
Click on the above“Beginner Learning Vision” to choose to add “Star” or “Top“
Important content delivered in real-time
Software Version Information:
Windows 10 64-bit
TensorFlow 1.15
TensorFlow Object Detection API 1.x
Python 3.6.5
VS2015 VC++
CUDA 10.0Hardware:
CPU i7
GPU 1050tiTo install the TensorFlow Object Detection API framework, see here:
The TensorFlow Object Detection API finally supports TensorFlow 1.x and TensorFlow 2.x
First, download the dataset from:
https://pan.baidu.com/s/1UbFkGm4EppdAU660Vu7SdQA total of 7581 images, annotated based on Pascal VOC2012. Divided into two categories: safety helmet and person (hat and person), JSON format as follows:
item { id: 1 name: 'hat'}
item { id: 2 name: 'person'}
After downloading the dataset, it cannot be converted to TFRecord by the scripts in the TensorFlow Object Detection API framework, mainly due to several XML and JPEG image format errors. After some difficulties, I corrected them all. After correcting the data, running the following two scripts will generate the training set and validation set TFRecord data. The command line is as follows:

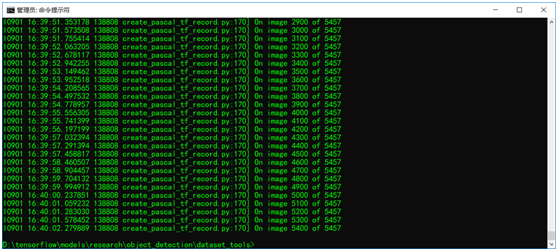
Here, it should be noted that in line 165 of the create_pascal_tf_record.py script, change
'aeroplane_' + FLAGS.set + '.txt')to:
FLAGS.set + '.txt')The reason is that the dataset has not been classified into train/val. Therefore, a modification is needed. After completing the modification, save it. Running the above command line will correctly generate TFRecord; otherwise, an error will occur.
Implement transfer learning based on the faster_rcnn_inception_v2_coco object detection model. First, configure the transfer learning config file, which can be found in:
research\object_detection\samples\configsFind the file:
faster_rcnn_inception_v2_coco.configThen, modify the relevant parts of the config file. For details on how to modify and what to change, see here:
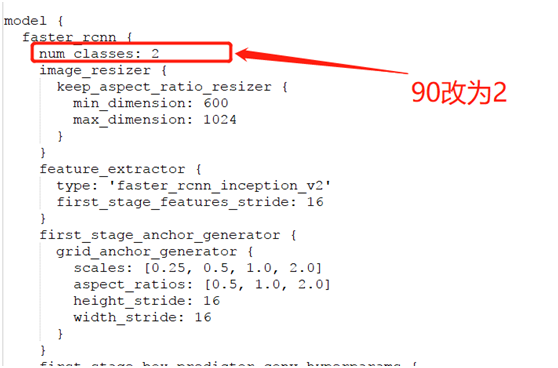
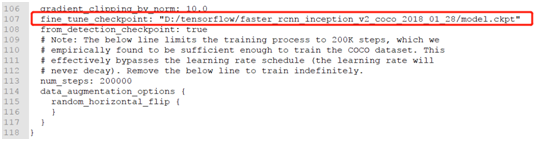
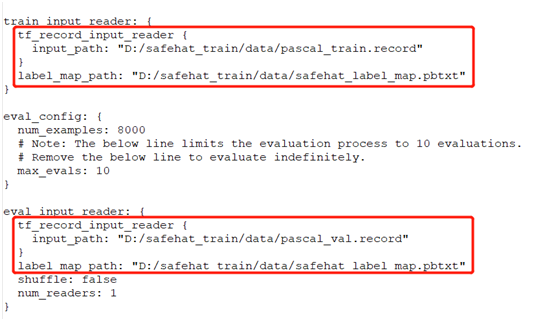
After completing the modifications, create several directories under D drive, then execute the following command line parameters:

It will start training for a total of 40000 steps. During the training process, you can view the training results through TensorBoard:
Model Export
After completing 40000 steps of training, you can see the corresponding checkpoint files. Using the model export script provided by the TensorFlow Object Detection API framework, you can export the checkpoint files into frozen graph format PB files. The relevant command line parameters are as follows:

After obtaining the PB file, use the tf_text_graph_faster_rcnn.py script in OpenCV 4.x to convert and generate the graph.pbtxt configuration file. The final output will be:
- frozen_inference_graph.pb
- frozen_inference_graph.pbtxtHow to export the PB model to OpenCV DNN support, see here:
Essentials | Exporting TensorFlow Model and Using in OpenCV DNN
Directly call the trained model in OpenCV DNN to complete custom object detection. It should be particularly noted that during the training phase, we chose a model that supports images with a ratio of 600~1024 for input. Therefore, during the inference prediction phase, we can directly use the actual size of the input image, and the model’s output format is still 1x1xNx7, which can be parsed according to the format to obtain the predicted boxes and corresponding categories. The final code implementation is as follows:
1import cv2 as cv
2
3labels = ['hat', 'person']
4model = "D:/safehat_train/models/train/frozen_inference_graph.pb"
5config = "D:/safehat_train/models/train/frozen_inference_graph.pbtxt"
6
7# Read test image
8image = cv.imread("D:/123.jpg")
9h, w = image.shape[:2]
10cv.imshow("input", image)
11
12# Load model and perform inference
13net = cv.dnn.readNetFromTensorflow(model, config)
14blob = cv.dnn.blobFromImage(cv.resize(image, (w, h)), swapRB=True, crop=False)
15net.setInput(blob)
16detectOut = net.forward()
17
18# Parse output
19classIds = []
20confidences = []
21boxes = []
22for detection in detectOut[0,0,:,:]:
23 score = detection[2]
24 if score > 0.4:
25 left = detection[3]*w
26 top = detection[4]*h
27 right = detection[5]*w
28 bottom = detection[6]*h
29 classId = int(detection[1]) + 1
30 classIds.append(classId)
31 boxes.append([int(left), int(top), int(right), int(bottom)])
32 confidences.append(float(score))
33
34# Non-maximum suppression
35nms_indices = cv.dnn.NMSBoxes(boxes, confidences, 0.4, 0.4)
36for i in range(len(nms_indices)):
37 index = nms_indices[i][0]
38 box = boxes[index]
39 cid = classIds[index]
40 if cid == 1:
41 cv.rectangle(image, (box[0], box[1]), (box[2], box[3]), (140, 199, 0), 4, 8, 0)
42 else:
43 cv.rectangle(image, (box[0], box[1]), (box[2], box[3]), (255, 0, 255), 4, 8, 0)
44 cv.putText(image, labels[cid-1], (box[0], box[1]), cv.FONT_HERSHEY_SIMPLEX, 0.75, (255, 0, 0), 2)
45
46# Show output
47cv.imshow("safetyhat-detection-demo", image)
48cv.imwrite("D:/result123.png", image)
49cv.waitKey(0)
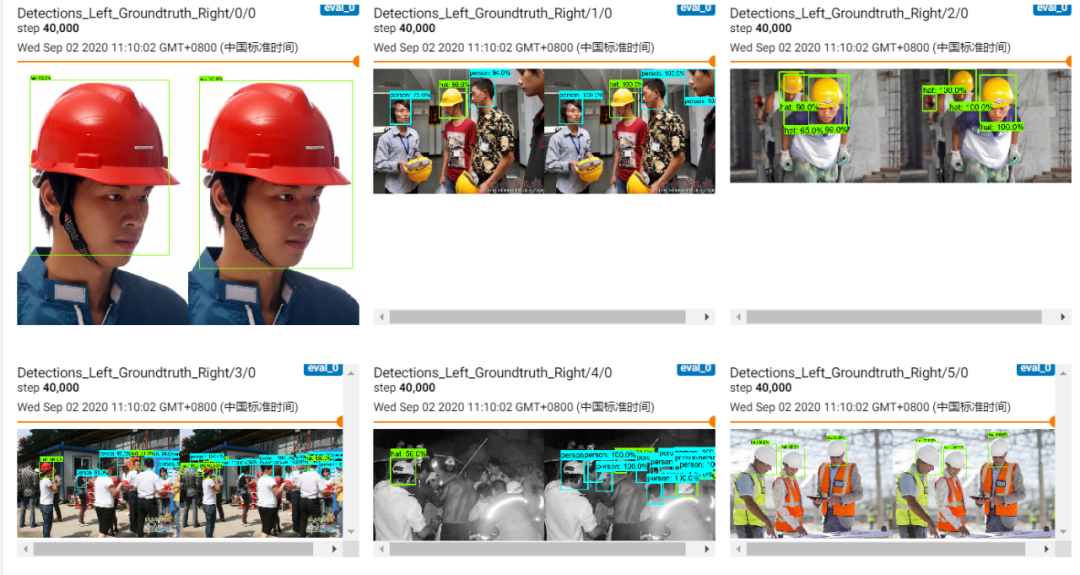
50cv.destroyAllWindows()Some running results of test images are as follows:





As we can see, there is a misidentification situation in the second image! It is evident that the model can continue training!
Pitfall Guide:
1. For the downloaded public dataset, remember to re-read it with OpenCV and then resave it in JPG format. This will avoid image format data errors when generating TFRecord.
ValueError: Image format not JPEG
2. In the public dataset, there may be inconsistencies between the XML file’s filename and the actual image file name, which needs to be processed programmatically. Otherwise, you may encounter
Windows fatal exception: access violation error
3. After using non-maximum suppression,
SystemError: <built-in function NMSBoxes> returned NULL without setting an error, Solution: boxes must be of int type, and confidences must be of float type.
References:
Deploying Deep Learning Models Using OpenCV 4.1.2 DNN Module
https://github.com/njvisionpower/Safety-Helmet-Wearing-Dataset
https://github.com/opencv/opencv/wiki/Deep-Learning-in-OpenCV
https://github.com/tensorflow/models/tree/master/research/object_detection
Communication Group
Welcome to join the WeChat reader group to communicate with peers. Currently, there are WeChat groups for SLAM, three-dimensional vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions and more (will be gradually subdivided in the future), please scan the WeChat ID below to join the group, with the note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format, otherwise, it will not be approved. After successful addition, you will be invited to relevant WeChat groups based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group, thank you for your understanding~

