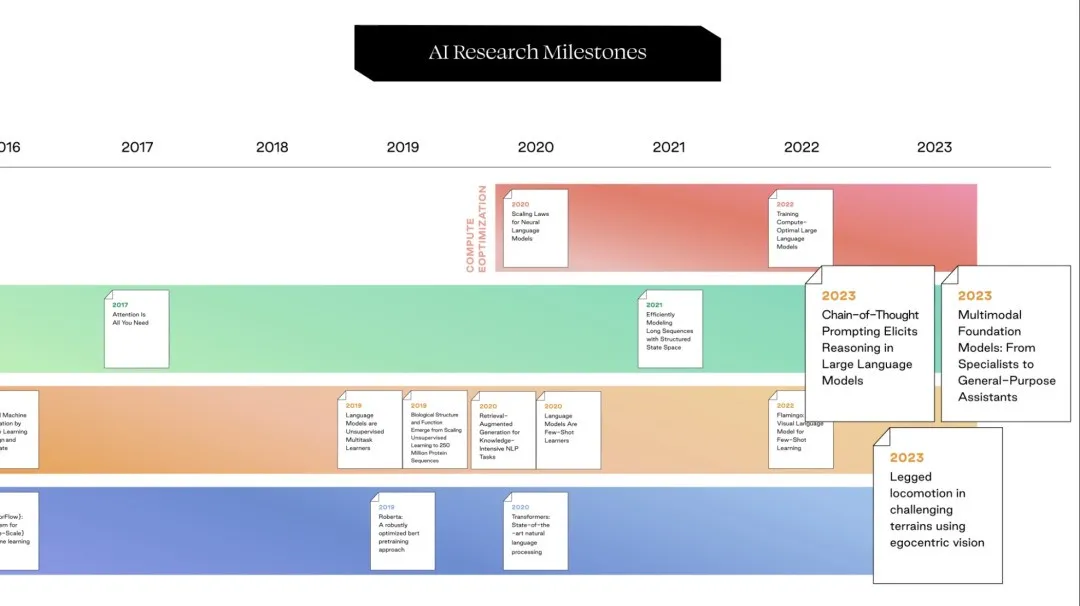
Source: AI Unconventional Frank
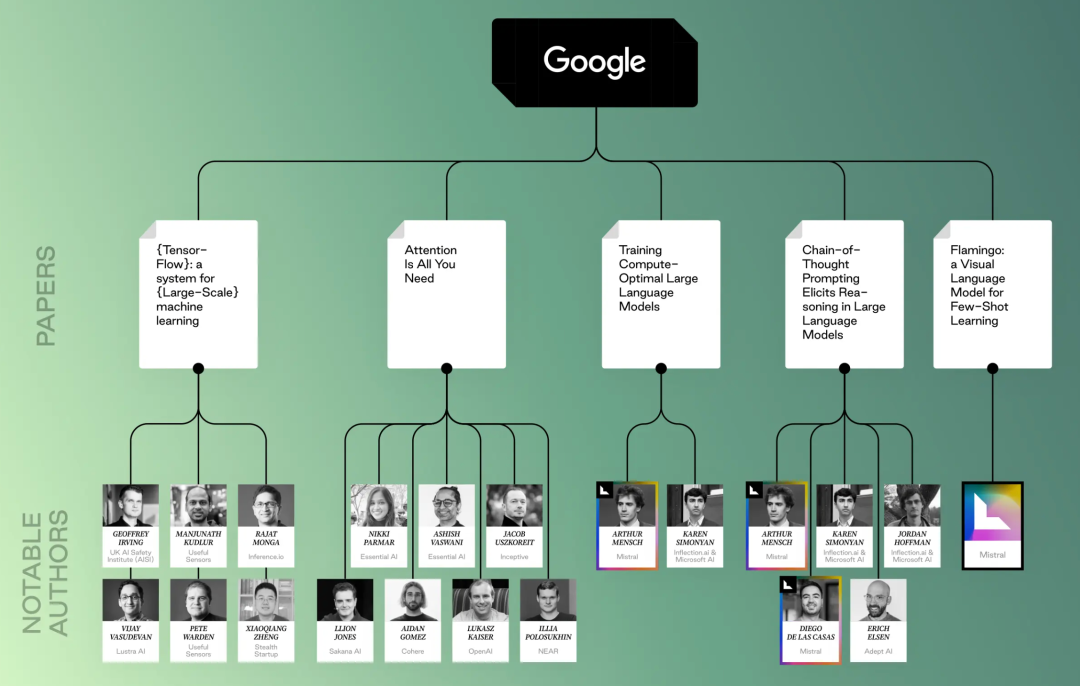
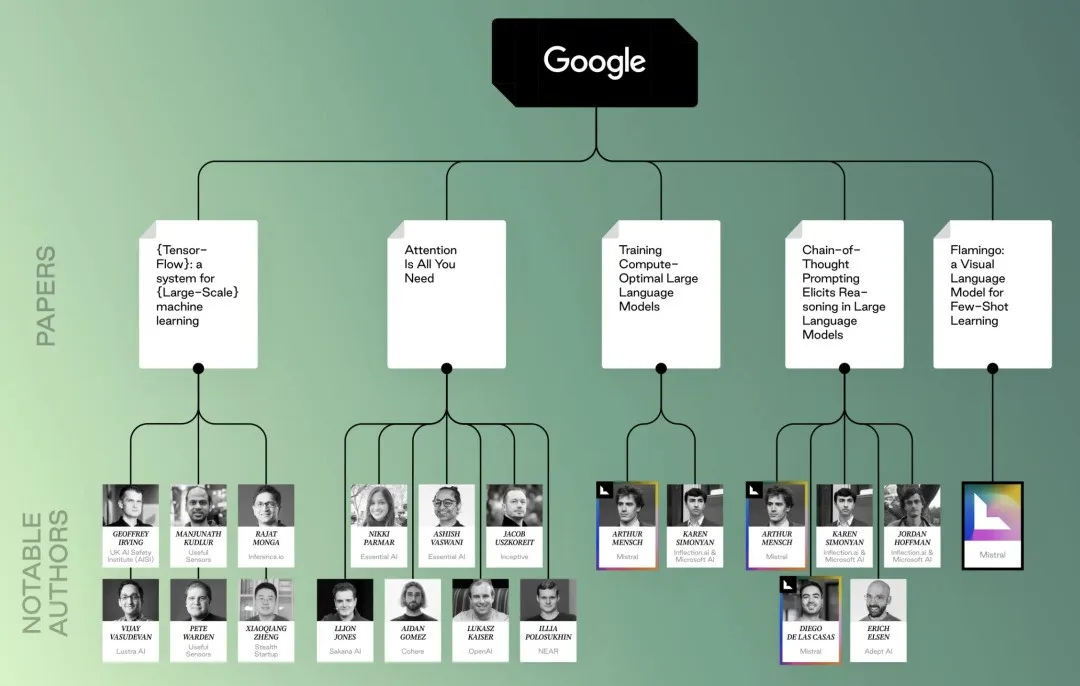 Google-related papers and researchers
Google-related papers and researchers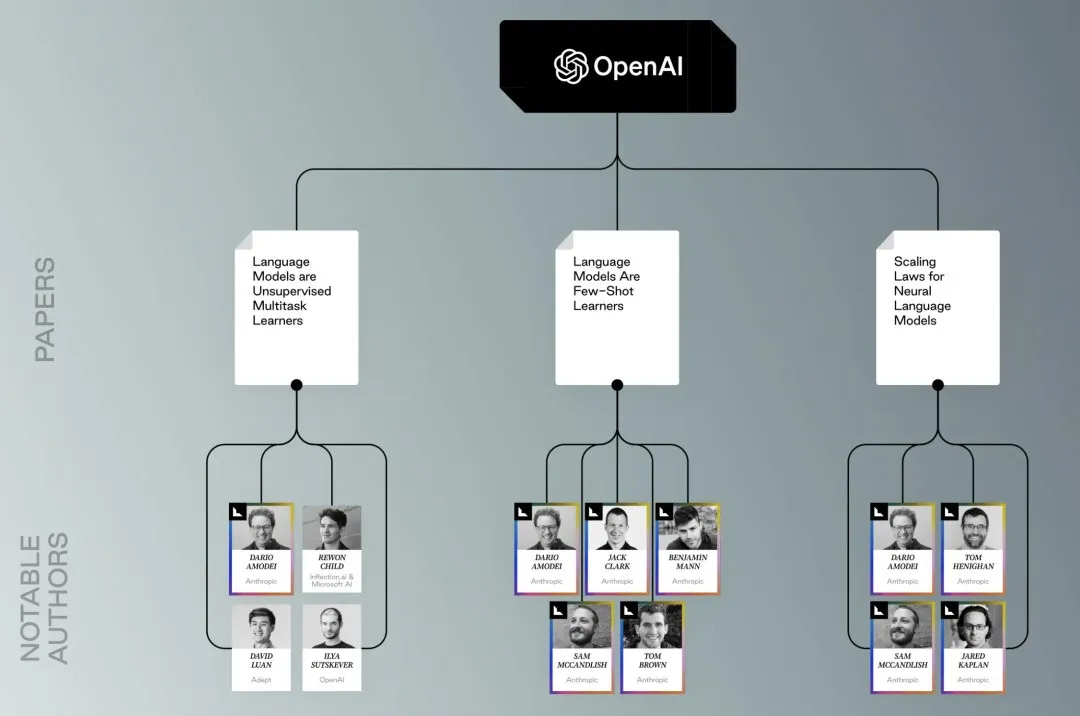 OpenAI-related papers and researchers
OpenAI-related papers and researchers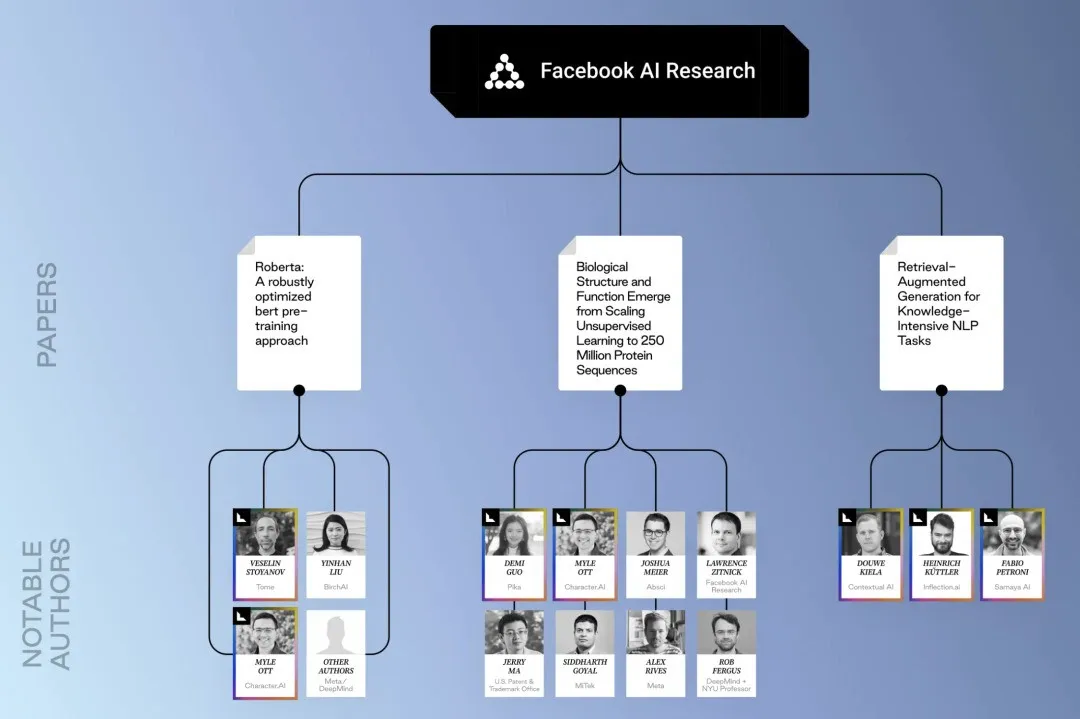 Facebook-related papers and researchers, pointing to the familiar Guo Wenjing (Pika)
Facebook-related papers and researchers, pointing to the familiar Guo Wenjing (Pika)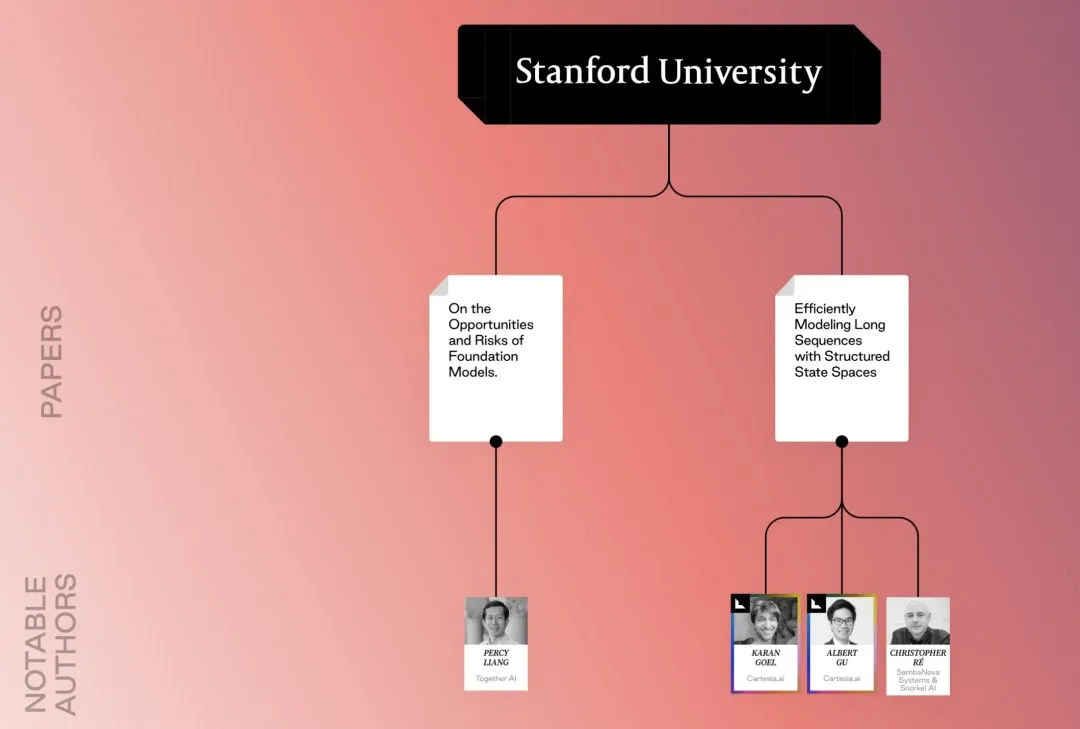

(End)
More exciting:
Principal Interview|Rooted in ethnic minority areas, focusing on teacher education to cultivate high-quality applied talents—Interview with Principal Chen Benhui of Lijiang Normal University
Yan Shi│A review and prospect of cultivating computer system capabilities
Discussion on the concept and implementation path of “student-centered” teaching
Principal Interview|Promoting interdisciplinary integration to cultivate innovative talents in the new era—Interview with Professor Ni Mingxuan, founding principal of Hong Kong University of Science and Technology (Guangzhou)
The New Year’s Message from the Seventh Editorial Committee
Guidelines for Ideological and Political Education in Computer Science Courses
Academician Chen Guoliang|Cultural construction of virtual teaching and research room for computer courses
Professor Chen Daoxu of Nanjing University|Change and Constancy: The Dialectics of the Learning Process
Yan Shi│Reflections and suggestions on the “dilemma” of young teachers in colleges and universities
Xu Xiaofei et al.|Metaverse education and its service ecosystem
【Contents】”Computer Education” 2024 Issue 6
【Contents】”Computer Education” 2024 Issue 5
【Contents】”Computer Education” 2024 Issue 4
【Contents】”Computer Education” 2024 Issue 3
【Editorial Message】Professor Li Xiaoming of Peking University: Reflections from the “Year of Classroom Teaching Improvement”…
Professor Chen Daoxu of Nanjing University: Which is more important, teaching students to ask questions or teaching students to answer questions?
【Yan Shi Series】: Development Trends in Computer Disciplines and Their Impact on Computer Education
Professor Li Xiaoming of Peking University: From interesting mathematics to interesting algorithms to interesting programming—one way for non-professional learners to experience computational thinking?
Several questions to consider in building first-class computer disciplines
New engineering and big data professional construction
Other mountains can attack jade—Compilation of Chinese and foreign research articles on computer education