to programming models or frameworks used to manage and coordinate large-scale training tasks. By using these tools, developers of the Gemini model can coordinate the entire training process using a single Python process, simplifying the development and training workflow while leveraging the efficient performance of Jax and Pathways.
At the launch event, Google also released the most powerful, efficient, and scalable TPU system to date — Cloud TPU v5p, claiming that training speed is 2.8 times faster than the previous generation, designed specifically for training cutting-edge AI models. The new generation of TPUs will accelerate the development of Gemini, helping developers and enterprise customers train large-scale generative AI models faster, bringing new products and features to customers sooner.
Competitors are also not idle
According to foreign media, Google’s Gemini aims to compete with OpenAI, the developer behind ChatGPT, in the field of conversational AI. By releasing Gemini, Google hopes not only to match ChatGPT but also to surpass it, providing a more seamless and natural conversation experience.
Although it was prompted this time, OpenAI has actually not been idle. According to The Information’s report in September this year, OpenAI is developing a multimodal large model named Gobi, which is directly aimed at Google’s Gemini. However, specific information about this large model product has not yet been confirmed, and OpenAI originally hoped to launch it before Google’s Gemini release but was clearly delayed due to internal competition.
Additionally, just before Google released Gemini, Microsoft announced a significant upgrade to its AI assistant Copilot, which will integrate OpenAI’s latest model, GPT-4 Turbo.
The release of Gemini has only scratched the surface of the multimodal field, which is still in the early stages of technological exploration, and the technological path has not yet been determined. Compared to large language models, multimodal models add audio, video, and images to the data, making training more challenging.
But why are the giants still pursuing this? According to Cisco’s annual internet report, video now accounts for over 80% of internet traffic. In an age where video content has become mainstream, it is clear that large models consisting solely of text and images are no longer sufficient.
Although it seems that Google Gemini currently excels in “benchmark scores,” what is more important moving forward is the competition among large models in practical applications. Among these, AI safety has recently become a hot topic, which Google has emphasized in this release.
Google’s Vice President of Infrastructure and Systems, Amin Vahdat, stated that potential risks are considered at every stage of Gemini’s development, and efforts are made to test and mitigate these risks.
He revealed that Gemini’s safety assessment includes bias and toxicity assessments and applies adversarial testing techniques from Google Research to help detect critical safety issues before deploying Gemini.
For instance, to diagnose content safety issues during Gemini’s training phase and ensure its output aligns with policies, Google’s team used several benchmark tests, such as Real Toxicity Prompts, a set of benchmark tests developed by experts from the Allen Institute of AI, containing 100,000 prompts with varying degrees of toxicity extracted from the internet.
Additionally, to reduce harm, the team has built dedicated safety classifiers to identify, tag, and filter content involving violence or negative stereotypes, among other aspects. “Moreover, we are continuing to address known challenges faced by the model, such as factuality, grounding, attribution, and collaboration.”
Google has not disclosed whether it will create dedicated applications for Gemini in the future, but executives have expressed a desire to see users create more applications based on this technology.
Google revealed that starting from December 13, developers and enterprise customers can access Gemini Pro through the Gemini API in Google AI Studio or Google Cloud Vertex AI.
Click to watch the video