

Preparation for Reading
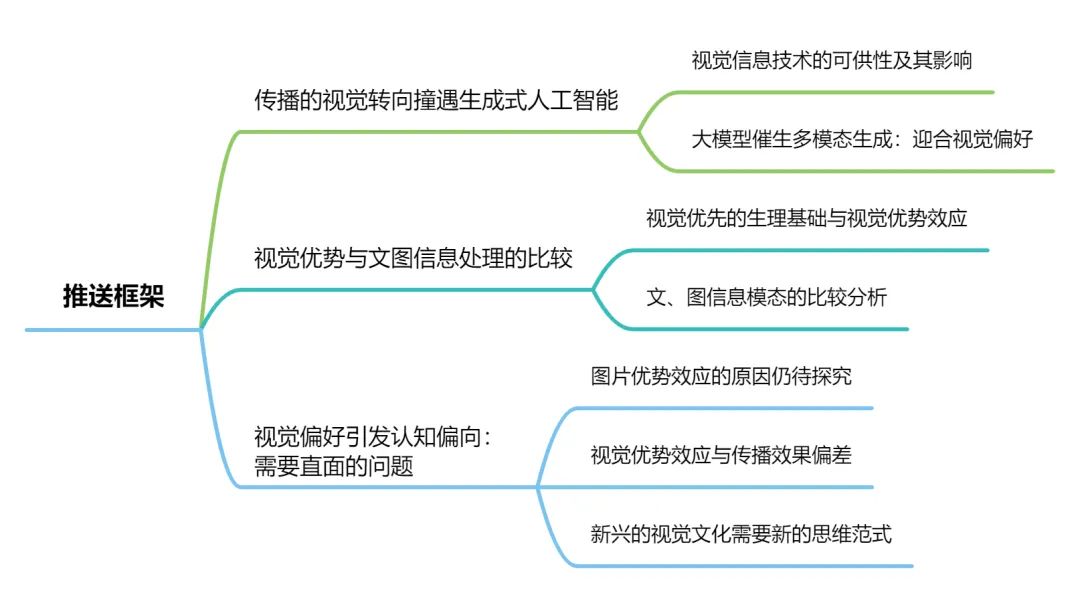
Contemporary information dissemination presents a clear visual advantage effect, and the emerging generative artificial intelligence has made the generation and dissemination of visual information more convenient, bringing complex modal bias issues and cognitive challenges. Why has visual information become a preferred mode of communication? What impact does generative AI have on visual preferences? Will the visual advantage effect trigger cognitive biases among audiences, and what challenges does it pose for communication?
The paper recommended in this issue draws on theories from communication studies and cognitive psychology to explore the issue of modal bias. Under the premise of comparing and analyzing the characteristics of visual information and textual information dissemination, it proposes strategic considerations for optimizing information dissemination effects and enhancing audience cognition.
Integrating the thinking of technological computationism with neuroscience, generative AI is driving a new communication revolution. It greatly enhances the generation capability and accessibility of visual content, changing how information is consumed, shared, and understood, leading to a growing inclination to use visual modes in information dissemination. The convenient generation of visual content enhances the capability of visual communication, increases engagement and accessibility, and benefits the effectiveness and influence of information dissemination. However, it also brings structural disruption and profound cognitive challenges.
Why has visual information become a preference? What impact does generative AI have on visual preferences? Will the visual advantage effect trigger cognitive biases among users, and what challenges does it pose for communication? This paper will explore the factors that lead people to prefer visual information, especially concerning the issue of visual modal preference in the context of generative AI, and analyze the challenges and reflections brought about by this preference and its exacerbation trend.
The Visual Turn in Communication Meets Generative AI
The visual information referred to in this paper is narrowly defined as content conveyed through visual elements, including images, videos, and graphics. These elements play a crucial role in human communication activities, providing elements and impact often lacking in textual information.
Human communication has historically been storytelling; as technology brings about changes, the socio-cultural conditions of communication have shifted, and the ways of storytelling are constantly evolving.
The history of visual communication can be traced back to the earliest times when humans communicated through visual symbols and signs. The rise of print media and advertising opened the early forms of modern visual communication, and the development of print media is closely linked to the “image revolution.” The invention of television allowed images and sounds to be disseminated to the public.
Visual culture has brought profound cultural changes, with the emergence of “image turn” and “visual turn” in the 1980s. Against this backdrop, the fields of humanities and social sciences began to recognize the importance of visual practices and visuality, acknowledging their crucial role in the generation of meaning in daily life.
In the latter half of the 20th century, the development of digital technology had a profound impact on visual communication. The invention of computers and graphic design software innovated the creation and processing of images, and the communication field was also eager to explore issues of visual turn.
Today, artificial intelligence has opened a new era of visual communication, with virtual reality and augmented reality providing immersive and interactive experiences; AI algorithms can analyze user data and preferences, driving personalized communication; generative AI can generate stunningly realistic visual products based on simple textual descriptions, and AI generators can create extremely complex images and videos with great ease, reconstructing visual narratives.
01
Availability of Visual Information Technology and Its Impact
The Internet and its resulting digital transformation of information have led to significant advancements in visual technology. From camera hardware to computing software, the rapid development of technology has driven the popularization of video information.
● Significant advances in camera technology have made the production of high-definition and ultra-high-definition videos possible. The barriers to video production have been greatly lowered, and high-performance smartphones with advanced camera functions enable more people to engage in personal video creation.
● In terms of software and computing technology, improvements in professional graphics processing units and the widespread adoption of cloud computing technologies have greatly enhanced the efficiency of video processing and encoding.
● Advanced video encoding and decoding technologies have significantly improved video transmission efficiency, ensuring video quality while reducing bandwidth requirements, enabling the smooth and efficient transmission of massive amounts of video.
● The introduction of 5G technology has provided new momentum for video information, with near-instantaneous transmission speeds and low latency making real-time video interaction and high-definition streaming a reality.
● It provides a foundation for immersive applications such as AR and VR.
Social and video software have also influenced the development of multimodal technologies, providing a wealth of data and application scenarios that promote the multimodalization of video content, facilitate the dissemination and sharing of multimodal information, and support the development of multimodal interaction and multimodal sentiment analysis applications.
In the real media world, the instant gratification of image and video information prompts viewers and users to prefer visual information, while commercial demands further drive the widespread shift towards visual bias in communication. Today, digitalization has more widely spawned the trend of visualizing information platforms. In recent years, video platforms have become a “hot spot.” Since the advent of generative AI, the generation of images and videos has become convenient and accessible, giving rise to a new wave of visual communication.
Big data and intelligent recommendation algorithms have exacerbated the ubiquity of visual information dissemination. Social platforms utilize intelligent algorithms to analyze preferences and accurately push content, thereby enhancing user experience and stickiness. The personalized recommendation mechanism has altered traditional information dissemination models, further strengthening the position of video content in social activities. Based on interpersonal communication and algorithmic recommendations, videos can quickly spread within social networks.
Generative AI has been embedded in image and video editing software, which can enhance the resolution of visual content, and convenient video creation tools and sharing platforms have sparked users’ creative enthusiasm. Some platforms also implement reward mechanisms to further encourage users to create high-quality video content. This model not only changes the way users consume content but also creates new business models.
02
Large Models Give Rise to Multimodal Generation:
Meeting Visual Preferences
The foundation of multimodal information generation is the leapfrog development of generative AI technology. The core of generative AI is to automatically generate various types of content through machine learning and deep learning technologies, typically involving steps such as data collection, data preprocessing, model training, content generation, and evaluation and refinement, benefiting from innovations in model architecture, improvements in computing power, and the richness of datasets.
The widespread application of Generative Adversarial Networks and Transformer models is also of great significance for multimodal generation. Since 2014, Generative Adversarial Networks have become a research hotspot, consisting of generators and discriminators capable of effectively generating highly realistic images and videos, thereby broadening the field of generated content. Subsequently, models based on Variational Autoencoders and Transformers gradually emerged, particularly marked by the launch of the GPT series by OpenAI in 2018, representing a significant advancement in the field of natural language processing.
At the end of 2022, OpenAI released a new chatbot based on contextual dynamic algorithms, ChatGPT, which elevated multimodal generation capabilities to a new height. Generative AI has only emerged for a little over a year, yet it has already achieved nearly free conversion between text, sound, image, and video information modalities. AI models like DALL-E, Midjourney, and StableDiffusion are fundamentally changing the way visual content is created. AI image generators utilize machine learning algorithms to mobilize vast visual resources to train input parameters, mixing and matching components from existing images to generate new images and videos, with outputs that can be diverse and creative. The data visualization capabilities of generative AI can almost explain various data in a storytelling format.
The ability to follow instructions is one of the representative emergent capabilities of large models, closely related to contextual learning capabilities. In 2023, ChatGPT iterated to ChatGPT-4.0, boasting stronger multimodal generation capabilities, capable of learning more complex patterns and knowledge, enhancing the quality and accuracy of generated content; based on this, ChatGPT-4o has also improved in understanding and mobilizing various GPTs and their comprehensive applications. In China, 2023 saw the rapid launch of products like Baidu’s Wenxin Yiyan and its 4.0 version, along with Tongyi Qianwen, iFLYTEK Spark, Doubao, Zhipu AI, and the emergence of domestic AI products, presenting a fervent scene of “hundred model battles.” Additionally, OpenAI’s Sora, set to debut in February 2024, is expected to elevate video generation capabilities to a new height.
Currently, multimodal research focuses on how to achieve efficient fusion of multimodal data through neural networks to enhance the intelligence level and response speed of systems. Driven by technology, changes in user demands, and the use of social media, user needs are growing, and multimodal generation technology is showing strong potential for integrating various forms of information, bringing new possibilities for content creation, as well as new challenges.
Visual Advantages Compared to Text and Image Information Processing
The image advantage effect refers to the phenomenon where visual information is easier to notice, remember, and recall than verbal or textual information. This phenomenon has been widely confirmed by cognitive psychology and educational research. Today, multimodal information generation integrates various sensory elements, yet multimodal information cannot be evenly utilized by humans and is inevitably influenced by the visual advantage effect.
01
Physiological Basis of Visual Priority and the Visual Advantage Effect
Vision is the most widely recognized and studied sensory modality, with research indicating that most human impressions and memories of the world are based on visual input. However, cultural interpretations emphasize that the dominance of vision is a result of societal design, thus deeply influenced by human decision-making. Humans are highly visual beings, with approximately 70% of sensory input coming from vision. Here, vision refers to the human sensory modality, while visual preferences have shifted towards cultural production, and sensory preferences have shifted towards visualized information modalities.
The visual cortex occupies a significant proportion of the human brain, and the richness and complexity of visual information require the brain to allocate substantial resources for processing. Human behavior exhibits priority characteristics, prioritizing certain stimuli over others. Behavioral priority characteristics manifest in aspects such as perceptual expertise, goal-directed attention, visual salience, image memorability, and visual novelty. Experimental studies have shown that people perform better in learning and remembering image content compared to text, a phenomenon known as the “picture superiority effect.”
From an evolutionary perspective, the priority of the visual system aids human survival and adaptation in natural environments, as our visual system has evolved to process multiple images in parallel. Text appeared relatively late in human history; the brain must scan and recognize one character at a time, assemble words, and then combine them into sentences to derive meaning. Thus, textual information is less perceptible in memory tasks than visual information.
From the perspective of cognitive psychology, when humans receive visual and auditory information simultaneously, visual information often dominates the overall understanding of information, demonstrating the “visual priority effect” or “visual advantage effect.”
The visual cortex interacts with other brain regions, participating in higher cognitive functions such as memory, emotion, and decision-making. Therefore, humans exhibit a visual preference when processing multimodal information, which not only affects the way information is received but also has profound implications for understanding and memory.
02
Comparative Analysis of Text and Image Information Modalities
New media technology itself is a systemic factor of change, involving the way we observe the world, i.e., our worldview. Therefore, visual information dissemination alters our experiences, perceptions, values, and behavioral patterns, even the existence of the world itself.
Media mechanisms centered around images are emotion-driven, characterized by reality, synchronicity, and proximity, leading to immediate satisfaction and rapid emotional responses. Image researchers point out that when images replace text, our ways of experiencing, perceiving, and measuring the world and ourselves shift from a one-dimensional, linear, process-oriented, historical approach to a two-dimensional approach that is surface, environmental, and contextual; our behaviors also become less attention-grabbing and more integrated into relational domains.
Text and images are both intermediaries and rules.Textual words represent the world through denotation, while images and videos represent the world through connotation. Text can directly express thoughts because the connection between denotation and connotation is direct and conventional. In contrast, the relationship between the meaning of images and their representation is indirect, variable, and open, requiring viewers to dig deeper to reveal.
Humans process textual and visual information differently.
● From the perspective of cognitive processes, processing textual information requires deep semantic analysis, understanding syntax, and logical reasoning, which can be challenging; processing visual information mainly relies on perception and intuitive understanding.
● From the perspective of processing speed, textual information processing is usually slower, requiring reading and understanding word by word; processing visual information is typically faster, allowing for immediate recognition and understanding of images.
● From the perspective of memory effects, textual information requires reading, analysis, and reasoning, and its complex processing enhances understanding and memory; understanding the meanings of words and sentences forms associations and structures between concepts, aiding long-term memory and application; in contrast, visual information tends to have better short-term memory effects, as image memory is significantly effective in the short term.
● From the perspective of depth of understanding, textual information necessitates active thinking and reflection, forming complex cognitive structures that are deeper and can evoke readers’ imagination and emotional resonance; visual information simplifies complex concepts through images and symbols, potentially leading to distortion or overgeneralization, making it difficult for viewers to fully grasp the nuances and context of the information, overall leading to superficiality.
● From the perspective of cognitive load, the semantic complexity of textual information may increase cognitive load but can be reduced through organization and structuring; visual information typically has a lower cognitive load, but excessive exposure can lead to visual overload, where a large amount of visual stimuli may make it hard for individuals to focus on key information, resulting in superficiality and fragmentation of information.
Visual Preferences Trigger Cognitive Biases:
Issues That Need to Be Addressed
The emergence of generative AI has accelerated the paradigm shift in communication, leading to an increasing preference for visual information, with users increasingly prioritizing video content over text-based formats. This is also a reality factor in discussions about visual modal preferences today.
01
The Reasons for the Picture Superiority Effect Remain to Be Explored
The picture superiority effect is based on Paivio’s dual coding theory, which posits that the brain processes language and non-language information differently, with images being easier to recall. Dual coding theory predicts that when different codes are activated, there should be an incremental impact on performance. Images can simultaneously trigger verbal coding and image coding, connecting both types of codes to the image, thereby increasing the chances of retrieval during memory tasks. The sensory semantics theory proposed by Nelson et al. also highlights differences in image coding. Firstly, images are perceptually more distinctive than text, with each image’s coding being more unique, enhancing retrieval opportunities; secondly, images can present meanings more directly than text.
The aforementioned theories attribute the reasons for the picture superiority effect to differences in how images and text are coded, but their limitations have long been a subject of controversy. To date, there has been no clear conclusion regarding the reasons for the picture superiority phenomenon.
Recent studies indicate that the picture superiority effect indeed exists, but dual coding theory may not be the best explanation for the picture superiority argument. Both theories emphasize coding while neglecting retrieval differences; their studies do not compare automatic memory and conscious memory. Moreover, dual coding theory and others do not consider that cognition may be mediated by aspects other than text and images. Dual coding theory applies only to tasks requiring individuals to focus on how concepts relate. If no association can be formed between text (words) and images, it becomes difficult to remember and recall that text later.
This means that while the picture superiority effect undoubtedly exists, the convenient generation and ubiquity of visual information brought about by generative AI will lead to even more complex phenomena and impacts.
02
Visual Advantage Effect and Deviations in Communication Effects
Although existing research has not thoroughly explored the reasons for the visual advantage effect, it acts as a phenomenon that drives preferences in information dissemination and further influences preferences in information reception.
Cognitive science indicates that audiences possess two distinctly different psychological reception mechanisms for text and images: the human brain employs systematic cognitive mechanisms and heuristic cognitive mechanisms as two different compilation methods. The language information system is an abstract logical discourse that often requires the systematic cognitive mechanism to grasp its meaning; whereas visual content often conveys a clear sense of presence through vivid and intuitive visual symbols, frequently activating and invoking the convenient, simple heuristic cognitive mechanism. Visual content generates a powerful instantaneous identification force, making it easy for people to enter the discourse, order, and meaning behind the images through pre-designed cognitive pathways, presenting a behavior of agreement.
The visual advantage effect allows for rapid learning and memory, but the image advantage effect/visual information priority may also trigger cognitive biases, potentially affecting how we perceive, understand, and prioritize information.
● It may lead to attention bias. The visual priority effect causes visuals to attract attention more easily than text, possibly leading people to over-focus on visual elements and overlook important textual information;
● It may result in memory bias, as people are more likely to remember and recall visually presented content. Existing research has demonstrated that the picture superiority effect makes it easier for individuals to remember visual information;
● It may trigger confirmation bias. When individuals have a strong visual memory of a concept, they are more likely to affirm existing visual understandings and seek out and interpret new information accordingly, reinforcing the understanding biases brought about by the picture superiority effect;
● It may cause associative and heuristic biases. The ease with which visual information emerges in the mind can influence our judgments and decisions, leading us to rely on memorable visual information when making evaluations, resulting in associative and heuristic biases.
These cognitive biases brought about by visual advantages can trigger problems and consequences in information acquisition, analysis, judgment, and comprehensive understanding.
They may weaken our discernment (or critical thinking). In a digital environment that prioritizes images and videos, particularly with the visual information generation preference brought about by generative AI, there is encouragement for rapid, emotional processing of received information rather than deeper analytical thinking, leading to automatic and intuitive thinking, reducing discernment reasoning and analytical reflection.
The speed of discovering and focusing on images comes at the cost of depth. Prioritizing visual effects over text leads to information processing biases, causing individuals to overlook or underestimate key textual details while concentrating on more easily digestible visual effects.
While visual information is easier to process and typically requires less effort than reading and interpreting text, it can lead to shallow learning and understanding, where we remember diagrams more easily but may lack a complete understanding of underlying concepts. In such contexts, visual information may lead to heuristic biases—individuals rely on cognitive shortcuts rather than engaging in deep processing, making decisions based on affective and incomplete information. Research indicates that media exhibit visual framing effects, where the presentation of visual content influences how people interpret events or issues, often leading to cognition and decisions driven more by emotions than by facts. Studies have also shown that poorly conceived visualizations can distract audiences from core information and may even constitute “misinformation.” Poor content presentation can not only disrupt existing narratives but also threaten the overall effectiveness of communication strategies.
03
The Emerging Visual Culture Requires New Paradigms of Thinking
Despite the various issues surrounding the visual advantage effect, its evident efficiency and potential influence cannot be overlooked. Responding to users’ changing information acquisition needs, media have been promoting video content as mainstream in recent years, with visualizations dominating communication. The emergence of social platforms over the past two decades and their visual turn has led to the ubiquity of visual information, with short videos flourishing in China. Globally, social media platforms like Facebook, YouTube, TikTok, and Instagram, with their vast user bases, provide extensive dissemination channels for video information.
Video has become an interface linking life and media, influencing people’s real existence and media expression; video has become a way of life, with short videos possessing a powerful visual capacity to construct social realities. Short videos create a strong sense of knowledge acquisition; however, this sense of acquisition does not equate to cognitive enhancement and may even affect deeper understanding processes.
As a new culture, the emerging visual culture demands new paradigms of thinking. Over the past decade, visual communication and visual cultural dissemination have increasingly concentrated in new media spaces, representing politics, society, economy, culture, and daily life. The field of news communication has extended historical visualization into a new era. From illustrations to photography, video, and now generative AI, the usage rates of tools for producing and editing images have steadily risen, benefiting various journalists.
For news professionals, AI can assist in visualizing difficult-to-illustrate stories. Generative AI can also be used to research stories and inspire creativity. They prefer to seek help from chatbots to choose challenging reporting topics. AI can also present past events in a narrative visualization manner through collaborative information. In this context, the news communication industry faces unique opportunities and challenges from planning, production, to editing and publishing processes.
The communication of the intelligent era requires a higher standpoint; we must understand how to optimize information dissemination, cultivate human cognition and judgment abilities, establish different preferences between text and images, and better combine communication. With the widespread application of visual information, we must be more cautious in balancing the dissemination of visual and textual information to avoid a binary opposition between the two; at the same time, we should strive to mobilize a balanced use of various modalities, aiming to optimize the effects of information dissemination and its cognitive impacts, and cultivate our cognitive and judgment abilities.
Specifically, we can approach the following aspects:
First, the combination of visuals and text is key to enhancing dissemination effectiveness. Cleverly combining the different dissemination advantages of visuals and text can better optimize information transmission. Visual information has immediacy and emotional impact; textual information is crucial for in-depth understanding of complex concepts. Therefore, balancing the dissemination of visual and textual information is essential to utilize visual effects to supplement and enhance the dissemination of textual information. This combined communication approach can maximize the advantages of both, enhancing the comprehensiveness and accuracy of information.
Second, emphasizing the context and interpretation of visual communication. When applying visual communication, especially visual content generated by generative AI, it is crucial to use text as a supplement, providing clear background and explanations to help audiences accurately understand information and ensure they grasp the full context of visual content. This avoids leading to misinterpretations or even emotional manipulation.
Third, cultivating discernment and user evaluation abilities. In today’s information explosion, while visual communication brings significant convenience, it can also lead to cognitive biases and exacerbate information fragmentation. Therefore, encouraging discernment is necessary, meaning audiences should be able to evaluate the authenticity and accuracy of information, be aware of potential biases, and actively avoid them. When faced with visual content generated by generative AI, users need to learn to distinguish between its authenticity and fabrication, understanding how to verify some conclusive data, thus making more informed judgments.
The application and impact of information modalities in communication under the context of generative AI deserve our serious exploration; how to balance the dissemination of visual and textual information, enhance and optimize users’ understanding of information, and aid human cognitive abilities and literacy requires continuous reflection and summarization in practice. It is necessary to cultivate users’ evaluation abilities regarding different modalities of information by providing sufficient contextual explanations and encouraging discernment, helping people understand complex information more accurately and comprehensively. In summary, all “actors” in this field—from intelligent technology companies, information platforms, media to general users—have the responsibility and obligation to seek the truth and optimize cognition.

This article is reproduced from the WeChat public account “News and Writing”