Click the above “Beginner Learning Vision“, choose to add “Starred” or “Top“
Heavyweight content delivered first time
Today, computer vision (CV) has become one of the main applications of artificial intelligence (e.g., image recognition, object tracking, multi-label classification). In this article, we will understand some of the main steps that constitute a computer vision system.
The general workflow of a computer vision system includes the following steps:
1. Image acquisition and input into the system.
2. Image preprocessing and feature extraction.
3. Using the extracted features to train models and make predictions through a machine learning system.
Next, we will briefly introduce some of the main processes the image undergoes in these three different steps.
When implementing a CV system, we need to consider two main components: image acquisition hardware and image processing software. One of the main requirements for deploying a CV system is to test its robustness. In fact, our system should be able to adapt to environmental changes (e.g., changes in lighting, orientation, and scale) and be able to repeatedly perform its designed tasks. To meet these requirements, it may be necessary to apply some form of constraints to the hardware or software of our system (e.g., remotely controlling the lighting environment).
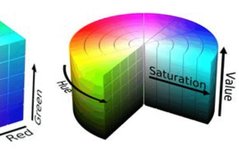
After obtaining images from hardware devices, various methods can be used to digitally represent colors (color spaces) in the software system. Two of the most well-known color spaces are RGB (Red, Green, Blue) and HSV (Hue, Saturation, Value). The main advantage of using the HSV color space is that it can keep the system’s lighting invariant when only considering the HS components. These two color spaces are shown in the figure below.
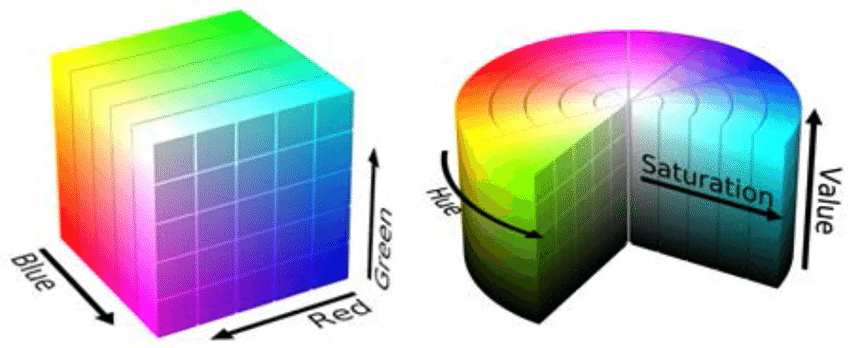
RGB vs. HSV Color Spaces
Once the image enters the system and is represented using a color space, we can perform different operations on the image:
Point Operations: Some examples of point operators include intensity normalization, histogram equalization, and threshold processing. Point operators are typically used to help better visualize human visual images but do not necessarily provide any advantage for computer vision systems.
Region Operations: In this case, we obtain a set of points from the original image to reconstruct a pixel point during the operation on the image. This type of operation is usually accomplished through convolution. To obtain the post-operation results, different types of kernels can be convolved with the image. For example: direct averaging, Gaussian averaging, and median filtering. Convolution operations on images can reduce the amount of noise in the image and improve smoothness (although this may also cause the image to be slightly blurred). Since we use a set of points to create a single new point in the new image, the size of the new image will necessarily be smaller than that of the original image. One way to address this issue is to apply zero padding (setting pixel values to zero) or using smaller templates at the edges of the image. One of the main limitations of using convolution is that it is slow when processing larger templates, and one solution to this issue is to use Fourier transforms instead. The convolution process is illustrated in the animated image below.

After preprocessing the image, we can perform more operations to try to extract edges and shapes in the image using methods such as first-order edge detection (e.g., Prewitt operator, Sobel operator, Canny edge detector) or detecting lines or circles using the Hough transform.
After preprocessing the image, we can use feature extractors to extract four main types of feature forms from the image:
Global Features: Analyze the entire image as a whole and then extract a single feature vector from the feature extractor. A simple example of global features is the histogram of merged pixel values.
Grid-based or Block-based Features: Divide the image into different blocks and extract features from each distinct block. This type of feature is often used to train machine learning models.
Region-based Features: Segment the image into different regions (e.g., using techniques such as thresholding or K-Means clustering, then decomposing into different connected domains), and extract features from each region. Features can be extracted using region and boundary description methods (e.g., “moments” and “chain code”).
Local Features: Detect multiple individual interest points in the image and extract features by analyzing the pixels of neighboring interest points. The main types of interest pixels that can be extracted from the image are corner points and blobs. Methods such as Harris, Stephens Detector, and Gaussian Laplacian can be used to extract them. Finally, techniques such as SIFT (Scale-Invariant Feature Transform) can be used to extract features from the detected interest points. Local features are typically used to match images to build panoramas or perform 3D reconstruction, as well as retrieve images from a database.
Once a set of discriminative features has been extracted, we can use them to train machine learning models and make predictions.
One of the commonly used tools for classifying images in computer vision is the Bag of Visual Words (BoVW). To construct a bag of visual words, we first need to create a vocabulary by extracting all features from a set of images (e.g., using grid-based features or local features). Afterward, we can calculate the frequency of the extracted features occurring in the images and build a frequency histogram based on the results. Using the frequency histogram as a basic template, we can classify images based on whether they belong to the same category by comparing the histograms of the images, as shown in the figure below.
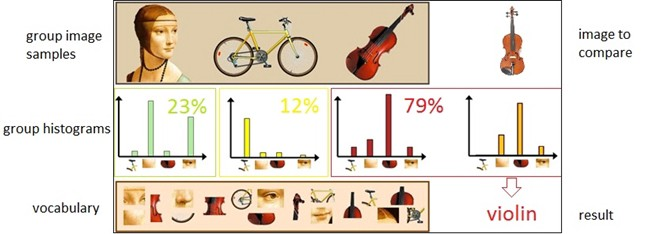
This process can be summarized in the following steps:
First, we construct a vocabulary by extracting different features from the image dataset using feature extraction algorithms (e.g., SIFT and Dense SIFT).
Second, we cluster all features in the vocabulary using algorithms such as K-Means or DBSCAN and summarize the data distribution using the cluster centroids.
Afterward, we can construct a frequency histogram from each image by calculating the frequency of different features in the vocabulary appearing in the image.
Then, by repeating the same process for each image to be classified and using any classification algorithm, we can classify new images by finding which image in the vocabulary is most similar to our test image.
Additionally, as the architecture of artificial neural networks has matured, such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RCNN), these network structures can propose an alternative workflow for computer vision, replacing the above process, directly obtaining input results from the input image through the neural network. The specific form is shown in the figure below.
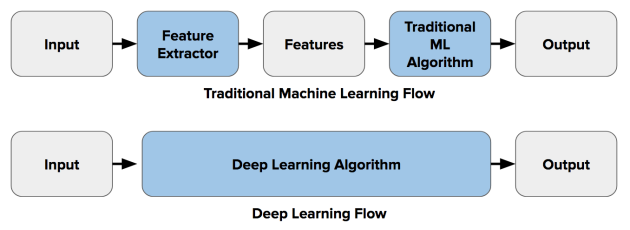
In this case, deep learning algorithms combine the feature extraction and classification steps of the computer vision workflow. When using Convolutional Neural Networks, each layer of the neural network applies different feature extraction techniques during the description (e.g., the 1st layer detects edges, the 2nd layer finds shapes in the image, the 3rd layer segments the image, etc.).
Further applications of machine learning in computer vision include multi-label classification and object recognition. In multi-label classification, we aim to build a model that can correctly identify how many objects are in the image and which class they belong to. Conversely, in object recognition, we aim to further develop this concept by identifying the locations of different objects in the image.
Discussion Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D Vision, Sensors, Autonomous Driving, Computational Photography, Detection, Segmentation, Recognition, Medical Imaging, GAN, Algorithm Competitions (which will be gradually subdivided in the future). Please scan the WeChat number below to join the group, with the note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format for notes; otherwise, it will not be approved. After adding successfully, you will be invited to enter the relevant WeChat group based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed, thank you for your understanding~

