

GPT-3 has caused a global sensation in the tech community, and almost everyone with a basic understanding of AI knows about it. Discussions surrounding it remain very active to this day. This article aims to provide a brief introduction to GPT-3, hoping to give everyone a real glimpse of what GPT-3 is.
First, you might want to know why GPT-3 has caused such a huge sensation and what it can do. Simply put, GPT-3, as an unsupervised model (now often referred to as a self-supervised model), can accomplish almost all tasks in natural language processing, such as question answering, reading comprehension, semantic inference, machine translation, article generation, and automatic Q&A, among others. Moreover, this model performs exceptionally well on many tasks, achieving state-of-the-art performance in French-English and German-English machine translation tasks. The automatically generated articles are almost indistinguishable from those written by humans (with only a 52% accuracy rate, comparable to random guessing). Even more surprisingly, it achieves nearly 100% accuracy on two-digit addition and subtraction tasks and can automatically generate code based on task descriptions. The effectiveness of an unsupervised model seems to give people hope for general intelligence, which is likely the main reason for GPT-3’s significant impact.
Next, you might want to understand what the GPT-3 model actually is. In fact, GPT-3 is simply a statistical language model. From a machine learning perspective, a language model is a model that predicts the probability distribution of sequences of words, using previously spoken segments as conditions to predict the probability distribution of different words appearing at the next moment. A language model can measure how well a sentence conforms to language grammar (for example, assessing whether the responses generated by a human-computer dialogue system are natural and fluent) and can also be used to predict and generate new sentences. For example, for the segment “It’s noon, let’s go to the restaurant,” the language model can predict the words that might follow “restaurant.” A general language model would predict the next word as “eat,” while a powerful language model can capture time information and predict the contextually appropriate words like “have lunch.”

Typically, whether a language model is powerful depends on two factors: First, whether the model can utilize all historical contextual information. In the example above, if it cannot capture the distant semantic information of “noon,” the language model would struggle to predict the next word “have lunch.” Second, whether there is enough rich historical context for the model to learn from, meaning whether the training corpus is sufficiently rich. Since language models belong to self-supervised learning, the optimization goal is to maximize the language model probability of the text seen, so any text can serve as training data without labeling.
First, let’s see how a language model calculates the probability of a sentence:
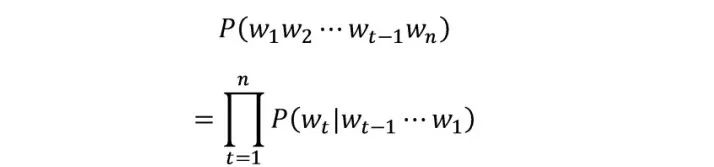
The core of the above calculation formula is modeling historical information, that is, how to calculate conditional probabilities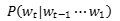 , before deep learning, language models almost all used discrete symbol matching methods,
, before deep learning, language models almost all used discrete symbol matching methods, 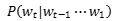
Usually obtained by maximum likelihood estimation:
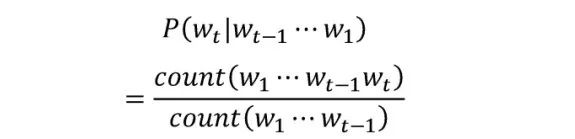
Since longer word strings have a lower probability of occurrence (for example, even with a lot of data, a sentence with exactly 100 words is rarely seen), 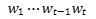 often encounters cases where the occurrence count is zero. To avoid this issue, traditional language models usually use n-grams, meaning the probability of the next word only depends on the previous n-1 words.
often encounters cases where the occurrence count is zero. To avoid this issue, traditional language models usually use n-grams, meaning the probability of the next word only depends on the previous n-1 words.
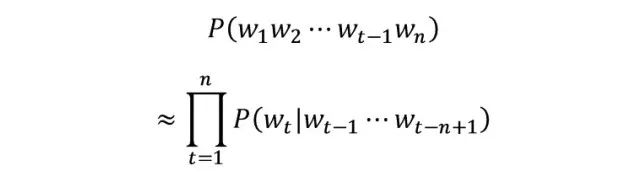
In this way, the language model only needs to model the historical information of the previous n-1 words:
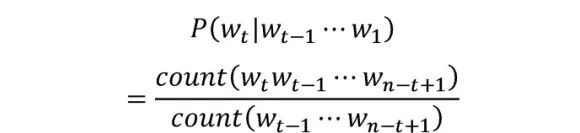
Clearly, relying solely on the traditional language model based on the previous n-1 words cannot fully utilize complete historical information, and the discrete symbol matching paradigm can lead to semantic gap issues. For example, if we replace “restaurant” with “canteen” in the above example, the traditional language model would treat “It’s noon, let’s go to the restaurant” and “It’s noon, let’s go to the canteen” as two completely different historical contexts, leading to potentially vastly different predictions of subsequent words.
After deep learning was introduced into natural language processing, the shift from discrete symbol representation systems to distributed continuous real-valued vector representation systems was crucial. All words, such as “noon,” “we,” “restaurant,” and “canteen,” are represented using low-dimensional continuous real-valued vectors, and semantically similar words are also close together in vector space. Under the distributed representation system, theoretically, “It’s noon, let’s go to the restaurant” and “It’s noon, let’s go to the canteen” would also be very close in vector space, but whether a neural network can model the complete historical contextual semantic information also depends on the model architecture.
For a long time, recurrent neural networks were the preferred choice for language models to learn historical information. As shown in the figure above, through iterative loops, all historical information can be continuously accumulated. However, due to the nature of stepwise information transfer,  information needs n steps to be transmitted to the nth moment, which is not only inefficient but also leads to issues like gradient vanishing, causing
information needs n steps to be transmitted to the nth moment, which is not only inefficient but also leads to issues like gradient vanishing, causing  to completely lose information after a few steps, making it difficult to learn the complete historical contextual information effectively.
to completely lose information after a few steps, making it difficult to learn the complete historical contextual information effectively.
Compared to its predecessors
What makes it so exceptional?
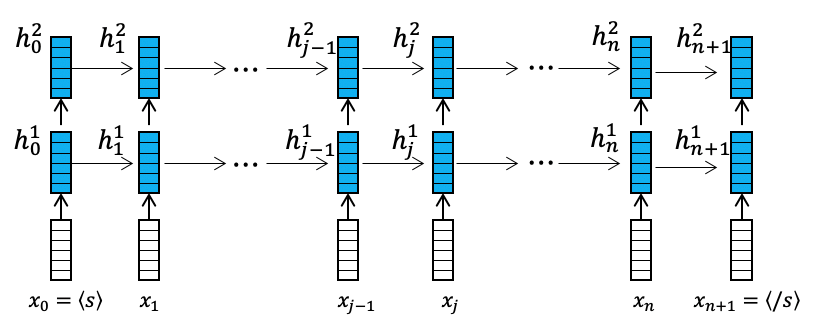
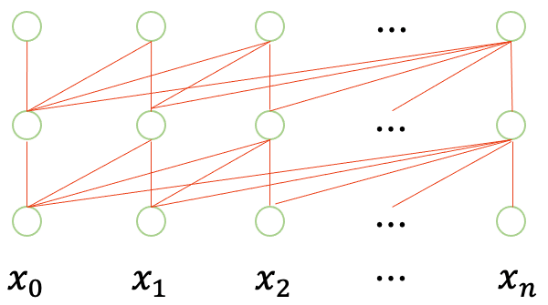
The series of models, including GPT, GPT-2, and GPT-3, adopt a transformer-based autoregressive decoder network architecture with a complete attention mechanism. As shown in the figure below, when capturing any historical information at the nth moment, it directly uses  and
and 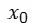 ,
, 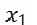 , …
, …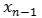 ,
, 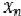 to perform one-to-one relevance calculations of semantic representations at each moment and utilize the relevance (i.e., attention weights) to weight all historical semantic representations to obtain complete historical semantic information. It can be seen that any span of information transfer only requires one computational step, ensuring both efficiency and modeling capability. After learning through multiple layers of networks, historical contextual information is continuously abstracted and integrated, allowing for accurate predictions of subsequent words.
to perform one-to-one relevance calculations of semantic representations at each moment and utilize the relevance (i.e., attention weights) to weight all historical semantic representations to obtain complete historical semantic information. It can be seen that any span of information transfer only requires one computational step, ensuring both efficiency and modeling capability. After learning through multiple layers of networks, historical contextual information is continuously abstracted and integrated, allowing for accurate predictions of subsequent words.
The architecture of the GPT-3 model is almost identical to that of GPT and GPT-2, so why is GPT-3 widely regarded as a breakthrough? This is mainly attributed to the two factors that determine the capabilities of language models.
On one hand, although the GPT-3 model continues to use the network architecture of complete attention mechanism like GPT and GPT-2 to learn historical contextual information, it has a much larger network hierarchy, with 96 layers and each layer having a representation dimension of 12,288, totaling 175 billion parameters (more than the number of neurons in the human brain). If each parameter is stored using single precision (4 bytes), the model requires 700GB of memory for storage. It can be said that the complete attention mechanism lays a theoretical foundation for effectively capturing historical information, while the enormous network hierarchy and parameter scale push the model’s capabilities to the limit.
On the other hand, in order to simulate sufficiently rich contextual information for the language model, GPT-3 uses almost all textual data from the internet as training corpus, with the filtered training data reaching 500 billion words, of which the vast Wikipedia data accounts for only 0.6%. It can be said that almost all recorded information (including various task execution methods) has been encoded into the GPT-3 model, so it is not surprising that GPT-3 can perform many tasks with high quality.
With so many tasks,
How does GPT-3 manage to do it?
In fact, we have yet to answer a key question: How can a language model simultaneously complete multiple tasks such as reading comprehension, automatic Q&A, machine translation, arithmetic operations, and code generation? This brings us to the philosophical idea that GPT-3 has always adhered to: transforming all natural language processing tasks into language model tasks, which means unified modeling for all tasks, treating task descriptions and task inputs as the historical context of the language model, while the output is the future information that the language model needs to predict. As shown in the figure below, whether it is sentiment classification, automatic Q&A, arithmetic operations, or machine translation tasks, they can all be formalized as language generation problems.
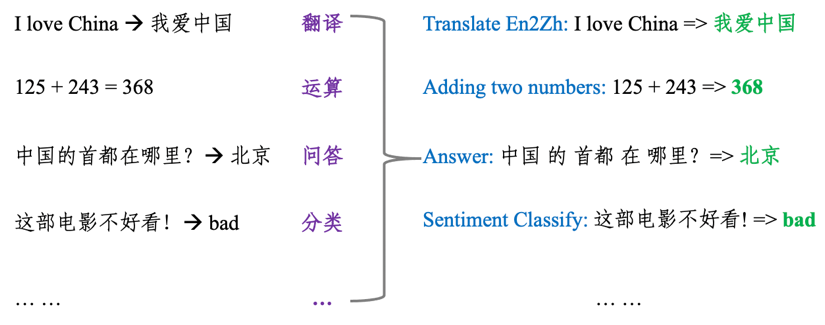
For example, in the case of arithmetic operations, the task description is “Adding two numbers:”, the task input is “125+243”, and the correct output should be “368”. In this task, the task description and task input can be seen as the historical context information of the language model, and the next predicted word generated by the language model, “368,” is the result of the arithmetic operation.
By now, you may still have a question: How does the unsupervised model GPT-3 recognize and execute different tasks? Since the GPT-3 model was trained using data from the entire internet, various task descriptions and examples have almost all appeared in the training data (to put it simply, there is nothing new under the sun). For example, there are numerous teaching samples online: Adding two numbers: 324+256=>580, 82+31=>113, 15+46=>61, … Therefore, the language model GPT-3 is able to learn the meaning of tasks and the way to predict numbers as well as some generalization capabilities in addition. If during testing, additional examples are provided between the task description and task input, such as “Adding two numbers: 12+21=>33, 42+34=>76, 52+26=>78, 24+37=>”, then the GPT-3 model has more historical context information to predict the result of “24+37.” This is the main reason why GPT-3 performs exceptionally well with few-shot examples.
Of course, GPT-3 still has many issues, shortcomings, or areas for improvement, including:
(1) Inconsistency in long text generation, i.e., logical inconsistencies;
(2) No common sense reasoning ability;
(3) Poor semantic reasoning;
(4) Model and results are not interpretable;
(5) Unreliable model predictions;
(6) Data bias leading to prediction bias;
(7) Lack of continuous learning and self-learning capabilities, etc.
Additionally, the compression of the GPT-3 model and optimization for specific tasks will also receive increasing attention.
Feel free to leave a message in the background, recommend topics, content, or information you are interested in!
If you need to reprint or submit articles, please send a private message in the background.

