
Author: Li Yuanyuan
This article is about 3000 words long, recommended reading time is 6 minutes.
This article introduces the evolution of the GPT model.
1 Overview of GPT Models
The GPT model, short for Generative Pre-trained Transformer, was developed by the OpenAI team and is a deep learning-based natural language processing model. It learns and abstracts large-scale text through unsupervised learning and is then fine-tuned for various specific natural language processing tasks.
The core of the GPT model is the Transformer architecture, a neural network structure used for sequence modeling. Unlike traditional Recurrent Neural Networks (RNNs), Transformers utilize a self-attention mechanism, allowing the model to better handle long sequences while achieving efficient parallel computation, thereby improving the model’s efficiency and performance.
The design intention of the model is to learn knowledge of natural language syntax, semantics, and pragmatics through unsupervised pre-training on large-scale text corpora. This pre-training method allows the GPT model to generate coherent and natural language text and adapt to various natural language processing tasks. Through fine-tuning, the GPT model can be optimized for specific tasks, showcasing powerful application capabilities in text generation, machine translation, speech recognition, and dialogue systems. With continuous technological advancements, multiple versions of the GPT model have been released, including GPT-1, GPT-2, GPT-3, and GPT-4. Each new version has improved upon the previous one, enhancing the model’s performance and applicability. For example, GPT-2 has a larger model size and a higher number of pre-training parameters, enabling it to produce more “fluent” and “coherent” language generation results; GPT-3 is currently the largest and most powerful version, capable of generating coherent and creative articles and dialogues based on given prompt texts.
Its derivative versions include InstructGPT, GPT-3.5, and ChatGPT; GPT-4 not only excels in language understanding and generation but also possesses multimodal processing capabilities, able to accept images as input and generate corresponding text output. Currently, there is no official news regarding the release date of GPT-5, but it is expected to be launched in the next few years. The release of GPT-5 may further advance the development of natural language processing and text generation technologies, having a profound impact in many fields.
It is evident that the GPT model, with its powerful pre-training capabilities, efficient Transformer architecture, and wide range of application fields, has become an important milestone in the field of natural language processing. With continuous technological development, the GPT model will continue to drive advancements in natural language processing technology and provide more intelligent and efficient language processing services.
2 GPT Model Architecture
The GPT model architecture is primarily based on the decoder structure of the Transformer, which is a deep learning model suitable for natural language processing and other sequence-to-sequence learning tasks. Its core components include the Attention Mechanism and Residual Connections. The Transformer architecture relied upon by the GPT model was first proposed by Google in the 2017 paper “Attention Is All You Need,” and its architecture diagram is as follows:

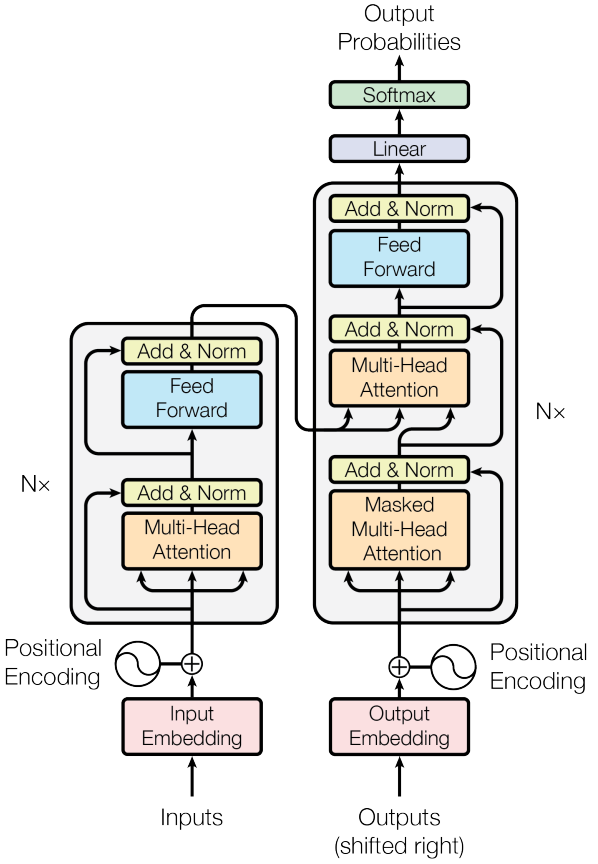
The diagram mainly consists of N encoders on the left and N decoders on the right. The Transformer can be simply understood to include the following steps:
1) N encoders, which obtain the features of the input text through the attention mechanism;
2) N decoders also work in a similar way, using the attention mechanism to obtain features of the current context;
3) Based on the context features obtained in step 2), and referring to the input text features obtained in step 1), predict the next output word;
4) Append the newly output word to the context, return to step 2) and continue looping until all outputs are completed.
Building upon the Transformer architecture, OpenAI described in its paper “Improving Language Understanding by Generative Pre-Training” the idea of simplifying the Transformer model architecture through self-attention mechanisms, establishing the architectural foundation of the GPT series by only using the decoder architecture. The specific architecture diagram is as follows:

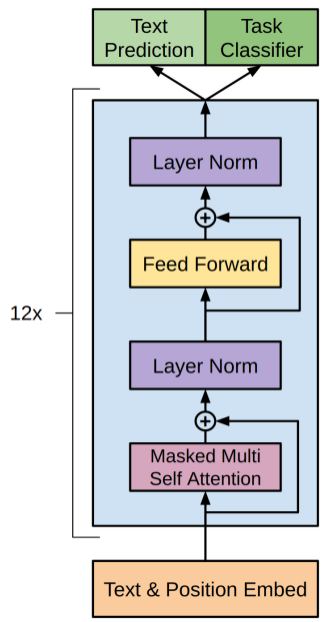
The GPT model encodes the input sequence into abstract feature representations through the encoder, while the decoder uses these feature representations to generate the target sequence. Between each sub-layer, the GPT model adds residual connections and layer normalization, which helps mitigate the potential gradient vanishing or explosion issues that may occur during the training of deep neural networks, improving the training stability and performance of the model.
In the self-attention layer, the input sequence is divided into multiple heads, each learning a different representation. Each head applies a weighting function similar to the attention mechanism to determine the importance of each position to others. This mechanism enables the model to efficiently process long sequence data and capture dependencies within the sequence.
In the feedforward neural network layer, the model inputs the output of the self-attention layer into a fully connected neural network to learn the nonlinear relationships between feature representations. This structure enhances the model’s representation learning capabilities, allowing it to capture more complex language patterns and structures.
Ultimately, the GPT model is composed of multiple such layers, generating target sequences or serving as outputs for tasks such as classification and regression. This architecture enables the GPT model to perform exceptionally well in natural language tasks, generating high-quality, coherent text content.
In summary, the design of the GPT model architecture fully leverages the advantages of the Transformer model, achieving efficient and stable natural language processing performance through techniques like the attention mechanism and residual connections. This makes the GPT model excel in various natural language processing tasks and provides strong support for the development of the artificial intelligence field.
3 Types of GPT Models
With the continuous development and advancement of technology, multiple versions of the GPT model have been released, each improving upon the previous version to enhance model performance and applicability. The main types of GPT models currently include:
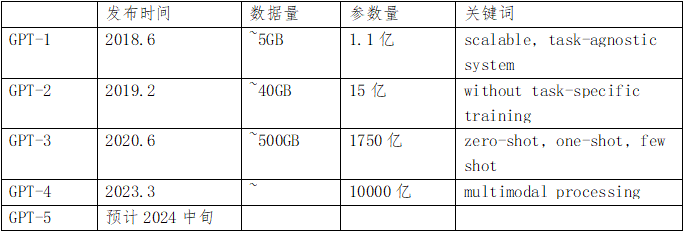
GPT-1: This is the first version of the GPT series, released in 2018. GPT-1 has 117 million parameters and uses the Transformer decoder structure as its foundation, employing a pre-trained language model. It has performed well on multiple natural language processing tasks such as text generation, machine translation, and reading comprehension. Although it performed well on certain tasks, the quality and coherence of the text generated by GPT-1 were relatively low.
GPT-2: GPT-2 is the second version of the GPT series, released in 2019. Compared to GPT-1, GPT-2 has significantly improved model size and pre-training data. GPT-2 has a larger model size, with the number of parameters increasing from 117 million in GPT-1 to 1.5 billion, and it uses more pre-training data. These improvements have enabled GPT-2 to exhibit greater creativity and language understanding capabilities in generation tasks, producing longer and more coherent text.
GPT-3: GPT-3 is the third version of the GPT series, released in 2020. GPT-3 is currently the largest and most powerful natural language generation model, with an astonishing 175 billion parameters. This enormous model size allows GPT-3 to handle more complex and diverse natural language processing tasks, including text generation, translation, question answering, and text classification. GPT-3 was trained on a vast amount of internet text data during pre-training, further enhancing its performance and generalization capabilities.
InstructGPT: InstructGPT is a new version of the GPT-3 model released in 2021. Unlike the base GPT-3 model, InstructGPT is optimized from the perspective of reinforcement learning and human feedback, improving the model’s authenticity and reducing harmful outputs.
GPT-3.5: OpenAI released a new version of GPT-3, called GPT-3.5, in March 2022. The GPT-3.5 model can edit text or insert content into text. The training data was up to June 2021, and by the end of November 2022, OpenAI officially referred to these models as GPT-3.5 models. In November 2022, OpenAI launched ChatGPT, presenting it as an experimental conversational model. ChatGPT excels in interactive dialogue through model fine-tuning.
GPT-4: GPT-4 is the fourth version of the GPT series, released in March 2023. It is a large, multimodal model with wide applications. Unlike other models in the OpenAI GPT family, GPT-4 is the first multimodal model capable of simultaneously receiving text and images as input. It can not only accept text input but also image input, generating corresponding text output. In various professional and academic benchmark tests, GPT-4’s performance is comparable to human levels, demonstrating its strong natural language processing capabilities. Compared to previous versions, GPT-4 has advanced reasoning abilities, capable of handling long articles exceeding 25,000 words. Additionally, GPT-4 provides high-quality outputs in various fields such as law, mathematics, science, and literature.
GPT-5: This is the next-generation large multimodal model, which will further improve and enhance the capabilities of GPT-4. The features of GPT-5 include the ability to handle more types of information such as audio and video, allowing it to perform a wider range of tasks such as generating images, editing videos, and composing music. GPT-5 is also equipped with personalized templates and automatic format conversion functions, allowing it to be customized based on user needs and input variables, automatically converting text into different formats. Moreover, GPT-5 aims to support multiple languages, becoming a valuable tool for language translation and other applications requiring multilingual support.
The table below summarizes the typical characteristics of some models in the GPT family.
In addition to the main versions of the GPT models mentioned above, with continuous technological advancements, more variants of the GPT models may emerge in the future. These variants may further optimize and innovate in model structure, parameter scale, training data, or application scenarios to meet the needs of different fields and tasks.
Author Biography:
Li Yuanyuan, graduated from the School of Information Management at Wuhan University, majoring in Information Resource Management, holds a master’s degree, and is currently a full-stack development engineer at Zhijiang Laboratory.
Feel free to leave comments and engage in discussions in the comment section!
Introduction to the Data Research Department
The Data Research Department was established in early 2017, dividing into multiple groups based on interest, each group adheres to the overall knowledge sharing and practical project planning of the research department while having its own characteristics:
Algorithm Model Group: Actively participates in competitions such as Kaggle, original hands-on teaching series articles;
Research and Analysis Group: Explores the beauty of data products through interviews and other methods;
System Platform Group: Tracks the cutting edge of big data & AI system platform technologies, dialogues with experts;
Natural Language Processing Group: Focuses on practice, actively participates in competitions and plans various text analysis projects;
Manufacturing Big Data Group: Upholds the dream of becoming an industrial power, combining industry, academia, and government to explore data value;
Data Visualization Group: Merges information with art, explores the beauty of data, and learns to tell stories with visualization;
Web Crawler Group: Crawls web information and collaborates with other groups to develop creative projects.
Click on the end of the article “Read the Original” to sign up for “Data Research Department Volunteers”, there is always a group suitable for you!
Reprint Instructions
If reprinting is needed, please prominently indicate the author and source at the beginning (Source: Data Research Department THUID: DatapiTHU), and place a prominent QR code of Data Research Department at the end of the article. For articles with original identification, please send [Article Name – Pending Authorized Public Account Name and ID] to the contact email to apply for whitelist authorization and edit as required.
Unauthorized reprints and adaptations will be legally pursued.
 Click “Read the Original” to join the organization!
Click “Read the Original” to join the organization!