Source: 51CTO.com
◆ ◆ ◆
Introduction
In recent years, machine learning has begun to enter the mainstream in unprecedented ways. This trend is not solely driven by low-cost cloud environments or extremely powerful GPU hardware; in addition, the available frameworks for machine learning have also seen explosive growth. All these frameworks are open-source, but more importantly, they abstract the most complex parts of machine learning in their design, ensuring that relevant technical solutions can serve more developers.

In today’s article, we will explore thirteen machine learning frameworks, some of which were just released last year, while others have been completely upgraded recently. The most noteworthy features of these frameworks are their efforts to address various challenges related to machine learning in simple and innovative ways.
◆ ◆ ◆
Apache Spark MLlib
Apache Spark is arguably the most dazzling member of the Hadoop family today, but this in-memory data processing framework was not originally related to Hadoop. With its outstanding features, it has carved out a niche outside the Hadoop ecosystem. Spark has now become an immediately usable machine learning tool, primarily due to its ability to apply algorithm libraries to in-memory data at high speeds.
Spark is still evolving, and the available algorithms in Spark are continually increasing and improving. The 1.5 version released last year added numerous new algorithms and improved existing ones, while further restoring Spark ML tasks in MLlib through continuous processes.
◆ ◆ ◆
Apache Singa
This “deep learning” framework supports various high-intensity machine learning functions, including natural language processing and image recognition. Singa was recently included in the Apache incubation project, and this open-source framework aims to lower the difficulty of training deep learning models on large-scale data.
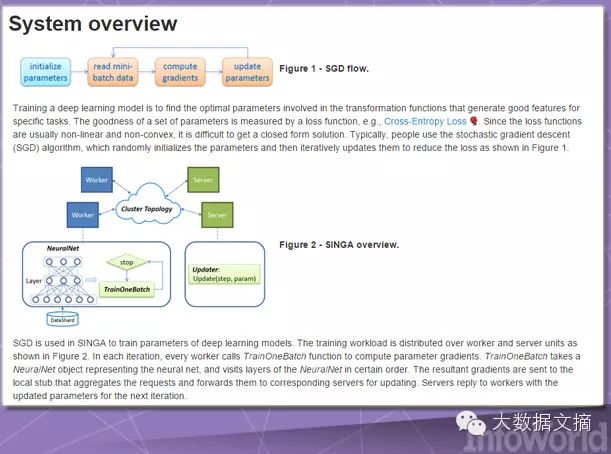
Singa provides a simple programming model for deep learning network training across a whole set of device clusters, supporting various common training task types; convolutional neural networks, restricted Boltzmann machines, and recurrent neural networks. Each model can be trained synchronously (one-to-one) or asynchronously (in parallel), depending on the specific needs of the problem. Singa also simplifies cluster setup using Apache Zookeeper.
◆ ◆ ◆
Caffe
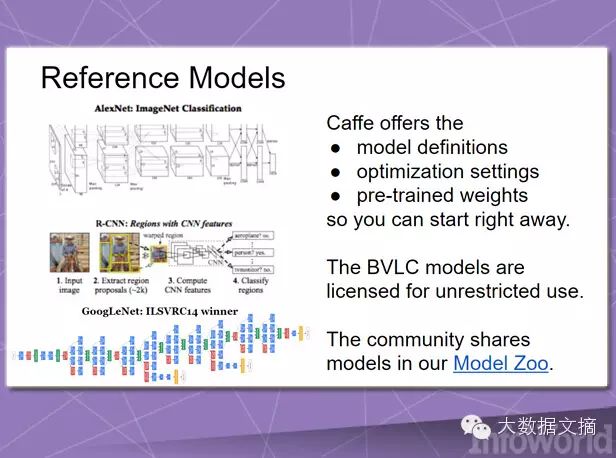
The deep learning framework Caffe is a solution “grounded in expressiveness, speed, and modularity.” It was initially created in 2013 primarily for machine vision projects. Since its inception, Caffe has included various other applications, including speech and multimedia.
Prioritizing speed, Caffe is entirely written in C++ and supports CUDA acceleration. However, it can also switch between CPU and GPU processing as needed. Its distribution includes a range of free and open-source reference models, mainly aimed at various conventional typical tasks; currently, the Caffe user community is actively developing other models.
◆ ◆ ◆
Microsoft Azure ML Studio
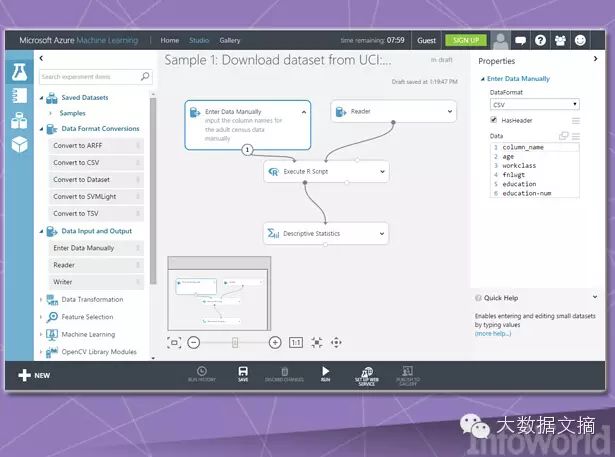
Depending on the actual data scale and computational performance requirements of machine learning tasks, the cloud often becomes an ideal operating environment for machine learning applications. Microsoft has launched its on-demand machine learning service, Azure ML Studio, which offers tiered versions including monthly, hourly, and free options. (Microsoft’s HowOldRobot project was also created using this system.)
Azure ML Studio allows users to create and train models and then convert them into APIs that can be consumed by other services. Each user account can provide up to 10 GB of storage for model data, but users can also connect their Azure storage resources to the service to accommodate larger models. The available algorithms are already quite substantial, provided by Microsoft itself and other third parties. Users don’t even need an account to experience this service; they can log in anonymously and use Azure ML Studio for up to eight hours.
◆ ◆ ◆
Amazon Machine Learning
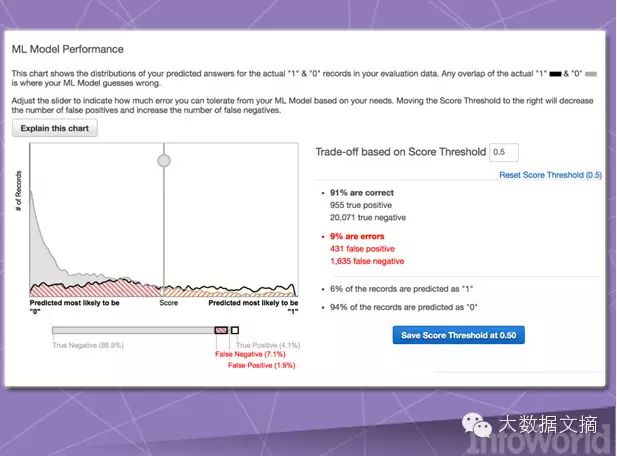
Amazon’s cloud service-oriented general solution follows a set pattern. It provides the operational foundation most core users are concerned about, helping them seek and deliver the machine learning solutions they need.
Amazon Machine Learning is also the first attempt by the cloud giant to launch machine learning as a service. It can access data stored in Amazon S3, Redshift, or RDS and can run binary classification, multiclass classification, or data recursion to create models. However, this service is highly dependent on Amazon itself. In addition to requiring data to be stored within Amazon, the resulting models cannot be imported or exported, and the training model’s database cannot exceed 100 GB. Of course, this is just the initial achievement of Amazon Machine Learning, which is sufficient to prove that machine learning is entirely feasible—rather than a luxury toy for tech giants.
◆ ◆ ◆
Microsoft Distributed Machine Learning Toolkit

The more devices we use to solve machine learning problems, the better the actual results—however, gathering a large number of devices and developing machine learning applications that can run smoothly across them is no easy task. Microsoft’s DMTK (Distributed Machine Learning Toolkit) framework can easily solve the distribution problems of various machine learning task types across a whole system cluster.
The billing mechanism of DMTK belongs to the framework rather than a complete out-of-the-box solution, so the actual number of algorithms involved is relatively small. However, DMTK is designed to allow users to expand later while utilizing the limited resources within existing clusters. For example, each node in the cluster has a local cache that can be provided with parameters for the current task by the central server node, thereby reducing actual traffic volume.
◆ ◆ ◆
Google TensorFlow
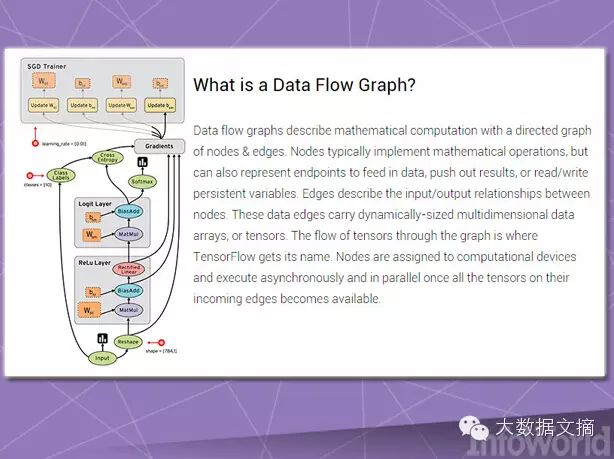
Similar to Microsoft’s DMTK, Google TensorFlow is a machine learning framework specifically designed for multi-node scale. Like Google’s Kubernetes, TensorFlow was initially tailored for Google’s internal needs, but the company ultimately decided to release it as an open-source product.
TensorFlow can implement what is known as a data flow graph, in which batch data (i.e., ‘tensor’, meaning tensor) can be processed through a series of algorithms described by the graph. The data moving within the system is referred to as “flow,” and can be processed by either the CPU or GPU. Google’s long-term plan is to promote the subsequent development of the TensorFlow project through third-party contributors.
◆ ◆ ◆
Microsoft Computational Network Toolkit
Taking advantage of the launch of DMTK, Microsoft also released another machine learning toolkit, the Computational Network Toolkit—or CNTK for short.
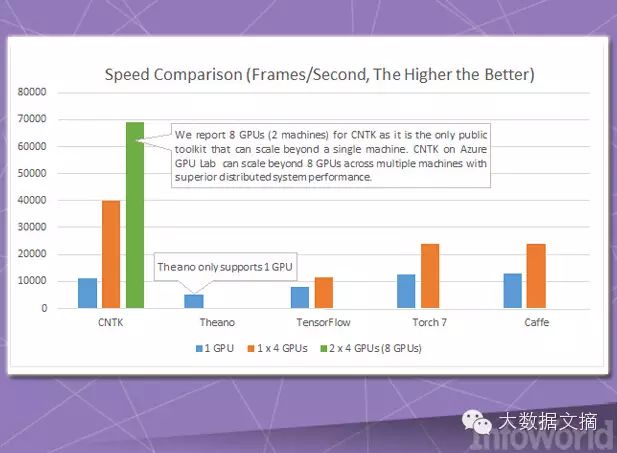
CNTK is very similar to Google TensorFlow, as it allows users to build neural networks using directed graphs. Additionally, Microsoft regards it as a technological achievement comparable to projects like Caffe, Theano, and Torch. Its main highlight is its outstanding speed performance, especially when leveraging the capabilities of multiple CPUs and GPUs in parallel. Microsoft claims that it has significantly increased the training speed of the Cortana speech recognition service using CNTK in conjunction with GPU clusters on Azure.
Originally developed as part of Microsoft’s speech recognition project, CNTK was eventually released to the public as an open-source project in April 2015—but it was later re-released on GitHub under a more permissive MIT license.
◆ ◆ ◆
Veles (Samsung)
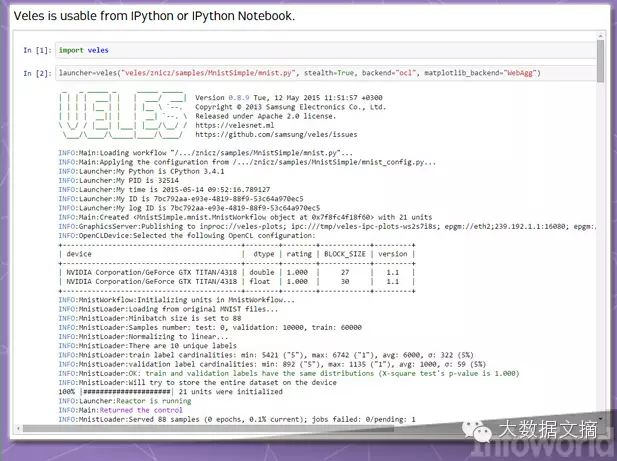
Veles is a distributed platform for deep learning applications, and like TensorFlow and DMTK, it is also written in C++—but it uses Python to execute automation and collaboration tasks between different nodes. The related datasets can be analyzed and automatically standardized before being supplied to the cluster, and it also has a REST API to allow trained models to be immediately added to the production environment (assuming the hardware is ready).
Veles does not simply use Python as its glue code. The IPython (now renamed Jupyter) data visualization and analysis tool can visualize and publish results from the Veles cluster. Samsung hopes to release this project as open-source to promote its further development—such as targeting Windows and Mac OS X.
◆ ◆ ◆
Brainstorm
Developed by Swiss PhD student Klaus Greff in 2015, the Brainstorm project aims to “help deep neural networks achieve speed, flexibility, and fun.” It currently includes a series of common neural network models, such as LSTM.
Brainstorm uses Python code to provide two sets of “handlers,” or data management APIs—one from the Numpy library for CPU computation, and the other through CUDA for utilizing GPU resources. Most of the work is done by Python scripts, so users cannot expect a rich GUI front-end—they need to connect the relevant interface themselves. However, from a long-term planning perspective, it can utilize “learning experiences from various early open-source projects” while incorporating “new design elements compatible with various platforms and computational backends.”
◆ ◆ ◆
mlpack 2
The mlpack library, based on C++, was initially created in 2011, and its design leans towards “scalability, speed, and usability,” as its builders point out. Users can run mlpack through the command line executable cache for fast execution, “black box” operations, or use the C++ API for other more complex tasks.
Its 2.0 version features a series of refactorings and new features, including multiple new algorithms and modifications to existing algorithms to improve execution speed or reduce their size. For example, it can point the Boost library’s random number generator to the native random functionality of C++ 11.
The inherent disadvantage of mlpack is its lack of bindings for any other languages besides C++, which means users of various other languages from R to Python cannot use mlpack—unless other developers release their corresponding language packages. Currently, the project is actively adding support for MatLab, but such projects tend to be more directly aimed at mainstream environments that host machine learning tasks.
◆ ◆ ◆
Marvin

As another newly born solution, the Marvin neural network framework is a development result of the Princeton Vision group. It is said to be “born to hack,” as the project developers directly state in its documentation, and it can run with just a few files written in C++ and the CUDA GPU framework. Although its code size is very small, it still contains a considerable amount of reusable parts and can accept pull requests as contributions to the project’s own code.
◆ ◆ ◆
Neon
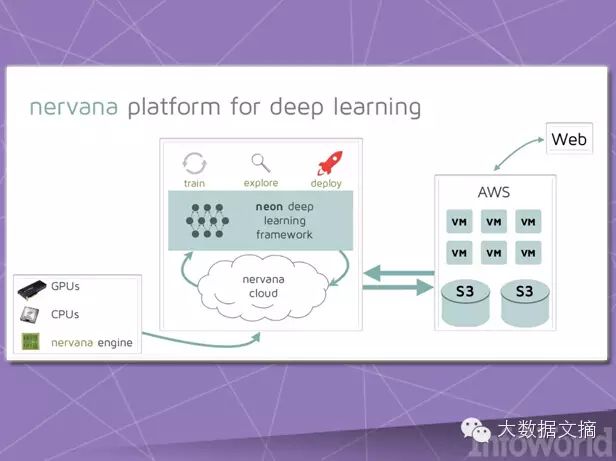
Nervana has built its own deep learning hardware and software platform, launching a deep learning framework called Neon as an open-source project. This project uses pluggable modules to support high-intensity loads running on CPU, GPU, or Nervana’s customized hardware.
Neon is primarily written in Python, with C++ providing several code snippets that contribute to significant execution speed. These features make Neon an ideal solution for data science scenarios or other Python-bound frameworks among Python developers.
Original link: http://developer.51cto.com/art/201602/505661.htm
Check out previous exciting articles by clicking on the images to read
-
Machine Learning: Interpreting Logistic Regression with Elementary Mathematics
-
Machine Vision and Deep Neural Networks—Removing the Glamour, A Glimpse of the Gems