Click the "Xiaobai Learns Vision" above, select to add "Star" or "Top"
Heavyweight content delivered to you first

Editor’s Recommendation
Object Detection is a popular direction in the field of Computer Vision, widely used in autonomous driving, industrial inspection, video surveillance, and aerospace, among others. Its basic process involves locating the target of interest in a given image, determining the target category, and outputting the corresponding coordinates (often using rectangular boxes).
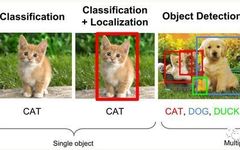
Image classification, object detection, and segmentation are the three main tasks in the field of computer vision:
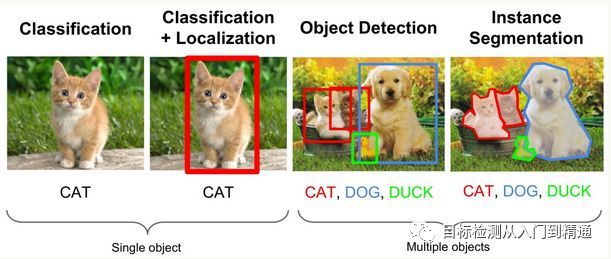 Three Levels of Image Understanding
Three Levels of Image Understanding
1. Classification, which describes the input image and assigns the most fitting label from a set of existing class labels to that image. Although classification is the simplest and most fundamental image understanding task, it lays the groundwork for other more complex tasks.
2. Detection, which focuses more on the target compared to classification tasks, requires obtaining both the category and location information of the target (Classification + Localization).
3. Segmentation, which includes Semantic Segmentation and Instance Segmentation. The former is an extension of the foreground-background separation task, requiring every pixel in the image to be labeled as a certain object category, without needing to separately segment different instances of the same object; while the latter is an extension of the detection task, a combination of object detection and semantic segmentation, requiring precision down to the edges of the object (more detailed than object recognition boxes). In contrast to semantic segmentation, instance segmentation can label different individuals in an image.

Comparison between Semantic Segmentation and Instance Segmentation
Image classification divides images into single categories (generally corresponding to the most prominent objects), but most images in the real world usually contain more than one object. If a classification model is forced to classify, the results may not be accurate. In such cases, object detection algorithms are needed. Currently, the academic and industrial fields mainly classify object detection algorithms into three categories:
1. Traditional Object Detection Frameworks
(1) Candidate region selection (using sliding windows of different sizes and ratios to traverse the image);
(2) Feature extraction for different candidate regions (SIFT, HOG, etc.);
(3) Using classifiers for classification (SVM, Adaboost, etc.).
2. Two-Stage Object Detection Frameworks based on Deep Learning (which have accuracy advantages)
This type of algorithm divides the detection problem into two stages: the first stage generates a large number of candidate regions that may contain targets (Region Proposal) and attaches approximate location information; the second stage classifies these regions, selects the candidate regions containing targets, and corrects their locations (commonly using R-CNN, Fast R-CNN, Faster R-CNN algorithms).
3. One-Stage Object Detection Frameworks based on Deep Learning (which have speed advantages)
This type of detection algorithm is end-to-end and does not require the generation of a large number of candidate regions. Instead, it transforms the problem into a regression problem, using the complete image as input and directly regressing the target bounding box and category at multiple locations in the image (commonly using Yolo, SSD, CornerNet algorithms).
Summary
Future work will mainly focus on the trade-off between speed and accuracy.For detailed introductions to various object detection algorithms, please refer to other articles on the public account.
Good news!
Xiaobai Learns Vision Knowledge Circle
Is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of "Xiaobai Learns Vision" public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering installation of extension modules, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, and more than 20 chapters.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of "Xiaobai Learns Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and facial recognition, to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV, achieving advanced OpenCV learning.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually subdivide later). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, you will not be approved. After successfully adding, you will be invited to related WeChat groups based on your research direction. Please do not send advertisements in the group; otherwise, you will be removed. Thank you for your understanding~