

Author: David9
Address: http://nooverfit.com/
Named Entity Recognition (NER) is an important topic in semantic understanding. NER is like object detection in the field of natural language.
Finding noun entities in document D is not enough; in many cases, we need to understand whether this noun represents a location, person, or organization, etc.:

The above figure shows an example of NER marking nouns after outputting a sentence.
Before the emergence of neural networks, almost all semi-supervised or unsupervised methods for NER relied on handcrafted word features or external supervision libraries (such as gazetteers) to achieve the best recognition results.
Handcrafted word features can conveniently extract features like prefixes, suffixes, and roots, such as:
-ance, -ancy indicates: behavior, nature, state / distance, currency-ant, -ent indicates: person, … of / assistant, excellent-ary indicates: place, person, thing / library, military
It can be inferred that words ending with -ant are likely to refer to people, while those ending with -ary are more likely to refer to locations.
Meanwhile, external supervision libraries (such as gazetteers) aggregate similar types of entities into a library to help identify entities with the same meaning, such as:
auntie actually means the same as aunt: aunt
Mikey is actually a nickname for Mike, both are people’s names
The paper discussed today from Carnegie Mellon University uses RNN-related techniques to avoid using these manual features and achieves comparable accuracy.
To obtain the aforementioned prefixes, suffixes, roots, and other relevant features, the article trains a Bi-LSTM for each letter of every word, using the output of the Bi-LSTM as a special embedding for the word, and combines it with the pre-trained eStack LSTM algorithm to recognize named entities. If interested, you can continue reading the original paper.
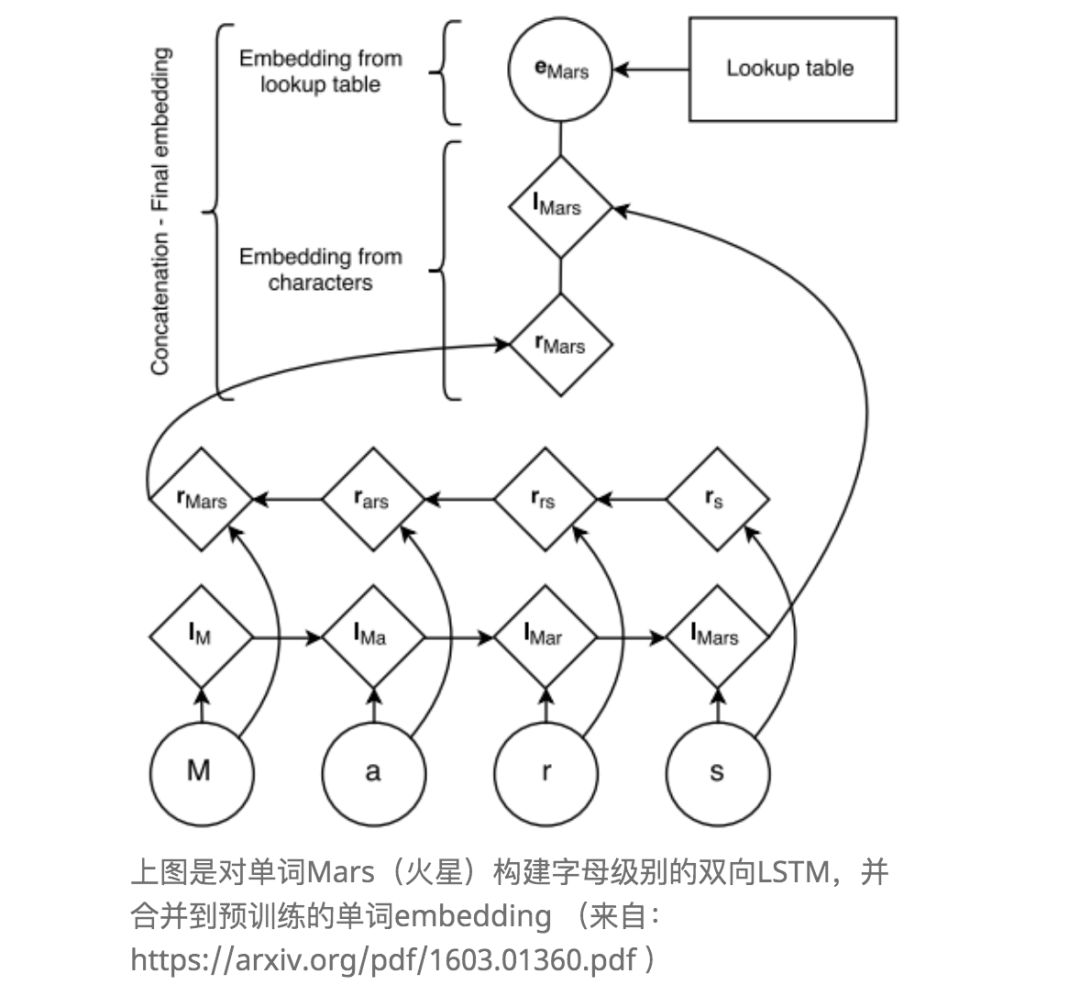
The Bi-LSTM can capture some patterns of letter spelling (prefixes, suffixes, roots), and the pre-trained embedding can capture global similarities between words. The combination gives us better word embeddings.
Having word embeddings is far from enough; we need to effectively utilize these embeddings to tackle the NER problem. An NER prediction problem is not much different from general machine learning: provide a training set (a collection of documents already labeled with named entities) and evaluate the model using a test set (documents without labeled named entities) based on the NER recognition rate.
The paper combines two aspects to improve the named entity recognition rate:
1. Modeling the possible part-of-speech tag of the next word after a word (e.g., the verb “eat” is likely followed by entities like “food” (“rice”, “noodles”, etc.), and rarely followed by “location” entities)
2. For a word (ignoring part of speech), considering the context words, modeling the most likely named entity for that word.
The second point can be modeled using Bi-LSTM (input is the aforementioned word embeddings), while the first point can be modeled using Conditional Random Fields (CRF) (similar to Markov chains). The combined model architecture is as follows:
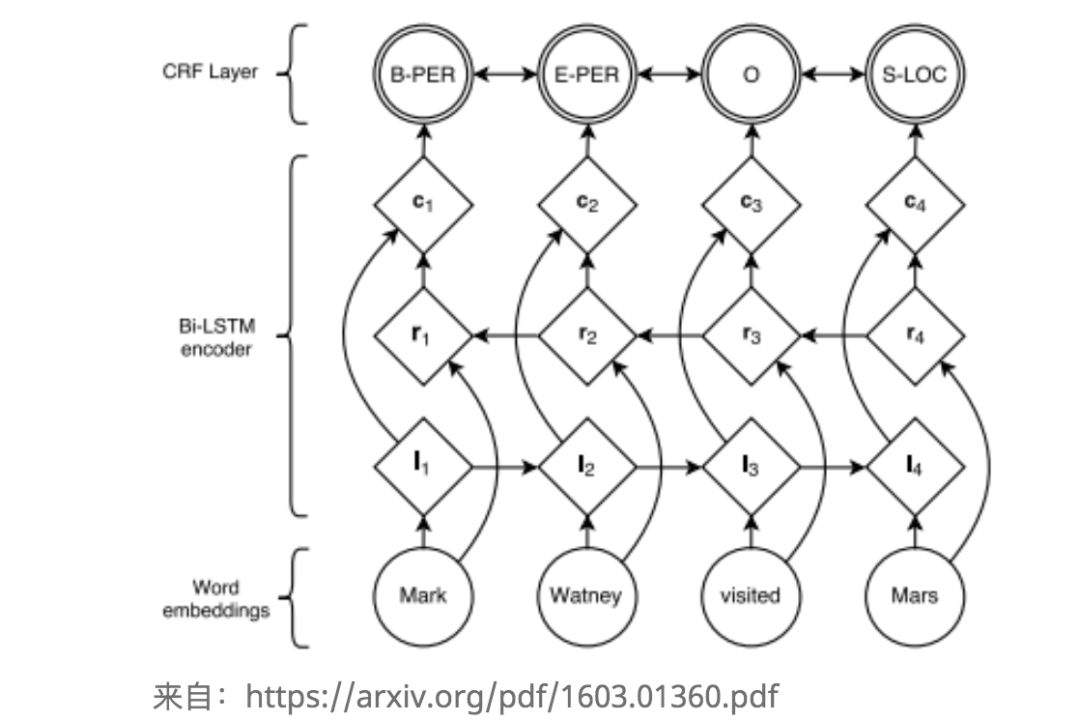
Where the bottom layer (word embedding) refers to the word embeddings mentioned earlier.
The middle layer (Bi-LSTM) represents the context features to the left of the word, while the right side represents the context features to the right of the word, and the composition represents both sides.
The top layer (CRF) models the relationships between word tags, improving NER accuracy.
In terms of the loss function, the article also considers the aforementioned two factors (the transition rate from tag to tag, and the probability of a word being a certain tag):
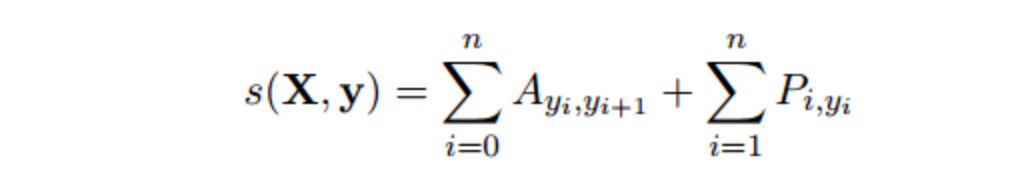
Where, X=(x1, x2, . . . , xn) represents a sequence of sentences,
y = (y1, y2, . . . , yn) represents the tag predictions for the above sequence
s(X, y) is the score for this prediction
The first part matrix Ayi,yi+1 represents the scoring of the transition possibility from tag yi to the next tag yi+1
The second part matrix Pi,yi is the probability of the ith word being predicted as tag yi.
Finally, let’s take a look at the experimental data:
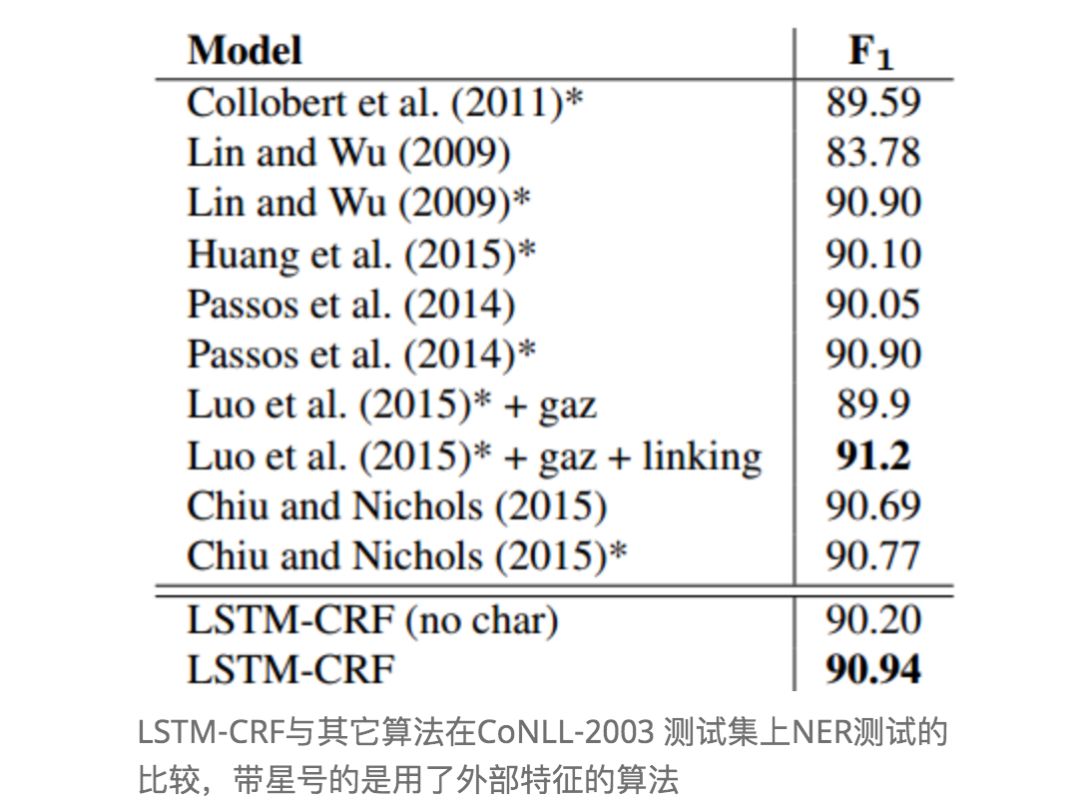
As expected, LSTM-CRF without using single-character embeddings performs slightly worse.
Additionally, besides LSTM-CRF, the paper also uses the stacked Stack LSTM algorithm to recognize named entities. If interested, you can continue reading the original paper.
References:
-
Neural Architectures for Named Entity Recognition
-
http://eli5.readthedocs.io/en/latest/tutorials/sklearn_crfsuite.html
-
https://github.com/glample/tagger
-
https://github.com/clab/stack-lstm-ner
-
http://www.datacommunitydc.org/blog/2013/04/a-survey-of-stochastic-and-gazetteer-based-approaches-for-named-entity-recognition-part-2
Recommended Reading:
When Do Deep Learning Models Need Tree Structures in NLP?
How to Handle Variable-Length RNN Input Padding in PyTorch
A Detailed Explanation of Maximum A Posteriori Estimation (MAP)
Welcome to follow our public account for learning and communication~
