
Originally from AI Technology Online
GANs (Generative Adversarial Networks) have completely revolutionized the field of machine learning, enabling computers to generate highly realistic data, such as images, music, and even text.
GANs are a class of machine learning models designed to generate realistic data. Whether it’s creating lifelike images, composing captivating music, or generating convincing text, GANs possess astonishing capabilities, seemingly simulating human creativity.
In this article, we will delve into their architecture and explore their main components and how they work.

Table of Contents:
-
What Are Generative Adversarial Networks (GANs)?
-
GANs Architecture
-
Deep Convolutional GANs (DCGANs)
-
Discriminator Network
-
Generator Network
1. What Are Generative Adversarial Networks (GANs)?
GANs were introduced in a paper titled “Generative Adversarial Networks” by Ian Goodfellow and other researchers from the University of Montreal in June 2014.
The most notable feature of GANs is their ability to create hyper-realistic images, videos, music, and text. GANs can learn features from training images and use these learned patterns to imagine their own new images. For example, the image shown in Figure 1 was generated using the GANs model.

Figure 1 Image generated using GANs model
For a long time, humans have had the advantage in imagination and creation, while computers excelled at solving regression, classification, and clustering problems. However, with the introduction of generative networks, researchers have been able to enable computers to generate content that is of the same or even higher quality than that created by humans.
By teaching computers to mimic any data distribution, they can be trained to create worlds similar to ours in various domains: images, music, language, and prose. In a sense, they are like robotic artists whose outputs are impressive.
GANs are also seen as an important step toward achieving Artificial General Intelligence (AGI), which is an artificial system capable of matching human cognitive abilities and acquiring expertise in almost any field (from images to language to the creativity required to compose sonnets).
First, we will provide an overview of GANs and their main components, then we will explore how to train and evaluate them, and finally, we will implement and train an end-to-end GAN model from scratch.
2. GANs Architecture
GANs are based on the idea of adversarial training. They essentially consist of two competing neural networks. This competition helps them mimic any data distribution.
We can imagine the GAN architecture as a fight between two boxers. As they conquer the game, both sides learn each other’s moves and techniques. They start with little understanding of their opponent. As the game progresses, they learn and get better.

Figure 2 Imagine the GAN architecture as a fight between two boxers
Another analogy that helps understand the idea of GANs: imagine GANs as a forger and a police officer in a cat-and-mouse game, where the forger is learning to create counterfeit money, while the police officer is learning to detect it. Both sides are dynamically changing.
This means that as the forger learns to perfect the production of counterfeit money, the police officer is also training and getting better, with both sides continuously learning from each other’s methods.
The GAN architecture consists of two main networks:
1. Generator: Attempts to convert random noise into observations that look like they are sampled from the original dataset.
2. Discriminator: Attempts to predict whether an observation is from the original dataset or a forgery from the generator.
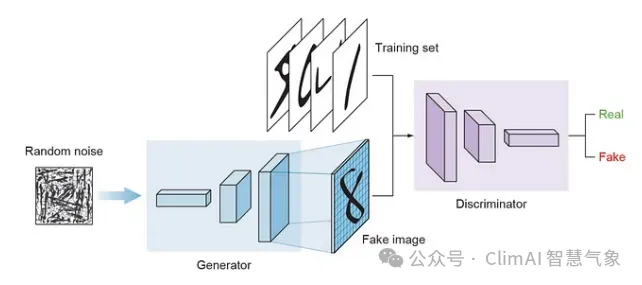
Figure 3 GAN Architecture
As shown in Figure 3, the steps taken by GAN are as follows:
If we closely observe the generator and discriminator networks, we find that the generator network is an inverted ConvNet, starting from a flattened vector, then the images are upscaled until they are similar in size to the images in the training dataset.
3. Deep Convolutional GANs (DCGANs)
In the original GAN paper from 2014, the generator and discriminator networks were built using Multi-Layer Perceptron (MLP) networks. However, since then, it has been shown that convolutional layers can enhance the predictive capabilities of the discriminator, which in turn improves the accuracy of the generator and the overall model. This type of GAN is referred to as DCGAN (Deep Convolutional GAN).
Now, all GAN architectures include convolutional layers, so when we talk about GANs, “DC” is implicitly included, and we will refer to GANs and DCGANs collectively as DCGAN in this article and this series.
4. Discriminator Network
The goal of the discriminator is to predict whether the image is real or fake. This is a typical supervised classification problem, so we can use traditional classifier networks.
The network consists of stacked convolutional layers, followed by a dense output layer with a sigmoid activation function. We use the sigmoid activation function because this is a binary classification problem, and the goal of the network is to output a predicted probability value between 0 and 1. Here, 0 means the image generated by the generator is fake, and 1 means it is real.
In Figure 4, we can see the discriminator’s role in the GAN model, which receives two sets of images. The first is real images from the training set, and the second is fake ones generated by the generator model.
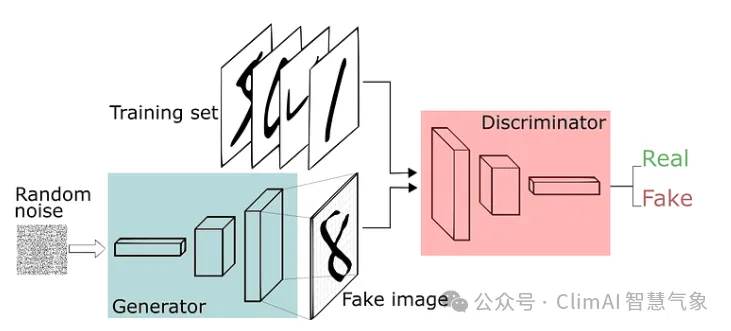
Figure 4 Discriminator in action in the GAN model
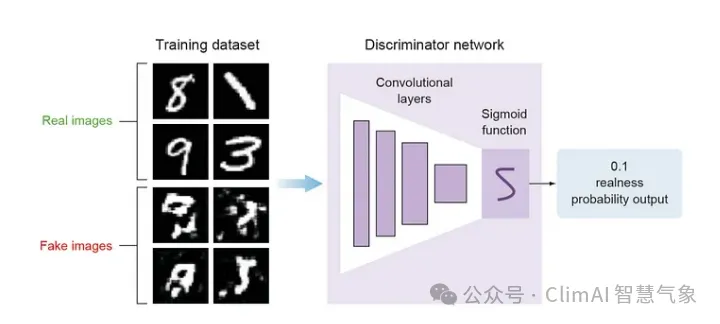
Figure 5 Discriminator model architecture
Training the discriminator is quite straightforward since it is similar to traditional supervised classification problems, where we feed labeled images to the discriminator: fake (or generated) and real images. Real images come from the training dataset, and fake images are outputs from the generator model.
Let’s implement the discriminator network in Keras to understand how it works. There is nothing new in the discriminator model. It follows the conventional pattern of a traditional CNN.
We will stack convolutional, batch normalization, activation, and dropout layers to create our model. All these layers have hyperparameters that we adjust while training the network. For your implementation, you can adjust these hyperparameters and add or remove layers as needed.
def discriminator_model(): # Instantiate a Sequential model and name it discriminator discriminator = Sequential() # Add a convolutional layer to the discriminator model discriminator.add(Conv2D(32, kernel_size=3, strides=2, input_shape=(28,28,1), padding="same")) # Add a leakyRelu activation function discriminator.add(LeakyReLU(alpha=0.2)) # Add a dropout layer with a dropout probability of 25% discriminator.add(Dropout(0.25)) # Add a second convolutional layer with zero padding discriminator.add(Conv2D(64, kernel_size=3, strides=2, padding="same")) discriminator.add(ZeroPadding2D(padding=((0,1),(0,1)))) # Add a batch normalization layer to speed up learning and improve accuracy discriminator.add(BatchNormalization(momentum=0.8)) discriminator.add(LeakyReLU(alpha=0.2)) discriminator.add(Dropout(0.25)) # Add a third convolutional layer with batch normalization, leakyRelu, and dropout discriminator.add(Conv2D(128, kernel_size=3, strides=2, padding="same")) discriminator.add(BatchNormalization(momentum=0.8)) discriminator.add(LeakyReLU(alpha=0.2)) discriminator.add(Dropout(0.25)) # Add a fourth convolutional layer with batch normalization, leakyRelu, and dropout discriminator.add(Conv2D(256, kernel_size=3, strides=1, padding="same")) discriminator.add(BatchNormalization(momentum=0.8)) discriminator.add(LeakyReLU(alpha=0.2)) discriminator.add(Dropout(0.25)) # Flatten the network and add an output Dense layer with a sigmoid activation function discriminator.add(Flatten()) discriminator.add(Dense(1, activation='sigmoid')) # Print model summary discriminator.summary() # Set the input image shape img = Input(shape=img_shape) # Run the discriminator model to get output probability probability = discriminator(img) # Return a model that takes the image as input and produces probability output return Model(img, probability)5. Generator Network
The generator network receives some random data and tries to mimic the training dataset to generate fake images. Its goal is to deceive the discriminator by attempting to generate images that are perfect replicas of the training dataset.
As it trains, it gets better with each iteration. On the other hand, the discriminator is being trained simultaneously, so the generator must continuously improve as the discriminator learns its tricks.
The architecture of the generator model looks like an inverted traditional ConvNet. The generator receives a vector input with random noise data and reshapes it into a volume with width, height, and depth. This volume is treated as a feature map that will be fed into several convolutional layers that will create the final image.
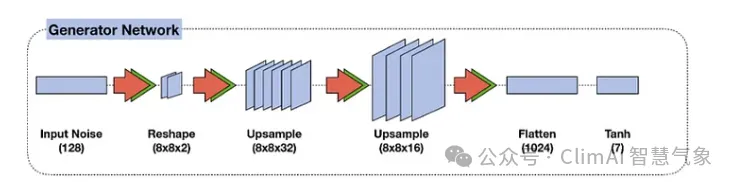
Figure 7 Generator network of the GAN model.
Just as traditional convolutional neural networks use pooling layers to downsample input images, to scale feature maps, we use upsampling layers to enlarge image sizes by repeating each row and column of its input pixels.
Now, let’s build the generator network using Keras. In the generator code, we will use similar components to those used in the discriminator network. The only new component is the upsampling layer, which doubles the input size by repeating pixels.
Similar to the discriminator, we will stack convolutional layers and add other optimization layers such as BatchNormalization. The key difference in the generator model is that it starts from a flattened vector, and then the images are upsampled until they are similar in size to the training dataset.
def generator_model(): # Instantiate a Sequential model and name it generator generator = Sequential() # Add a Dense layer with neuron count = 128x7x7 generator.add(Dense(128 * 7 * 7, activation="relu", input_dim=100)) # Reshape image size to 7 x 7 x 128 generator.add(Reshape((7, 7, 128))) # Upsampling layer to double image size to 14 x 14 generator.add(UpSampling2D(size=(2,2))) # Add a convolutional layer to run convolution process + batch normalization generator.add(Conv2D(128, kernel_size=3, padding="same", activation="relu")) generator.add(BatchNormalization(momentum=0.8)) # Upsample image size to 28 x 28 generator.add(UpSampling2D(size=(2,2))) # Convolution + batch normalization layer # Note that we haven’t added upsampling here since we already have 28 x 28 image size # This matches the image size in the MNIST dataset. You can adjust based on your problem. generator.add(Conv2D(64, kernel_size=3, padding="same", activation="relu")) generator.add(BatchNormalization(momentum=0.8)) # Convolution layer with filters=1 generator.add(Conv2D(1, kernel_size=3, padding="same", activation="relu")) # Print model summary generator.summary() # Generate noise vector of length=100 # We choose 100 here to create a simple network noise = Input(shape=(100,)) # Run the generator model to create fake images fake_image = generator(noise) # Return a model that takes the noise vector as input and outputs fake images return Model(noise, fake_image)6. Summary Discussion
In this article, we explored the main networks and components of GANs and how they work.
In upcoming articles, we will discuss the training process of GANs models and how to evaluate them. Stay tuned for the upcoming articles.
Source: ClimAI Smart Weather
[Disclaimer] The reproduction is for non-commercial educational and research purposes only, solely for the dissemination of academic news information, copyright belongs to the original author, if there is any infringement, please contact us immediately, and we will delete it promptly.