[New Intelligence Guide] ChatGPT’s capabilities have been unlocked, and its performance has been enhanced after adding plugin features. This is true for all large models. Tsinghua’s Wall Intelligence connects over 16,000 real APIs to large models, matching ChatGPT’s performance.
Recently, open-source large language models (LLMs) have made rapid progress, with models like LLaMA and Vicuna demonstrating excellent performance in various language understanding and generation tasks.
However, when faced with higher-level tasks, such as using external tools (APIs) based on user instructions, they still struggle.
To address this issue, Wall Intelligence, in collaboration with researchers from TsinghuaNLP, Yale, Renmin University, Tencent, and Zhihu, has launched the ToolLLM tool learning framework, integrating it into the OpenBMB large model tool system.
Paper link: https://arxiv.org/pdf/2307.16789.pdf
Data and code link: https://github.com/OpenBMB/ToolBench
Open-source model download link: https://huggingface.co/ToolBench
The ToolLLM framework includes the entire process of acquiring high-quality tool learning training data, model training code, and automatic model evaluation.
Among them, the authors have built the ToolBench dataset, which encompasses 16,464 real-world APIs.
Currently, all related code for ToolLLM has been open-sourced. Below is a demonstration of the ToolLLaMA trained by the authors, interacting with users and performing real-time reasoning:
The launch of the ToolLLM framework will help promote open-source language models to better utilize various tools, enhancing their reasoning capabilities in complex scenarios.
It not only assists researchers in exploring the boundaries of LLM capabilities more deeply but also opens the door to broader application scenarios.
ToolLLM Research Background
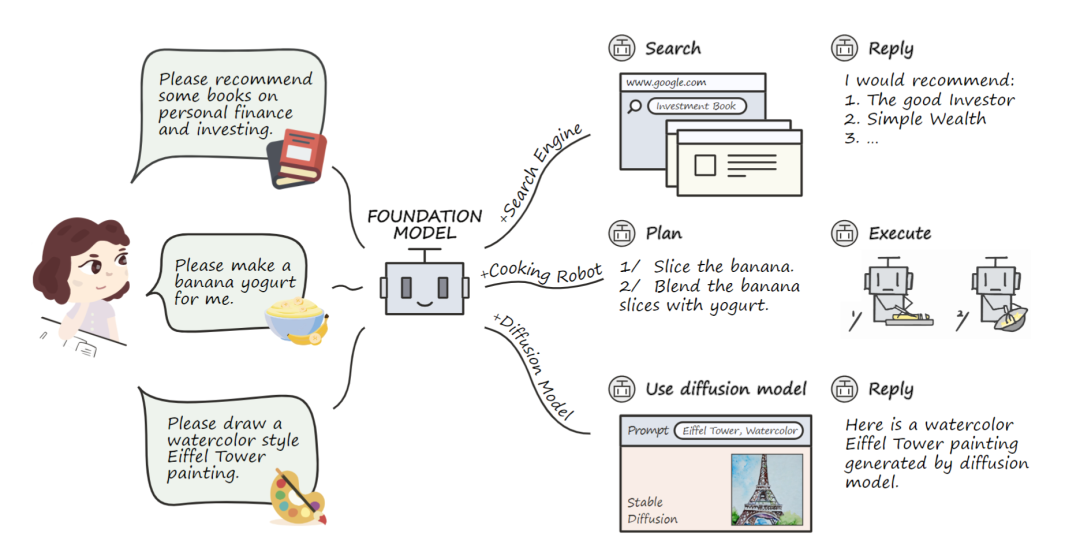
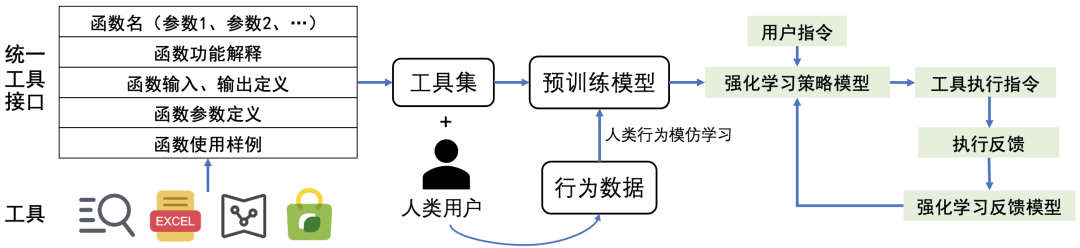
The goal of tool learning is to enable LLMs to efficiently interact with various tools (APIs) based on user instructions, thereby greatly expanding the capability boundaries of LLMs and making them an efficient bridge between users and a wide range of application ecosystems.
Large Model Tool Learning Paradigm
Although there have already been some works (e.g., Gorilla, APIBank, etc.) exploring how to enable LLMs to master API calling capabilities, these works still have the following limitations:
1. Limited APIs: Many studies have not used real-world APIs (such as RESTful APIs), leading to limited API scope and insufficient diversity.
2. Limited Scenarios: Previous work has mostly focused on the use of single tools, while real-world scenarios may require multiple tools to work together to complete complex tasks. Additionally, existing studies often assume that users provide APIs related to the instructions, but in reality, the available APIs can be numerous, making it difficult for users to efficiently choose from them.
3. Insufficient Model Planning and Reasoning Abilities: Existing model reasoning methods such as CoT and ReACT are too simplistic and cannot fully leverage the potential of LLMs to handle complex instructions, making it difficult to handle complex tasks.
ToolLLM Research Framework
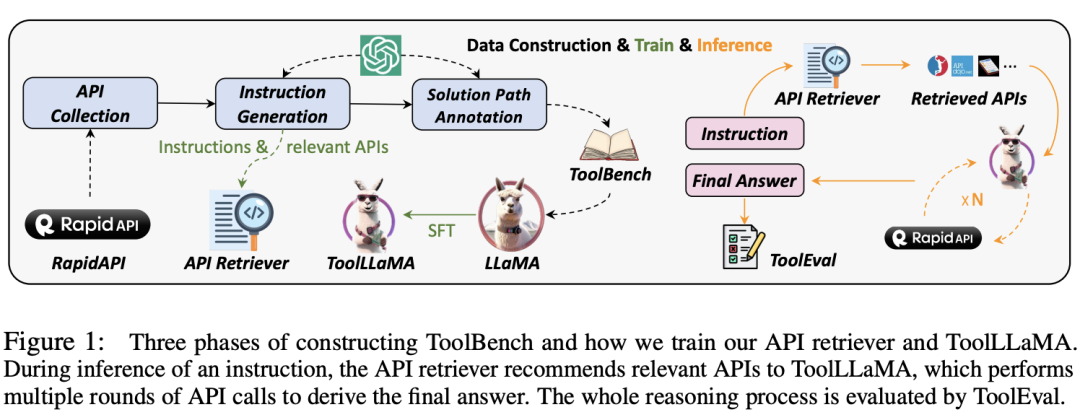
To stimulate the tool usage capabilities of open-source LLMs, this research proposes ToolLLM, a general tool learning framework that includes data construction, model training, and evaluation processes.
The authors first collected a high-quality tool learning instruction fine-tuning dataset, ToolBench, and then fine-tuned LLaMA to obtain ToolLLaMA, finally evaluating ToolLLaMA’s tool usage capabilities through ToolEval.
ToolLLM Data Collection, Model Training, Performance Evaluation Process
The construction of ToolBench is fully automated by the latest ChatGPT (gpt-3.5-turbo-16k) without the need for manual labeling.
The models trained on ToolBench possess strong generalization capabilities and can be directly applied to new APIs without additional training.
The table below lists the comparison between ToolBench and previous related works. ToolBench is not only unique in multi-tool mixed-use scenarios but also far exceeds in the number of real APIs.
Comparison of ToolBench with Previous Related Works
The construction of ToolBench includes three stages: API collection, instruction generation, and solution path annotation:
01 API Collection
API collection is divided into three steps: API crawling, filtering, and response compression.
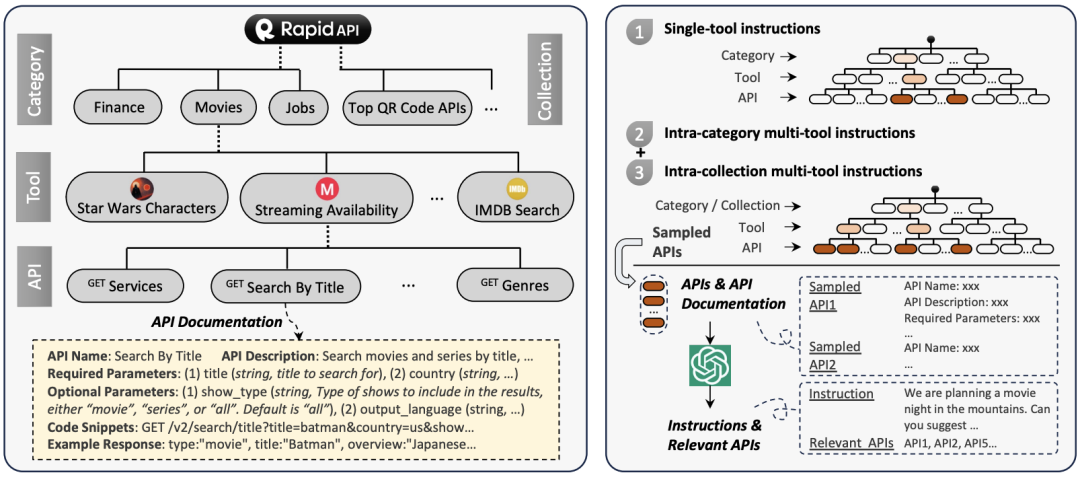
API Crawling: The authors collected a large number of real diverse APIs from RapidAPI Hub. RapidAPI is an industry-leading API provider where developers can connect to various existing APIs by registering a RapidAPI key. All APIs in RapidAPI can be categorized into 49 categories, such as sports, finance, and weather, with several tools under each category, each consisting of one or more APIs..
API Filtering: The authors filtered 10,853 tools (53,190 APIs) collected from RapidAPI based on their operational status, response time, quality, and other factors, ultimately retaining 3,451 high-quality tools (16,464 APIs).
API Response Compression: Some API responses may contain redundant information, making them too lengthy to input into the LLM. Therefore, the authors compressed the returned content to reduce its length while retaining key information. Based on a fixed return format for each API, the authors used ChatGPT to automatically analyze and remove unimportant information, greatly reducing the length of API responses.
02 Instruction Generation
RapidAPI Hierarchical Structure and Tool Instruction Generation Diagram
To ensure the generation of high-quality instructions while ensuring that the instructions can be completed with APIs, the authors adopted a bottom-up approach to tool instruction generation, starting from the collected APIs and constructing instructions covering various APIs in reverse.Specifically, the authors first sampled a variety of API combinations from the entire API set, and then used prompt engineering to get ChatGPT to devise possible instructions that could call these APIs.
These prompts included detailed documentation for each API, allowing ChatGPT to understand the functions of different APIs and the dependencies between them, thereby generating human-like instructions that meet the requirements. The specific sampling methods included single-tool instructions (instructions involving multiple APIs under a single tool) and multi-tool instructions (instructions involving multiple APIs from similar or different categories).
Through this method, the authors ultimately automatically constructed over 200,000 qualified instructions.
03 Solution Path Annotation
Given an instruction, the authors called ChatGPT to search (annotate) for an effective solution path (action sequence): {,…,}.This is a multi-step decision-making process completed through multiple rounds of dialogue with ChatGPT.
At each time step t, the model predicts the next action based on previous behavior history and API responses:
where indicates the real API response. Each action includes the name of the API called, the parameters passed, and the “thought process” behind why this action was taken.
To leverage the new function call feature added by ChatGPT, the authors treated each API as a special function and placed its API documentation in the function field of ChatGPT to help the model understand how to call the API.
Additionally, the authors also defined two function identifiers, “Give Up” and “Final Answer,” to mark the end of the action sequence.
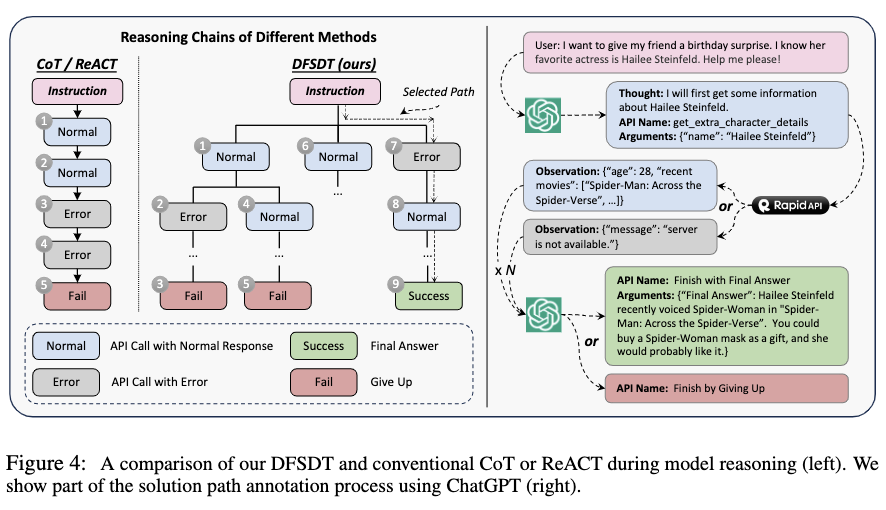
DFSDT vs Traditional Model Reasoning Methods Comparison (Left Image), Solution Path Annotation Process Diagram (Right Image)
In practical applications, the authors found that traditional CoT or ReACT algorithms suffer from error accumulation and limited search space during decision-making processes, making it difficult for even the most advanced GPT-4 to find a solution path in many cases, thus creating certain obstacles for data annotation.
To address this issue, the authors expanded the search space by constructing decision trees to increase the probability of finding valid paths.
At the same time, the authors also proposed the DFSDT algorithm, allowing the model to evaluate different reasoning paths and either continue along promising paths or abandon the current node and expand a new one.
DFSDT vs Traditional Reasoning Methods Performance Comparison
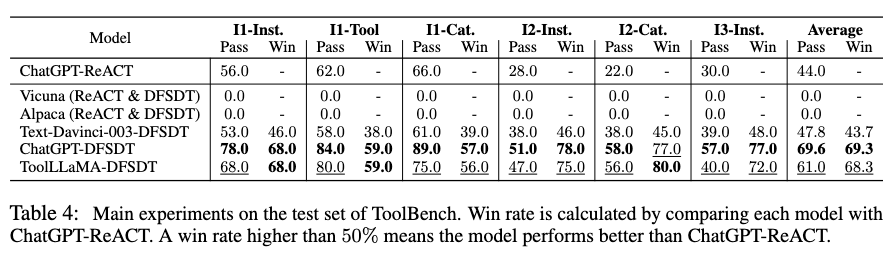
To verify the effectiveness of DFSDT, the authors compared DFSDT with ReACT based on ChatGPT and introduced a stronger baseline (ReACT@N)—performing multiple ReACT inferences until finding a reasonable solution path.
As shown in the figure below, DFSDT significantly outperformed both baselines in pass rate across all scenarios.
Moreover, DFSDT showed greater improvements in more complex scenarios (I2, I3), indicating that expanding the search space is more beneficial for solving complex tool invocation tasks.
In summary, the DFSDT algorithm significantly enhances the model’s reasoning capabilities and increases the success rate of solution path annotation.
Ultimately, the authors generated over 12,000 instruction-solution path data pairs for model training.
ToolEval Model Evaluation
To ensure accurate and reliable tool learning performance evaluation, the authors developed an automatic evaluation tool named ToolEval, which includes two evaluation metrics: pass rate and win rate.
The pass rate is the proportion of successfully completed user instructions within a limited number of steps; the win rate is based on ChatGPT’s assessment of the quality of two different solution paths (i.e., simulating human preferences).
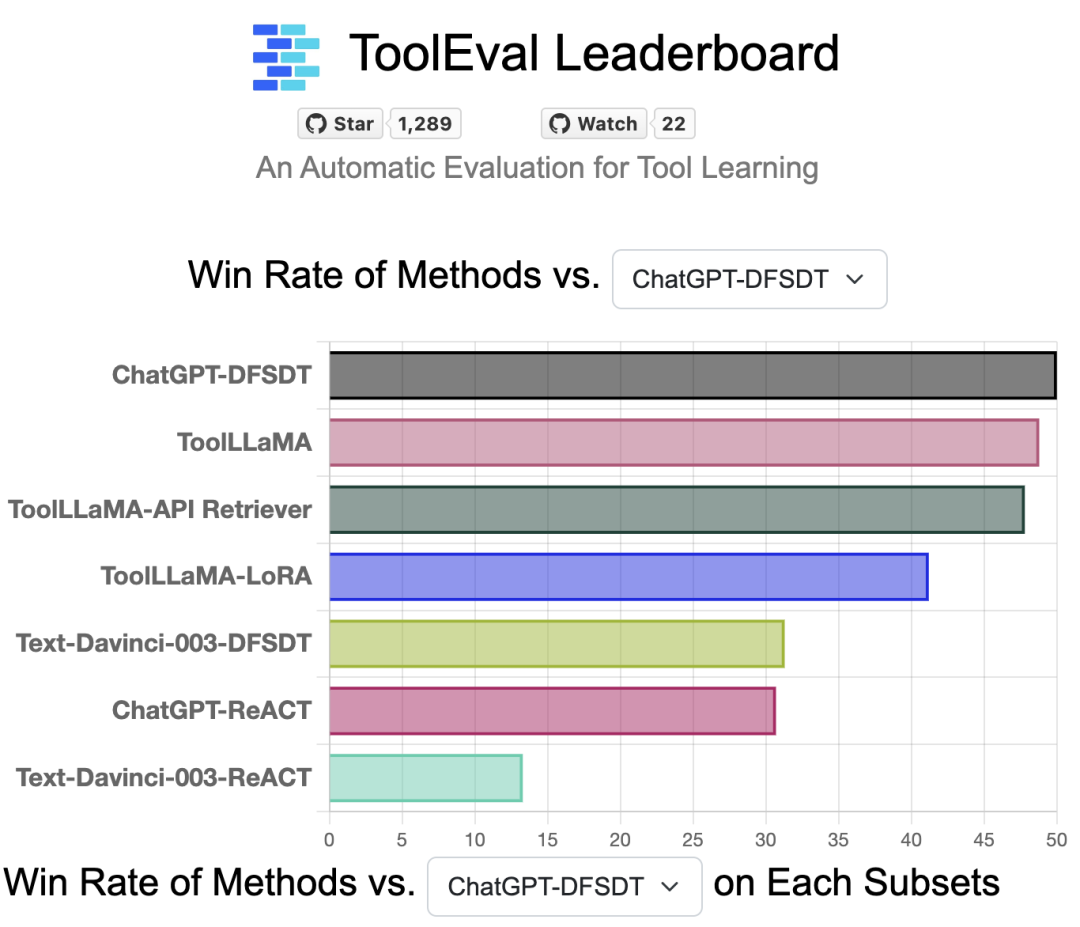
ToolEval Evaluation Tool Leaderboard
To verify the reliability of this evaluation method, the authors first collected a large number of human-labeled results and found that the consistency of using ChatGPT for automatic evaluation with human judgments reached 75.8%, indicating that ToolEval’s evaluation results are highly similar to human judgments.
Additionally, ToolEval’s evaluations showed very small variance (3.47%) upon repeated testing, which is lower than that of humans (3.97%), indicating that ToolEval’s evaluation consistency exceeds that of humans and is more stable and reliable.
ToolLLaMA Model Training & Experimental Results
Based on ToolBench, the authors fine-tuned the LLaMA 7B model to obtain ToolLLaMA, which possesses tool usage capabilities.
Due to the diverse tools and instructions in the training data, ToolLLaMA has learned very strong generalization capabilities, enabling it to handle new tasks and new tools that were not seen during training.
To validate ToolLLaMA’s generalization capabilities, the authors conducted three levels of testing:
1. Single Tool Instruction Testing (I1): Evaluating the model’s ability to solve new instructions aimed at a single tool that were not learned during training.
2. Multi-Tool Instruction Testing within the Same Category (I2): Evaluating how the model handles new instructions for various tools under the same category that were learned during training.
3. Multi-Tool Instruction Testing Across Different Categories (I3): Examining how the model handles new instructions for tools from different categories.
The authors chose two LLaMA variants, Vicuna and Alpaca, which had been fine-tuned for general instructions, as well as OpenAI’s ChatGPT and Text-Davinci-003 as baselines.
All these models were applied with the more advanced DFSDT reasoning algorithm, and ReACT was applied to ChatGPT.
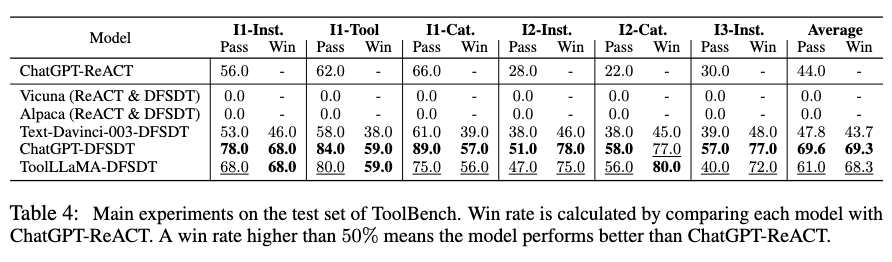
When calculating the win rate, each model was compared with ChatGPT-ReACT.The following two figures summarize the results of ToolLLaMA and other models:
According to the figures above, ToolLLaMA significantly outperforms traditional tool usage methods like ChatGPT-ReACT in both pass rate and win rate, demonstrating superior generalization capabilities, easily generalizing to new tools that it has not encountered, which is crucial for user-defined new APIs and enabling ToolLLaMA to efficiently accommodate new APIs.
Furthermore, the authors found that ToolLLaMA’s performance is already very close to ChatGPT, far exceeding baselines like Davinci, Alpaca, and Vicuna.
Combining API Retriever with ToolLLaMA
In practical scenarios, users may be unable to manually recommend APIs related to the current instructions from a large number of APIs, necessitating a model with automatic API recommendation capabilities.To address this issue, the authors called upon ChatGPT to automatically label data and trained a sentence-bert model for dense retrieval.
To test the performance of the API retriever, the authors compared the trained API retriever with methods like BM25 and OpenAI Ada Embedding, finding that the retriever significantly outperformed the baselines, demonstrating strong retrieval performance.
Additionally, the authors combined this retriever with ToolLLaMA, resulting in a tool usage model pipeline that better reflects real-world scenarios.
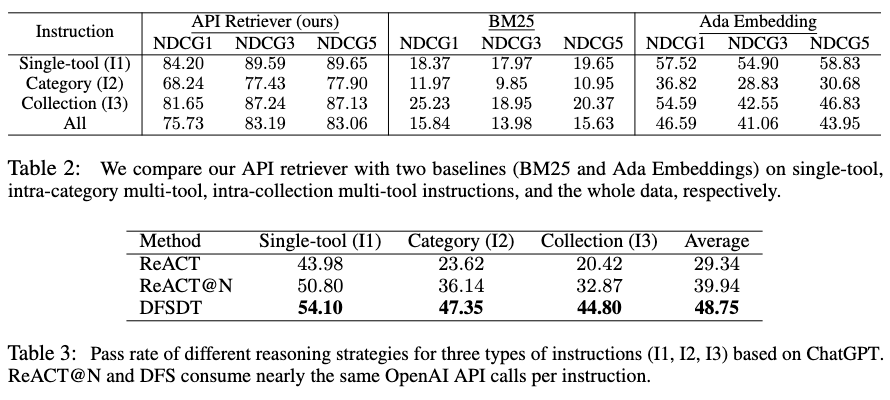
Performance Comparison of the API Retriever Trained by the Authors and Baseline Methods
Tool Learning Expanding the Capability Boundaries of Large Models
In recent years, large models have demonstrated remarkable application value across various fields, continuously pushing the performance limits of various downstream tasks.
Despite the significant achievements of large models in many aspects, there are still certain limitations in specific domain tasks, which often require specialized tools or domain knowledge to solve effectively.
Therefore, large models need to possess the ability to invoke various specialized tools in order to provide more comprehensive support for real-world tasks.
Recently, a new paradigm known as Tool Learning for Large Models has emerged.
The core of this paradigm is to combine the advantages of specialized tools with foundational models to achieve higher accuracy, efficiency, and autonomy in problem-solving, significantly unleashing the potential of large models.
In terms of application, the emergence of ChatGPT Plugins has filled the last gap in ChatGPT, allowing it to support networking and solve mathematical calculations, often referred to as OpenAI’s “App Store” moment.However, until now, it only supports select OpenAI Plus users, and most developers still cannot access it.
To address this, Wall Intelligence previously launched the Tool Learning Engine BMTools, an open-source scalable tool learning platform based on language models, which will be another important module in Wall Intelligence’s layout of large model systems.
The R&D team has unified the invocation processes of various tools (e.g., text-to-image models, search engines, stock queries, etc.) into one framework, standardizing and automating the entire tool invocation process.
Developers can use BMTools to invoke various tool interfaces with given models (ChatGPT, GPT-4) to achieve specific functionalities.Additionally, the BMTools toolkit has also integrated the recently popular Auto-GPT and BabyAGI.
In the future, the team will have more releases surrounding large model tool learning, so stay tuned!
https://github.com/OpenBMB/BMTools
Tool Learning Overview Link:
https://arxiv.org/abs/2304.08354
Tool Learning Paper List:
https://github.com/thunlp/ToolLearnirgPapers