In the era of large models, many new terms have emerged, and RAG is one of them. This article from the tech community, “Understanding RAG (Retrieval Augmented Generation) in One Article,” explains what RAG is, its functions, and the associated challenges.
Related historical articles on large models,
“How to Achieve Efficient GPU Resource Scheduling with Kubernetes?”
“How to Improve GPU Utilization?“
“Getting Started with AI Agents”
“Top-level Architecture Design Experience for Enterprise Large Model Applications“
“Bare Metal GPU vs Virtual GPU, How to Choose?“
“Understanding NVIDIA CUDA“
“How to Choose Between GPU and CPU?“
“Discussion on Regulatory Data Security for Large Models”
“Understanding GPU Technology“
“Opportunities and Challenges in Financial Large Model Applications“
“How Much Resources Are Needed to Build a Large Model from Scratch?“
Before the arrival of the era of LLMs (Large Language Models), we typically expanded the model’s capabilities with new data through simple fine-tuning. However, the models we use today are becoming larger, and the amount of data used for training is increasing, making it impossible to rely solely on fine-tuning to meet the needs of most scenarios. Although fine-tuning performs well in adjusting the model’s tone and style, its effect becomes weak when adding a large amount of new knowledge to the model.
For example, with OpenAI’s GPT-3.5-turbo (ChatGPT) model, if we input the question “Can you tell me about tents for cold weather?” the completion model might reply by expanding the prompt: “and any other camping equipment for cold weather?” while the chat model would give a more human-like response: “Of course! They are designed to withstand low temperatures, strong winds, and snow…” In this case, OpenAI’s focus is not on updating the knowledge base accessible to the model but on changing how the model interacts with the user. For tasks like adjusting the model’s style and tone, fine-tuning has indeed shown excellent results.
However, for the more common business need of adding new knowledge to large models, the effect of fine-tuning appears inadequate. Additionally, fine-tuning LLMs requires a large amount of high-quality data, a considerable budget for computing resources, and a long training time, which are scarce resources for most users and often cannot be met.
Therefore, we need an alternative technology to efficiently integrate new knowledge into large language models. Fortunately, the “Retrieval Augmented Generation” (RAG) technology proposed by Facebook AI Research (FAIR) and its collaborators in 2021 can solve this problem.
RAG (Retrieval Augmented Generation) is an innovative technology designed to enhance the accuracy and reliability of generative AI models by integrating external knowledge sources. This approach addresses an inherent flaw of large language models (LLMs): while LLMs excel at capturing statistical patterns in language, they lack a deep understanding of specific factual knowledge.
In fact, beneath the hood of LLMs, their core is based on deep neural networks, often measured in terms of the vast number of parameters that represent the model’s capabilities. These parameters encapsulate the general patterns and rules of constructing sentences in human language, providing a parameterized understanding of natural language processing. It is this profound, implicit language understanding that allows LLMs to respond fluently and rapidly to various general prompts.
However, when users want to delve deeper into a current topic or specific field, relying solely on the built-in parameterized knowledge of LLMs proves insufficient. After all, any static model and training database are limited and cannot cover all the latest, specialized, and nuanced points of knowledge. This leads to LLMs providing inaccurate and inconsistent responses when handling certain specific queries, undermining their reliability.
The RAG technology was born to overcome this inherent weakness of LLMs. The core idea is to combine LLMs with external knowledge sources, allowing the model to respond and generate not only based on internal parameterized knowledge but also on the latest authoritative knowledge from external sources.
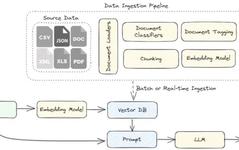
Advanced RAG Architecture Reference Diagram
As an innovative technology, although the implementation details of RAG may vary across different systems, conceptually, applying RAG to AI-based applications usually involves core steps such as query input, retrieval, prompt construction, response generation, and feedback. Through these steps, RAG technology cleverly combines LLMs with external knowledge sources, allowing the model to rely not only on its internal parameterized language understanding capabilities but also on the latest authoritative knowledge retrieved to enhance reasoning and generation, significantly improving the accuracy and richness of responses.
It is worth mentioning that the RAG framework provides ample customization space for users. In practical applications, developers can choose different knowledge base data sources, retrieval algorithms, and strategies based on specific needs, further optimizing the system’s retrieval quality and generation performance. Additionally, the methods and forms of prompt construction can also be optimized according to specific scenarios to maximize the potential of LLMs.
LLMs (Large Language Models) have gained widespread attention due to their powerful performance, but they also expose some inherent flaws. One prominent issue is the need for improved consistency and reliability in output responses. While LLMs can provide accurate answers to some questions, they often regurgitate random facts from the training data when faced with other questions. The fundamental reason for this phenomenon is that LLMs primarily capture statistical relationships between words and do not truly understand semantic meanings.
To address the inconsistencies in LLM responses and enhance their reliability, researchers have developed an innovative framework called “Retrieval Augmented Generation” (RAG). The core idea of RAG is to enhance the quality of LLM-generated responses by combining external knowledge sources. This method not only ensures that LLMs have access to the latest and most reliable factual knowledge but also allows users to demand and verify the accuracy and credibility of the model’s output based on actual needs.
Typically, the RAG framework revolves around two core elements:
1. Retrieval
In this step, RAG retrieves highly relevant text fragments from a pre-built knowledge base (such as Wikipedia, professional literature, etc.) based on the user’s input query. The construction of the knowledge base is crucial and must include the latest, authoritative, and professional information sources to ensure retrieval quality.
2. Generation
After obtaining relevant texts, RAG combines the user’s original query with the retrieved text information and feeds it into the LLM for comprehensive processing and understanding, ultimately generating high-quality response outputs that meet user needs.
Through the close integration of these two steps, the RAG architecture empowers LLMs with the ability to access external knowledge, fundamentally solving the singularity and limitations of relying solely on internal training data. At the same time, RAG also provides users with more control and customization space, allowing them to choose appropriate knowledge bases and retrieval strategies according to different scenario needs, further optimizing the model’s output quality.
It is worth mentioning that as an innovative framework, RAG not only improves the consistency and reliability of LLM outputs but, more importantly, opens up pathways for large language models to integrate external knowledge and continuously learn and evolve. At the current stage of AI development, how to enable LLMs to transcend the limitations of static knowledge bases and possess the ability for continuous learning and knowledge accumulation is one of the major challenges that need to be addressed. The emergence of RAG provides strong support for this goal and opens up a new direction for LLMs to evolve into truly general artificial intelligence systems.
Currently, research and applications based on the RAG framework are actively unfolding in various fields, including intelligent question-answering systems, intelligent writing assistance, knowledge graph construction, etc. More and more tech giants and startups are exploring and practicing the possibilities of integrating RAG into their products and services. It is believed that in the near future, RAG and its variants will become one of the key driving forces to enhance LLM capabilities and promote AI development.
In the future, as more innovative technologies emerge, RAG will continue to develop and evolve. For instance, the combination with memory-augmented generation (Memory Augmented Generation) and other memory modules will endow LLMs with long-term memory and knowledge accumulation capabilities; furthermore, the introduction of knowledge tracing technology will enable LLMs to actively learn new knowledge and continuously expand their knowledge network. Thus, to some extent, it can be anticipated that RAG, combined with more advanced technologies, will be endowed with more powerful capabilities, fully unleashing the immense potential of LLMs, ultimately driving intelligent systems toward true general artificial intelligence.
Compared to traditional methods, one major innovation of RAG is that it does not directly modify or fine-tune the model parameters of LLMs themselves, but integrates LLMs as a component of the system, closely coupling them with document storage and retrieval modules. This “insertable” design retains the original language generation capabilities of LLMs while endowing them with new skills to access external knowledge, avoiding the expensive computational resource costs required for completely retraining the model.
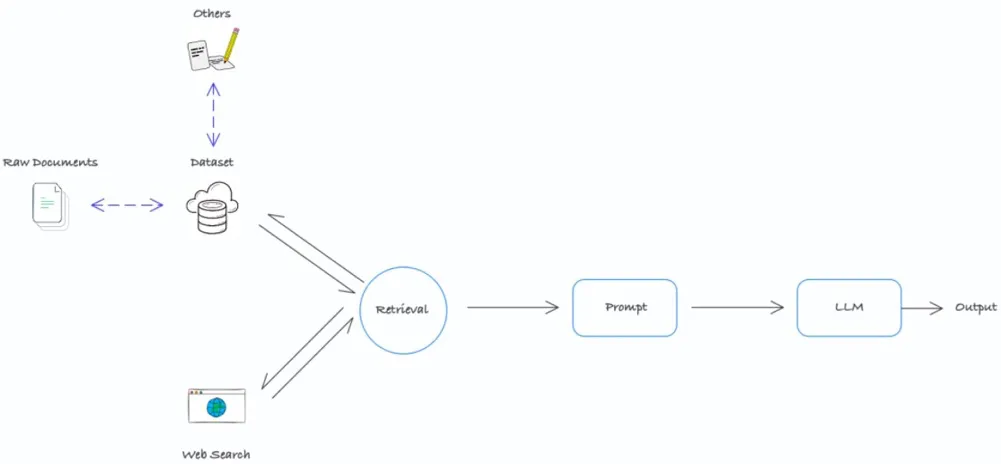
Basic Working Principle Reference Diagram of RAG (Retrieval Augmented Generation)
The Retrieval Augmented Generation (RAG) technology injects the ability to access external knowledge into large language models (LLMs), fully leveraging the collaborative advantages of LLMs in generating high-quality responses and the rich information of external knowledge bases. When we perform relevant query operations, RAG completes a series of key steps behind the scenes of LLMs, ensuring the accuracy and relevance of the final response.
Generally speaking, the workflow of RAG involves several key stages, which can be summarized as follows:
1. Document Retrieval
When an input query or prompt is given, the RAG system first searches for highly relevant contextual information in the pre-built document repository. This repository usually consists of digitized text files covering a wide range of professional fields and knowledge topics.
In this repository, each document is divided into multiple semantic units (chunks) and converted into vector form using natural language processing techniques, corresponding to the semantic meanings of each unit. These vector representations and their metadata are stored in an efficient vector database. RAG uses leading semantic retrieval algorithms to calculate the semantic vector representation based on the queries we provide and seeks the most similar text blocks in the vector space, thus accurately retrieving contextual information highly relevant to our needs from vast amounts of data.
2. Prompt Construction and Enhancement
After obtaining relevant text blocks, RAG cleverly merges our initial query with this contextual information to construct a rich and meaningful LLM prompt. The goal of this step is to provide LLMs with sufficient information sources to guide them in generating high-quality responses that meet your needs.
During the prompt construction process, RAG can adopt various strategies, such as simple concatenation, injection prompts, summary prompts, etc., to ensure that the contextual information can be effectively captured and utilized by LLMs. Additionally, RAG can incorporate some auxiliary explanations and annotations to further enhance the guiding role of the prompt.
3. LLM Response Generation
Once the enriched prompt is fed into the LLM, the model considers the query itself, related contextual knowledge, and its internal parameterized language understanding capabilities to generate the final response to our questions or needs through deep learning and reasoning.
It is worth noting that by integrating external knowledge sources, RAG endows LLMs with more accurate and targeted generation capabilities. The responses from LLMs are no longer limited to the finite knowledge of their training sets but are customized based on relevant information for specific scenarios and needs. This makes the output of the RAG system not only rich in information and detailed but also highly relevant to our specific queries, greatly improving interpretability and reliability.
4. Response Output and Feedback
The responses generated by LLMs are the final output of the RAG process, and the system presents them to us in an appropriate form. At the same time, RAG provides users with a convenient feedback mechanism, allowing us to evaluate the quality of the system’s output as needed. This feedback will be used for the continuous optimization of RAG’s retrieval, construction, and generation strategies.
In summary, RAG cleverly combines LLMs with advanced semantic retrieval and vector database technologies, opening up pathways for LLMs to access external knowledge. By fully utilizing the informational value of specialized knowledge bases, RAG not only significantly enhances the accuracy and relevance of LLM outputs but, more importantly, paves the way for language models to achieve continuous learning and proactive knowledge acquisition, laying the foundation for their ultimate realization of general artificial intelligence.
The Retrieval Augmented Generation (RAG) architecture consists of the following key elements that collectively empower language models to access and utilize external knowledge:
1. Vector Database
A high-performance vector database is the core infrastructure of the RAG system. It enables fast and efficient similarity searches by storing the semantic vector representations of documents, ensuring timely access to the latest and most relevant information sources.
2. Prompt Engineering
Prompt engineering is a crucial aspect of the RAG architecture. By carefully designing instructions, RAG can guide large language models (LLMs) to focus on the provided contextual content, generating high-quality, expected responses.
3. ETL Pipeline
The ETL (Extract, Transform, Load) pipeline is responsible for processing raw data, including deduplication, update insertion (Upsert), and necessary transformations like text chunking and metadata extraction, to ensure data is stored in the optimal format in the vector database.
4. LLM
The RAG architecture can be compatible with various LLM models, including commercial closed-source models and open-source models. Developers can choose the appropriate LLM as the core generation engine of the RAG system based on specific needs.
5. Semantic Cache
The semantic cache (e.g., GPT Cache) reduces the computational overhead of the system by storing the historical responses of LLMs, improving response performance. This is particularly important for large-scale applications and cost-sensitive scenarios.
6. RAG Toolset
Third-party RAG toolsets (such as LangChain, LlamaIndex, Semantic Kernel, etc.) provide convenience for building and deploying RAG models, often featuring good compatibility with LLMs.
7. Evaluation Tools and Metrics
Evaluation tools and metrics (such as TruLens, DeepEval, LangSmith, Phoenix, etc.) are crucial for monitoring and optimizing the performance of RAG systems. They combine various evaluation metrics and assist LLMs to help comprehensively analyze the quality of system outputs.
These elements work collaboratively to construct a complete closed loop of the RAG architecture. Among them, the vector database and semantic cache provide efficient pathways for LLMs to access external knowledge; prompt engineering ensures that LLMs can fully utilize the provided contextual information; the ETL pipeline is responsible for cleaning and preprocessing raw data to provide high-quality knowledge sources for the system; third-party toolsets simplify the construction and deployment of RAG systems; while evaluation tools and metrics support the continuous optimization and improvement of the system.
It is worth mentioning that the RAG architecture not only injects external knowledge acquisition capabilities into LLMs but also opens the door for continuous learning and self-evolution. In the future, with the integration of memory enhancement, meta-learning, automatic knowledge base construction, and other cutting-edge technologies, RAG is expected to endow language models with true proactive learning capabilities, allowing them to continuously absorb new knowledge, expand and optimize their internal knowledge bases, ultimately breaking through the limitations of static knowledge bases and becoming intelligent agents with general intelligence.
Moreover, the RAG architecture itself is continuously evolving. An increasing number of innovative mechanisms and technologies are being introduced, such as multimodal knowledge fusion, context-aware prompt optimization, distributed heterogeneous knowledge base integration, and human feedback-based interactive learning, significantly expanding the application scenarios and capabilities of RAG.
The RAG architecture provides LLMs with a new mechanism for knowledge injection and updating, helping to address some of the inherent limitations of traditional LLMs.
In the traditional LLM training process, the parameterized knowledge of the model is static and fixed, and once training is complete, it cannot be directly updated. This means that even if the foundational knowledge base changes, LLMs cannot autonomously absorb new knowledge; the only way is to retrain the model from scratch, which is undoubtedly costly and inefficient.
In contrast, the RAG architecture provides LLMs with a new dynamic path for acquiring external knowledge. By integrating advanced semantic retrieval and vector database technologies, RAG enables LLMs to directly access the latest and most relevant knowledge sources when answering queries without any modifications or retraining of the model itself. As long as the knowledge base is continuously updated, the output responses of LLMs will automatically reflect the latest state of knowledge, maintaining high timeliness and accuracy.
More importantly, the RAG architecture gives LLMs a new response mode—Source-grounded Generation. In this mode, the replies from LLMs are strictly confined to the range of contextual knowledge provided, which helps reduce the risk of hallucination and increase the reliability of outputs.
This feature can not only be applied to large general LLMs but also fosters the emergence of a class of small, efficient LLMs specialized in specific domains. These models only need to acquire general language knowledge during training, while specialized domain knowledge comes from dynamically provided knowledge sources through the RAG pipeline, thus achieving a streamlined model structure and reduced training costs while retaining high quality and professionalism in output.
Another prominent advantage is that the RAG architecture can provide clear source tracing functionality for the output responses of LLMs. In other words, the system not only generates high-quality reply content but also outputs the specific knowledge sources and evidence paths contributing to that reply. This enhances the interpretability and traceability of system outputs, helping to identify and diagnose potential hallucination behaviors of LLMs; on the other hand, it also provides strong technical support for regulatory compliance in sensitive areas, ensuring the auditability of knowledge sources.
However, in practical applications and future developments, this innovative technology still faces a series of significant challenges that need urgent resolution.
These challenges involve key areas such as knowledge base construction, retrieval algorithms, prompt engineering, interpretability techniques, privacy and security, and system efficiency. We need to invest more research and development resources to continuously focus on and delve into these key areas to promote further breakthroughs and innovations in technology. Only by continuously overcoming these challenges can we achieve the comprehensive application and development of the technology.
If you find this article helpful, please don’t hesitate to click “Like” and “See” at the end of the article, or directly share it in your circle of friends.
