

Source: DeepHub IMBA
This article is about 3000 words long and is recommended to be read in 5 minutes.
This article will explore three effective techniques to enhance document retrieval in applications based on <strong>RAG</strong>. By combining these techniques, it is possible to retrieve documents that closely match user queries, thus generating better answers.
Query Expansion

You are a helpful expert financial research assistant. Provide an example answer to the given question, that might be found in a document like an annual report.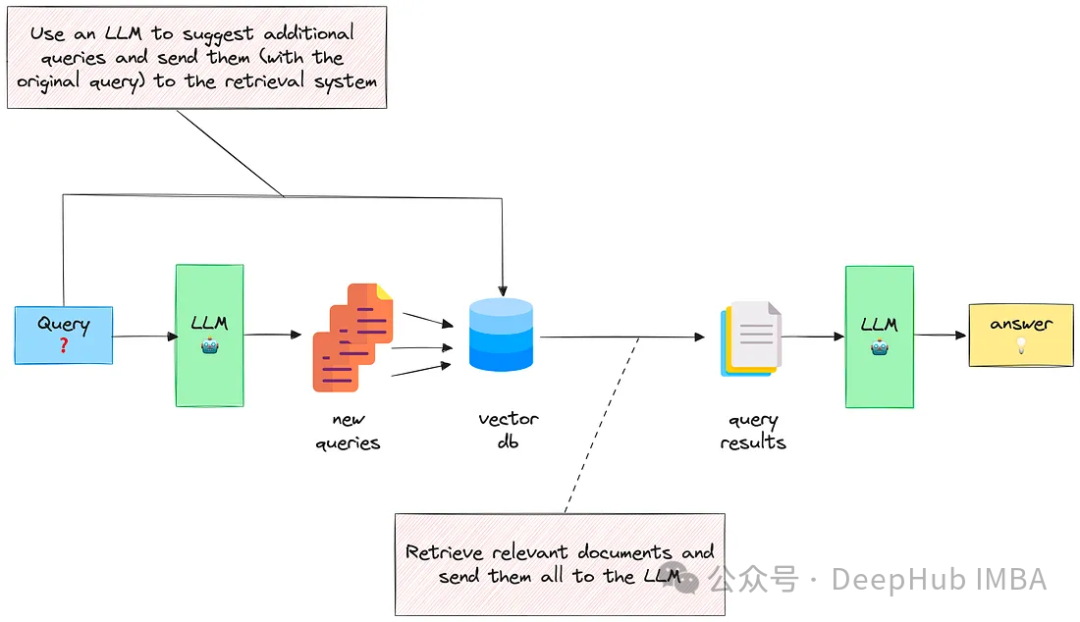
You are a helpful expert financial research assistant. Your users are asking questions about an annual report. Suggest up to five additional related questions to help them find the information they need, for the provided question. Suggest only short questions without compound sentences. Suggest a variety of questions that cover different aspects of the topic. Make sure they are complete questions, and that they are related to the original question. Output one question per line. Do not number the questions.Reordering

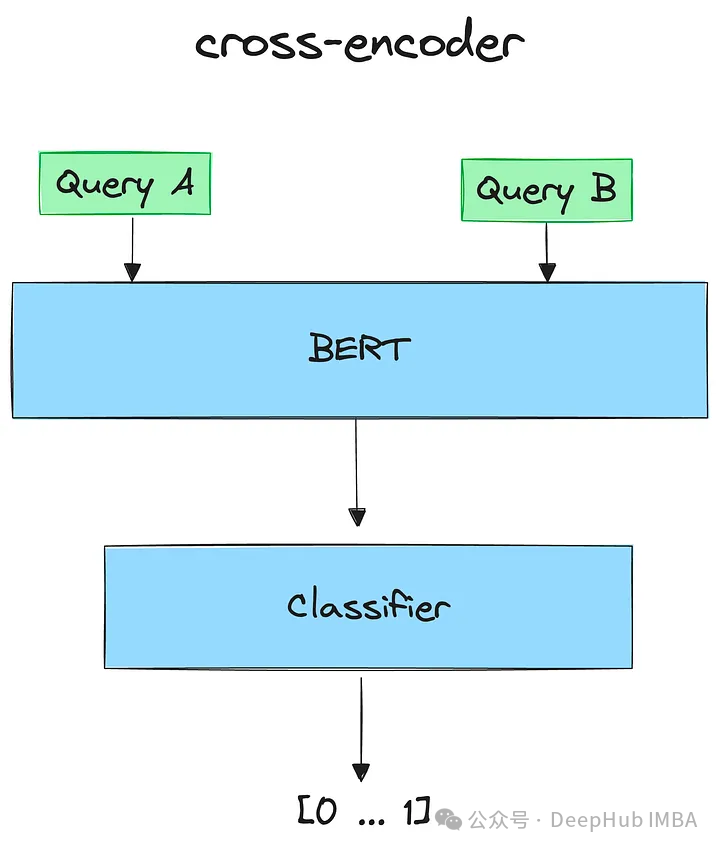
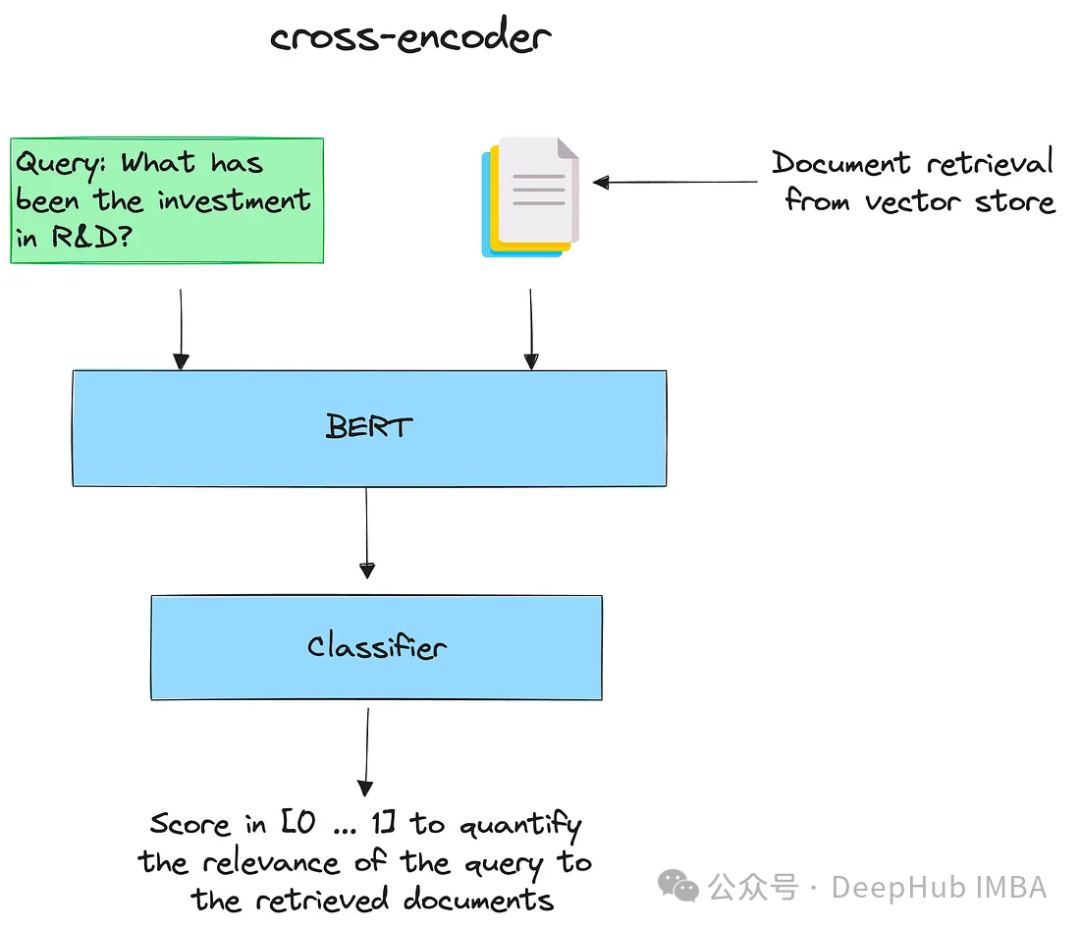
pip install -U sentence-transformers
from sentence_transformers import CrossEncoder
cross_encoder = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")pairs = [[query, doc] for doc in retrieved_documents]
scores = cross_encoder.predict(pairs)
print("Scores:")
for score in scores: print(score)
# Scores: # 0.98693466 # 2.644579 # -0.26802942 # -10.73159 # -7.7066045 # -5.6469955 # -4.297035 # -10.933233 # -7.0384283 # -7.3246956print("New Ordering:")
for o in np.argsort(scores)[::-1]: print(o+1)Embedding Adapters
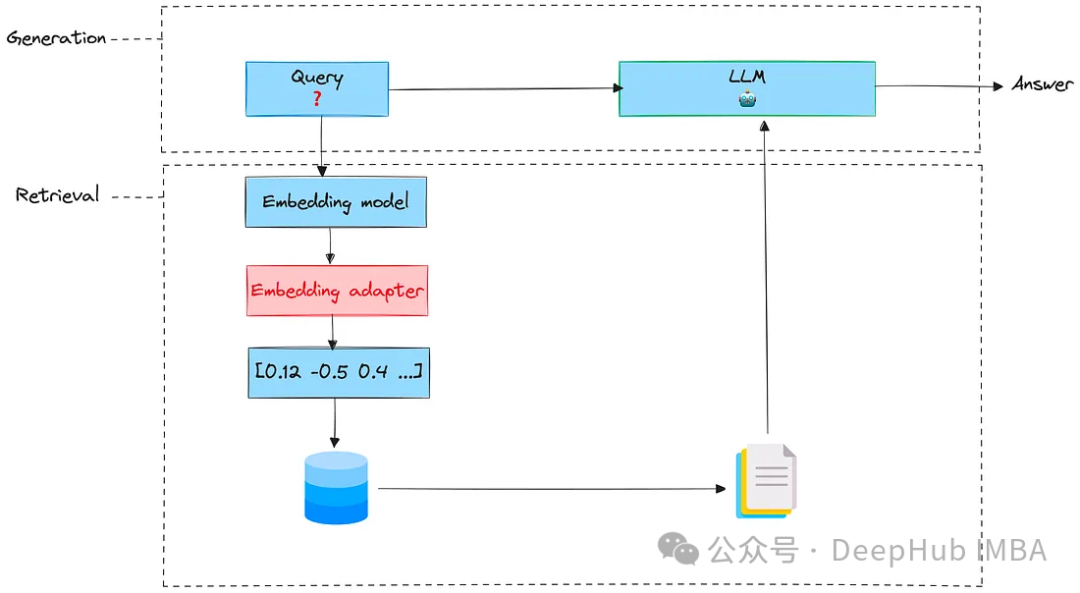
import os
import openai
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ['OPENAI_API_KEY']
PROMPT_DATASET = """
You are a helpful expert financial research assistant. You help users analyze financial statements to better understand companies. Suggest 10 to 15 short questions that are important to ask when analyzing an annual report. Do not output any compound questions (questions with multiple sentences or conjunctions). Output each question on a separate line divided by a newline.
"""
def generate_queries(model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": PROMPT_DATASET,
},
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
content = content.split("\n")
return content
generated_queries = generate_queries()
for query in generated_queries:
print(query)
# 1. What is the company's revenue growth rate over the past three years? # 2. What are the company's total assets and total liabilities? # 3. How much debt does the company have? Is it increasing or decreasing? # 4. What is the company's profit margin? Is it improving or declining? # 5. What are the company's cash flow from operations, investing, and financing activities? # 6. What are the company's major sources of revenue? # 7. Does the company have any pending litigation or legal issues? # 8. What is the company's market share compared to its competitors? # 9. How much cash does the company have on hand? # 10. Are there any major changes in the company's executive team or board of directors? # 11. What is the company's dividend history and policy? # 12. Are there any related party transactions? # 13. What are the company's major risks and uncertainties? # 14. What is the company's current ratio and quick ratio? # 15. How has the company's stock price performed over the past year?results = chroma_collection.query(query_texts=generated_queries, n_results=10, include=['documents', 'embeddings'])
retrieved_documents = results['documents']PROMPT_EVALUATION = """
You are a helpful expert financial research assistant. You help users analyze financial statements to better understand companies. For the given query, evaluate whether the following statement is relevant. Output only 'yes' or 'no'.
"""
def evaluate_results(query, statement, model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": PROMPT_EVALUATION,
},
{
"role": "user",
"content": f"Query: {query}, Statement: {statement}"
}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
max_tokens=1
)
content = response.choices[0].message.content
if content == "yes":
return 1
return -1
retrieved_embeddings = results['embeddings']
query_embeddings = embedding_function(generated_queries)
adapter_query_embeddings = []
adapter_doc_embeddings = []
adapter_labels = []
for q, query in enumerate(tqdm(generated_queries)):
for d, document in enumerate(retrieved_documents[q]):
adapter_query_embeddings.append(query_embeddings[q])
adapter_doc_embeddings.append(retrieved_embeddings[q][d])
adapter_labels.append(evaluate_results(query, document))
adapter_query_embeddings = torch.Tensor(np.array(adapter_query_embeddings))
adapter_doc_embeddings = torch.Tensor(np.array(adapter_doc_embeddings))
adapter_labels = torch.Tensor(np.expand_dims(np.array(adapter_labels),1))
dataset = torch.utils.data.TensorDataset(adapter_query_embeddings, adapter_doc_embeddings, adapter_labels)def model(query_embedding, document_embedding, adaptor_matrix):
updated_query_embedding = torch.matmul(adaptor_matrix, query_embedding)
return torch.cosine_similarity(updated_query_embedding, document_embedding, dim=0)def mse_loss(query_embedding, document_embedding, adaptor_matrix, label):
return torch.nn.MSELoss()(model(query_embedding, document_embedding, adaptor_matrix), label)# Initialize the adaptor matrix
mat_size = len(adapter_query_embeddings[0])
adapter_matrix = torch.randn(mat_size, mat_size, requires_grad=True)
min_loss = float('inf')
best_matrix = None
for epoch in tqdm(range(100)):
for query_embedding, document_embedding, label in dataset:
loss = mse_loss(query_embedding, document_embedding, adapter_matrix, label)
if loss < min_loss:
min_loss = loss
best_matrix = adapter_matrix.clone().detach().numpy()
loss.backward()
with torch.no_grad():
adapter_matrix -= 0.01 * adapter_matrix.grad
adapter_matrix.grad.zero_()
test_vector = torch.ones((mat_size,1))
scaled_vector = np.matmul(best_matrix, test_vector).numpy()
test_vector.shape # torch.Size([384, 1])
scaled_vector.shape # (384, 1)
best_matrix.shape # (384, 384)Conclusion
Editor: Wang Jing
