
Click below on thecard to follow the “Beginner’s Guide to Python” public account
-
Dataset Splitting -
Metrics -
Reproducibility -
Configuration, Logging, and Visualization
-
F1 Score -
Precision and Recall -
mAP (for detection tasks) -
IoU (for segmentation tasks) -
Accuracy (for balanced datasets) -
ROC-AUC
+--------+----------+--------+-----------+--------+| split | accuracy | f1 | precision | recall |+--------+----------+--------+-----------+--------+| val | 0.9915 | 0.9897 | 0.9895 | 0.99 || test | 0.9926 | 0.9921 | 0.9927 | 0.9915 |+--------+----------+--------+-----------+--------+def get_metrics(gt_labels: List[int], preds: List[int]) -> Dict[str, float]: num_classes = len(set(gt_labels)) if num_classes == 2: average = "binary" else: average = "macro"
metrics = {} metrics["accuracy"] = accuracy_score(gt_labels, preds) metrics["f1"] = f1_score(gt_labels, preds, average=average) metrics["precision"] = precision_score(gt_labels, preds, average=average) metrics["recall"] = recall_score(gt_labels, preds, average=average) return metrics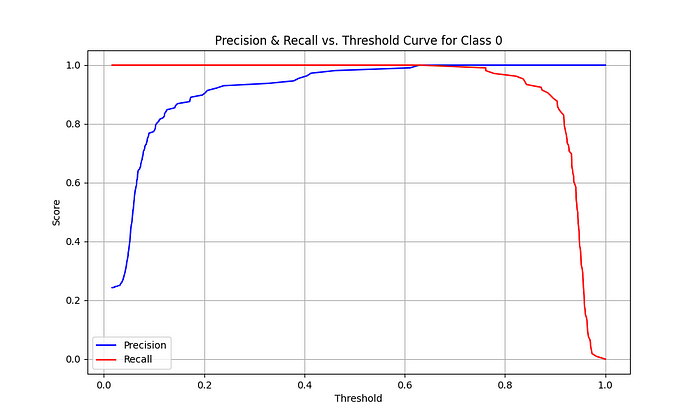
def set_seeds(seed: int, cudnn_fixed: bool = False) -> None: torch.manual_seed(seed) np.random.seed(seed) random.seed(seed)
if cudnn_fixed: torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False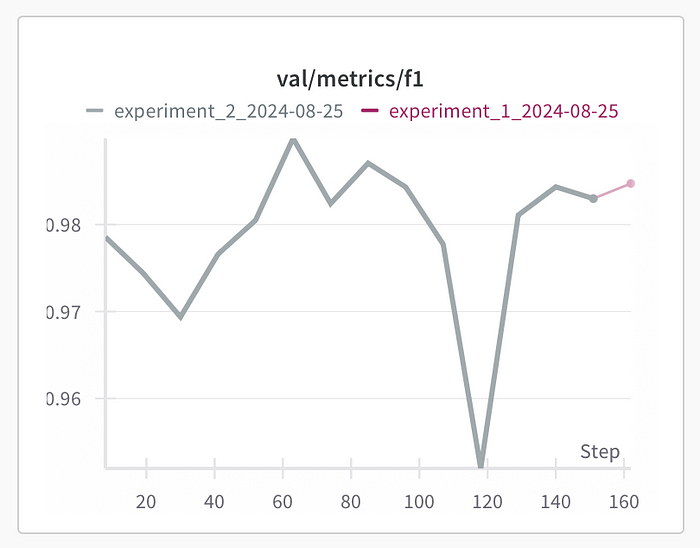
-
Configuration files containing variables and hyperparameters -
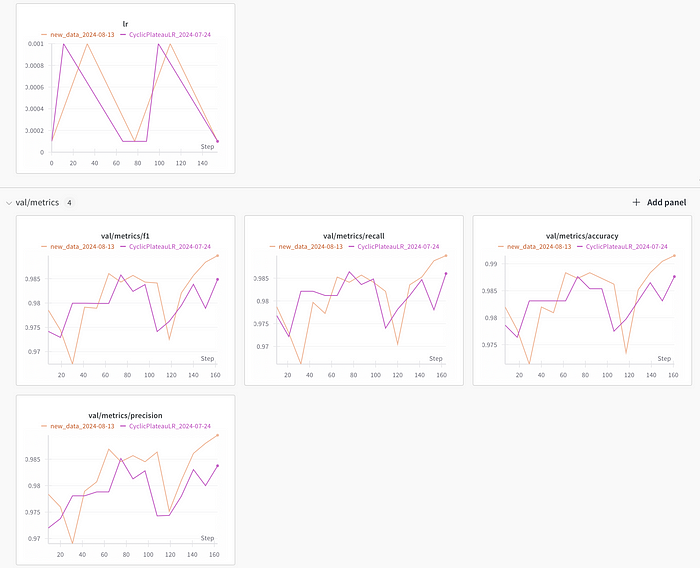
Logging all metrics and configurations -
Visualization of metrics
project_name: project_name
exp_name: baseline
exp: ${exp_name}_${now_dir}
train: root: /path/to/project device: cuda
label_to_name: {0: "class_1", 1: "class_2", 2: "class_3"} img_size: [256, 256] # (h, w)
train_split: 0.8 val_split: 0.1 # test_split = 1 - train_split - val_split
batch_size: 64 epochs: 15 use_scheduler: True
layers_to_train: -1
num_workers: 10 threads_to_use: 10
data_path: ${train.root}/dataset path_to_save: ${train.root}/output/models/${exp} vis_path: ${train.root}/output/visualized
seed: 42 cudnn_fixed: False debug_img_processing: False
export: # TensorRT must be done on the inference device half: False max_batch_size: 1
model_path: ${train.path_to_save} path_to_data: ${train.root}/to_test
-
Print validation metrics after each epoch -
If it achieves the best metrics, save the model -
If debugging mode is on, save preprocessed images
-
Save metrics.csv containing the best validation and test metrics
-
Save model.onnx, model.engine, and any other formats created during model export -
Save visualizations showing model attention
output|├── debug_img_processing| ├── img_1| └── img_2|├── models| ├── experiment_1| ├── model.pt| ├── model.engine| ├── precision_recall_curves| └── val_precision_recall_vs_threshold.png| └── metrics.csv|└── visualized ├── class_1 ├── img_1 └── img_2· END ·
🌟 Want to become a computer vision expert? Come to the "Beginner's Guide to Python" public account! Reply "Python Visual Practical Projects" to unlock a big gift bag of 31 super interesting visual projects! 🎁
This article is for learning and communication purposes only. If there is any infringement, please contact the author for deletion.