Skip to content
Recently, I have been unwell with a gastrointestinal flu for several days, but I am feeling better today and can update on the recent hot topics related to DeepSeek. I won’t go into much detail about the specific news regarding DeepSeek, but on New Year’s Eve, they launched Janus-Pro, and various media outlets have been extensively covering it. Nvidia’s stock price plummeted, and the Americans are starting to panic, calling for a new wave of PUA. However, in today’s China, is it really that simple to restrict us by just limiting a chip or investigating copyright issues? Without further ado, today we won’t discuss the news or the profound principles behind the models; instead, we will simply explain the differences between the recently released DeepSeek V3, R1, and Janus, so that beginners can quickly understand.
DeepSeek V3 was released on December 26 last year, which is actually just a month ago. At that time, the launch of V3 did not create as much of a stir as it has now. V3 is essentially a general-purpose large model with 671 billion parameters, more suitable for content generation scenarios such as text creation and question answering.
DeepSeek R1 was released ten days ago, on January 20 this year, and it is this model that has made DeepSeek a sensation. R1 is essentially an inference model, more suited for vertical scenarios, and focuses more on the analysis of questions, utilizing a chain of thought pattern to think like a human, providing a reasoning process that improves the accuracy of responses.
DeepSeek Janus-Pro was released at midnight on January 28, which is also New Year’s Eve, and Janus-Pro is essentially a multimodal large model, which means it can not only generate text but also images.
Why is DeepSeek so popular?
Having briefly explained the differences between the three recently released models, why has it become so popular? There are actually two main reasons: first, open source! open source! open source! It’s important to say it three times. After the release of DeepSeek R1, its performance directly competes with OpenAI’s o1, pulling OpenAI down from its pedestal. The chain of thought is no longer mysterious, and in some fields, such as coding and mathematics, it even outperforms OpenAI’s o1, with a faster inference speed. Second, the training cost is extremely low! The reason Nvidia’s stock price plummeted due to DeepSeek is that DeepSeek demonstrated that it does not require as much computing power (DeepSeek utilizes PTX programming to bypass CUDA monopolies, achieving a 10-fold increase in training efficiency) to train such an excellent large model, and it is also open source… Anyone can train it with low computing power without needing to buy so many Nvidia cards. You can imagine how Huang is feeling right now.
On New Year’s Eve, the last open-source release of Janus-Pro, although it only has a 7B version, outperforms OpenAI’s DALL-E 3 and Stable Diffusion in image generation.
Now, the open-source release of DeepSeek R1 has sparked a global replication craze, with researchers worldwide studying DeepSeek and attempting to replicate the R1 model. You can follow HuggingFace for updates.
Why didn’t DeepSeek V3 become popular, but R1 did, and why are there so many parameter versions of R1?
The reason is that DeepSeek V3 has a parameter scale of 671B, which is too large for most enterprises to run, hence it did not create much of a stir at the time. However, R1 is different; after its release, R1 has versions with 1.5B, 7B, 8B, 14B, 32B, 70B, and 671B parameters, with the smallest being only 1.5B, which can run locally. Apart from the 671B version, which belongs to the original R1 model (DeepSeek R1 released two models this time, one of which is R1 Zero, a model trained entirely on reinforcement learning without supervised fine-tuning; the true R1 model is based on supervised fine-tuning, providing better output quality and reasoning performance, involving cold start data and RHLF, which I will not elaborate on here, but both R1 Zero and R1 are based on the DeepSeek V3 Base model). The other six parameter versions are derived from Llama and Qwen through distillation. This also validates the possibility of distilling R1’s reasoning capability into smaller models, proving that distillation is more effective than direct reinforcement learning for small models, and the performance of the distilled small models has reached levels comparable to GPT-4o in many aspects.
 How to Use DeepSeek Models
If you want to experience it quickly, you can directly visit the DeepSeek official website to try out the latest R1 model, which is also available as a mobile app.
https://chat.deepseek.com/
Of course, you can also integrate the DeepSeek R1 API into your own business, and the cost is only 3% to 4% of the OpenAI o1 model. So in terms of performance, it is on par with o1, priced at only one-thirtieth of o1, and without being restricted by American regulations, who would you choose to call? (Actually, I am a bit worried if DeepSeek’s computing power can handle it.)
If you want to quickly run the DeepSeek R1 locally, just go on Ollama; most people can run the 14B level locally. Of course, you can also download and run it directly from HuggingFace, but it is a bit more complicated than Ollama.
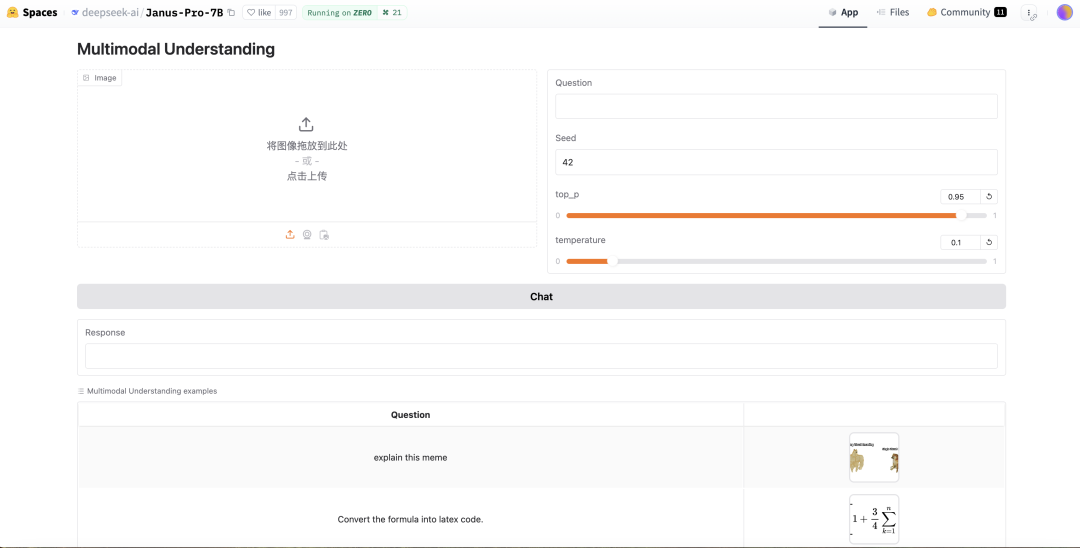
If you want to run DeepSeek Janus-Pro, it is a bit more complicated; the model itself is not large (with versions of 1B and 7B), and it is recommended to use Gradio to run it. You can refer to the official GitHub for specific steps:
https://github.com/deepseek-ai/Janus
You can also directly run the official Janus-Pro-7B Gradio Demo on HuggingFace:
https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
I just discovered that there is now even a ComfyUI version available; the netizens are really fast. I haven’t tried it, but it should work well, and everyone can give it a try.
https://github.com/CY-CHENYUE/ComfyUI-Janus-Pro
Cool Thoughts in the Heat of the Moment
At the end of the article, I would like to share my overall thoughts on this matter. Although DeepSeek is currently very popular and has attracted global attention, and various news outlets are praising DeepSeek, foreign media are relatively objective in their evaluation and analysis of the situation, while domestic media seem to be overzealous. The Americans have already started a new round of suppression, with various long articles of PUA. In the future, it will become increasingly difficult for China to catch up to the United States in AI. DeepSeek itself has also called for everyone to view the recent events calmly and not be arrogant, but to remain rational. Looking at the AI wave, a new focus tends to emerge every once in a while, so the current wave of DeepSeek is bound to pass quickly, and even more impressive AI products and technologies will appear in the future. However, it must be said that this wave of DeepSeek has indeed achieved a remarkable turnaround for China, attracting significant attention from the United States, and it is a victory of open source over closed source, allowing more people to master advanced technology. But let’s be realistic; the chip issue has not been resolved, and we still rely on Nvidia’s cards at this stage. So, let us continue to look forward to when good news will come regarding China’s chips!
For more exciting content, feel free to scan the code to joinfreeKnowledge Planet
to build geek culture together.
How to Use DeepSeek Models
If you want to experience it quickly, you can directly visit the DeepSeek official website to try out the latest R1 model, which is also available as a mobile app.
https://chat.deepseek.com/
Of course, you can also integrate the DeepSeek R1 API into your own business, and the cost is only 3% to 4% of the OpenAI o1 model. So in terms of performance, it is on par with o1, priced at only one-thirtieth of o1, and without being restricted by American regulations, who would you choose to call? (Actually, I am a bit worried if DeepSeek’s computing power can handle it.)
If you want to quickly run the DeepSeek R1 locally, just go on Ollama; most people can run the 14B level locally. Of course, you can also download and run it directly from HuggingFace, but it is a bit more complicated than Ollama.
If you want to run DeepSeek Janus-Pro, it is a bit more complicated; the model itself is not large (with versions of 1B and 7B), and it is recommended to use Gradio to run it. You can refer to the official GitHub for specific steps:
https://github.com/deepseek-ai/Janus
You can also directly run the official Janus-Pro-7B Gradio Demo on HuggingFace:
https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
I just discovered that there is now even a ComfyUI version available; the netizens are really fast. I haven’t tried it, but it should work well, and everyone can give it a try.
https://github.com/CY-CHENYUE/ComfyUI-Janus-Pro
Cool Thoughts in the Heat of the Moment
At the end of the article, I would like to share my overall thoughts on this matter. Although DeepSeek is currently very popular and has attracted global attention, and various news outlets are praising DeepSeek, foreign media are relatively objective in their evaluation and analysis of the situation, while domestic media seem to be overzealous. The Americans have already started a new round of suppression, with various long articles of PUA. In the future, it will become increasingly difficult for China to catch up to the United States in AI. DeepSeek itself has also called for everyone to view the recent events calmly and not be arrogant, but to remain rational. Looking at the AI wave, a new focus tends to emerge every once in a while, so the current wave of DeepSeek is bound to pass quickly, and even more impressive AI products and technologies will appear in the future. However, it must be said that this wave of DeepSeek has indeed achieved a remarkable turnaround for China, attracting significant attention from the United States, and it is a victory of open source over closed source, allowing more people to master advanced technology. But let’s be realistic; the chip issue has not been resolved, and we still rely on Nvidia’s cards at this stage. So, let us continue to look forward to when good news will come regarding China’s chips!
For more exciting content, feel free to scan the code to joinfreeKnowledge Planet
to build geek culture together.