
1
This article starts from basic concepts to introduce and explain a series of key technologies used by ChatGPT, such as machine learning, neural networks, large models, pre-training + fine-tuning paradigm, and Scaling Law… It also looks ahead to the potential application areas of multimodal agents represented by ChatGPT. We hope to help readers gain a deeper understanding and use of tools represented by ChatGPT, empowering them to become pioneers in the era of artificial intelligence.

On November 30, 2022, an obscure company (OpenAI) quietly launched a product called ChatGPT. At that time, no one expected this product to become a global sensation in just a few months; the release of GPT-4 on March 14, 2023, further sparked a technological revolution in artificial intelligence generated content (AIGC). For the average person, facing this artificial intelligence product that is bringing tremendous changes to production and life, countless questions inevitably arise:
● Why has ChatGPT attracted such great attention?
● What is its principle?
● Does it really possess human intelligence?
● What changes will it bring to human society?
……
Overview of ChatGPT’s Principle: A Word Chain Game
The most impressive ability of ChatGPT is its capability to answer users’ questions through dialogue. So, what is the principle behind ChatGPT’s answers? Traditional question-and-answer systems are essentially based on databases and search engines, which search for relevant information on the internet and databases and then return the results directly to the user. For example, when we search for “What is the principle of machine learning” on Baidu, it will redirect us to various websites. These websites were developed by various enterprises in advance, and Baidu merely sorted them based on relevance.
Unlike traditional question-and-answer systems where answers come from ready-made networks or databases, ChatGPT’s answers are automatically generated as questions are asked. This is somewhat like a word chain game, where ChatGPT continuously generates the next appropriate word based on what has been said before, until it decides that no further generation is necessary.
For instance, if we ask ChatGPT: “Is an apple a fruit?” ChatGPT will perform a word chain based on this sentence, and the process is roughly as follows:
(1) Consider the next possible word and its corresponding probability, as shown in the right table (only three possible forms are written for ease of understanding).
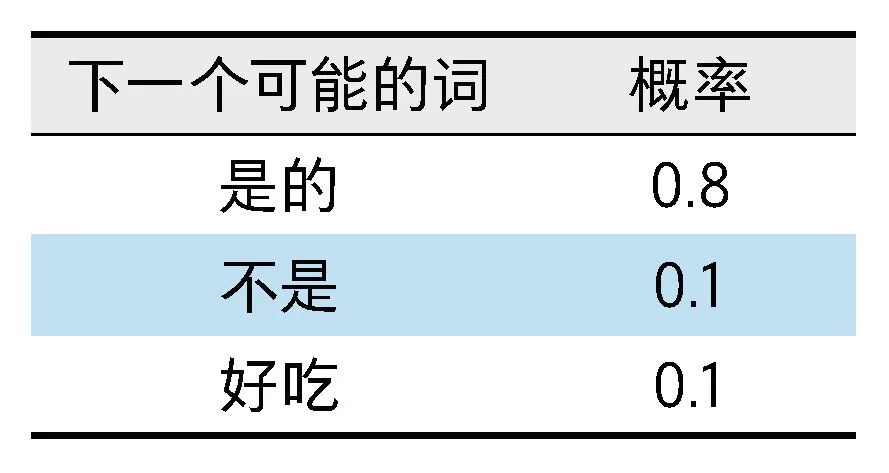
(2) Based on the above probability distribution, ChatGPT will choose the answer with the highest probability, which is “Yes” (because its probability of 0.8 is significantly higher than the other options).
(3) At this point, the content of this sentence becomes “Is an apple a fruit? Yes”; ChatGPT will check what the next possible word and corresponding probability are.
This step is repeated until a complete answer is obtained.
From the above example, we can see:
(1) Unlike traditional question-and-answer systems based on databases or search engines, ChatGPT’s answers are automatically generated after the user inputs a question.
(2) This generation is essentially a word chain game, simply put, it continually selects the word with the highest probability from all possible words to generate.
Some clever readers may wonder, how does ChatGPT know which word to choose and how does it provide the probabilities for each possible word? This is precisely the magic of machine learning technology.
The Core of Machine Learning: Mimicking Human Learning
ChatGPT is a very typical application of machine learning. So, what is machine learning?
The overall idea of machine learning is to draw on the process of human learning. Humans observe and inductively learn the actual conditions of the objective world and learn relevant laws from them. When facing an unknown situation, they use the laws they have learned to solve unknown problems. Similarly, we hope that computers can automatically discover some “laws” from massive amounts of data and apply these laws to new problems. These laws in the field of machine learning are called “models,” and the learning process is referred to as training the model.
Cartoon Illustration of Machine Learning and Model Training
Regarding model training, there is actually an assumption behind all machine learning models: the learned laws can be represented mathematically. The core of machine learning is to find a mathematical function that can closely approximate the true mathematical expression of the real world. However, many times humans do not know what the true mathematical representation looks like and cannot obtain it through traditional mathematical deduction; the only thing humans have is a pile of data derived from real situations. The method of machine learning is to use this data (training data) to train our model, allowing the model to automatically find a good approximate result. For example, in the application of facial recognition, the goal is to find a function where the input is a facial photo and the output is to determine which person corresponds to that photo. However, humans do not know the form of the facial recognition function, so they take a large number of facial photos and label each face with the corresponding person, and hand them to the model for training, allowing the model to automatically find a good facial recognition function. This is what machine learning does.
Neural Networks and Neurons: Scalable Mathematical Expression Capability
Having understood what machine learning is, the next concept is the mathematical expression capability of machine learning models. The essence of machine learning models is to get as close as possible to the function corresponding to the real world. However, just as we cannot expect to create exquisite works of art with just a few straight lines, if the machine learning model itself is relatively simple, like the linear function learned in high school
Y=kx+b
Then it can never learn a complex function, no matter what. Therefore, an important consideration for machine learning models is their mathematical expression capability. When faced with a complex problem, we hope that the model’s mathematical expression capability is as strong as possible, so that the model has the potential to learn well.
Over the past few decades, scientists have invented many different machine learning models, among which the most influential is a model called “neural networks.” The neural network model was initially based on a biological phenomenon: the basic architecture of human neurons is very simple, capable only of doing some basic signal processing work, but ultimately the brain can perform complex thinking. Inspired by this, scientists began to think about whether they could construct some simple “neurons” and connect them to form a network, thereby producing the ability to process complex information.
Based on this, the basic unit of a neural network is a model of a neuron, which can only perform simple calculations. Assuming the input data has two dimensions (x1, x2), then this neural network can be written as
y=σ(w1x1+w2x2+b)
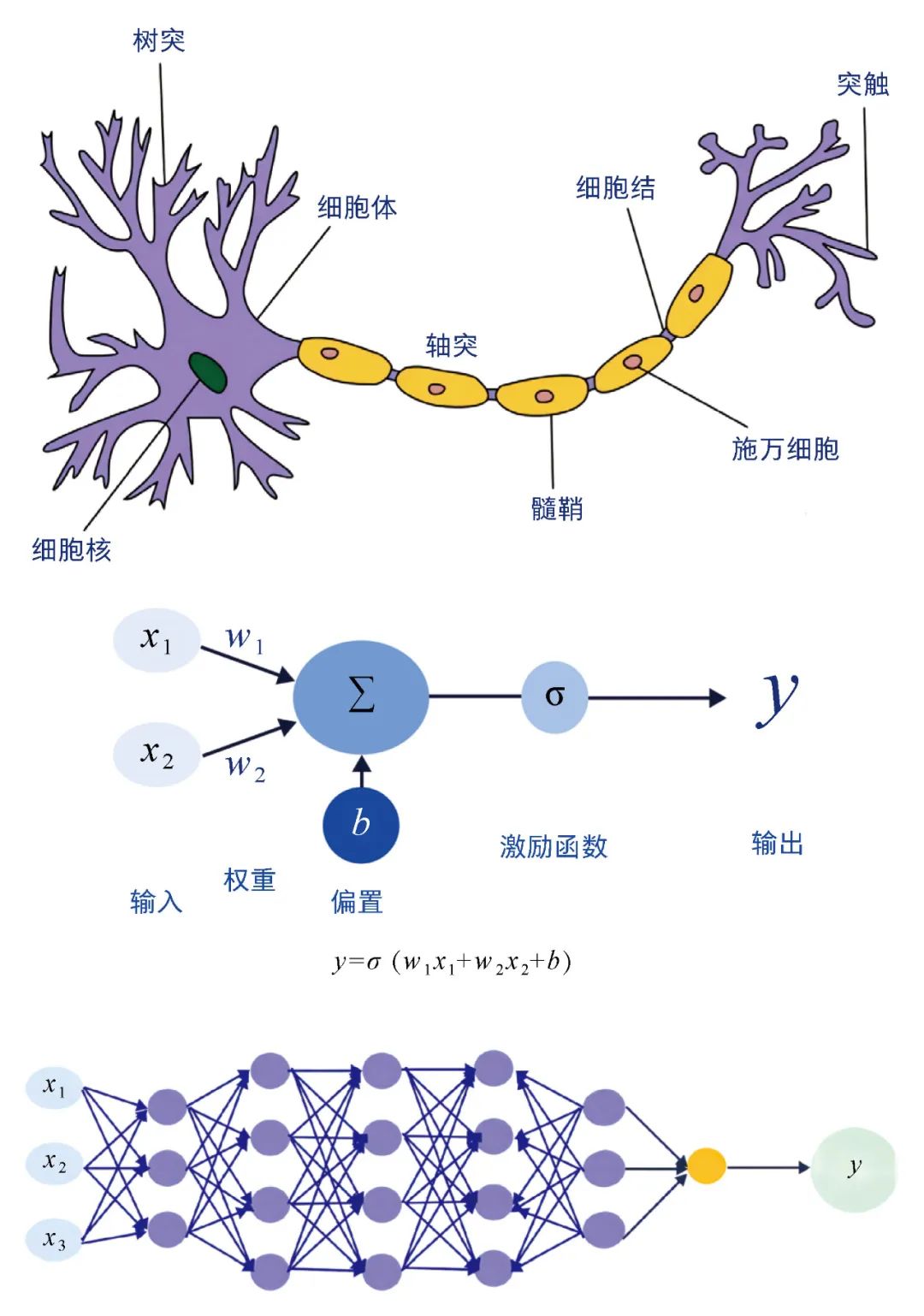
From Neurons to Neural Networks (a) Neuron Architecture (Biological); (b) Basic Neuron Architecture (Artificial Intelligence); (c) Simple Multilayer Perceptron.
The mathematical expression capability of the above neuron is very weak; it is merely a combination of a simple linear function and an activation function. However, we can easily make the model more powerful by increasing the number of “hidden nodes.” At this point, although each node still performs very simple calculations, the combination of them will result in a strong mathematical expression capability. Interested readers can try to write the formula corresponding to the simple multilayer perceptron in the diagram above, and they will obtain a very complex formula. This model is also the basic model of deep learning, namely the multilayer perceptron[1].
The principle of the multilayer perceptron is very simple, but it provides a good understanding of the principles of neural networks: although a single neuron is very simple, the combination of a large number of nodes can give the model a very strong mathematical expression capability. The entire technical route of deep learning, to some extent, has advanced along the path of developing and training larger and deeper networks.
New Paradigm of Deep Learning: Pre-training + Fine-tuning Paradigm and Scaling Law
The field of deep learning began to flourish in 2012, with larger, deeper, and better-performing models constantly emerging. However, as models became increasingly complex, the cost of training models from scratch became higher and higher. Thus, some proposed whether it was possible to train not from scratch but on the basis of models that had already been trained, achieving better results at a lower cost.
For example, scientists split an image classification model to study what the many layers of deep learning models have learned[2]. They found that the closer to the input layer, the more basic information the model learns, such as edges, corners, textures, etc.; the closer to the output layer, the more advanced combinatorial information it learns, such as the shapes of roosters, boats, etc. This characteristic exists not only in the image domain but also in many fields such as natural language and voice.
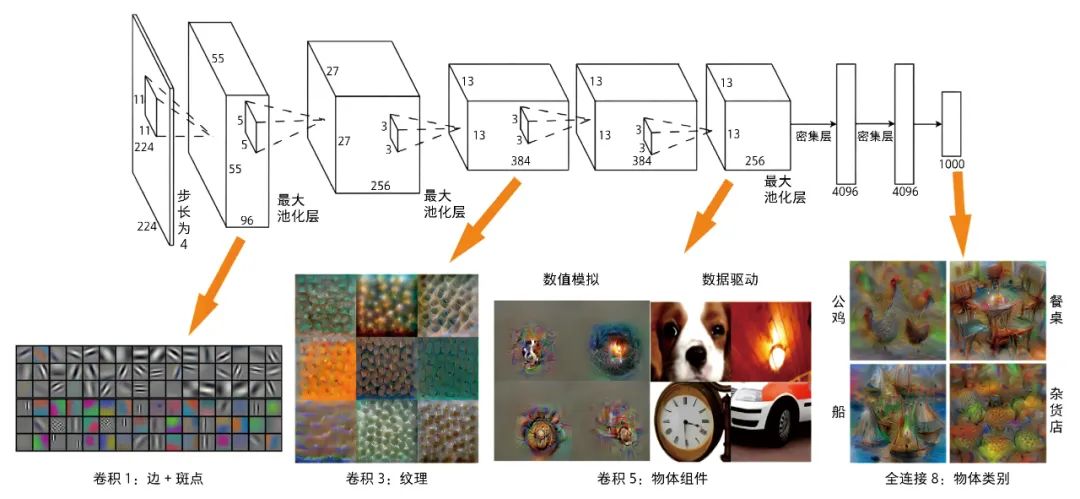
Outputs from Different Layers in Deep Neural Networks Information close to the input layer (left) is generally basic information, while information close to the output layer (right) is generally information about a specific object, etc.[2].
Basic information is often general information across fields, such as edges, corners, and textures in the image domain, which are used in various image recognition tasks; while advanced combinatorial information is often specific to a particular field, such as the shape of a cat, which is only useful in animal recognition tasks but not in facial recognition tasks. Therefore, a natural logic is to train a general model that learns general information across fields using commonly available data; when facing a specific scenario, it is sufficient to conduct small-scale training (fine-tuning) using data from that scenario. This is the famous pre-training + fine-tuning paradigm.
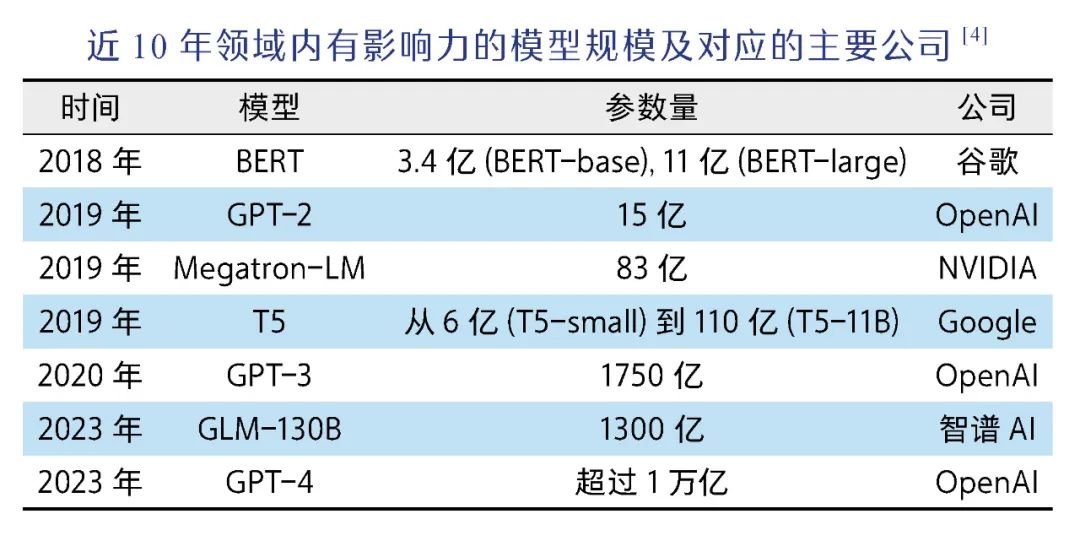
The emergence and popularization of the pre-training + fine-tuning paradigm has two significant impacts on the field. On the one hand, fine-tuning on existing models greatly reduces costs; on the other hand, the importance of a good pre-trained model has become more prominent, leading major companies and research institutions to be more willing to invest significant resources in training more expensive foundational models. So, what factors affect the performance of large models? OpenAI proposed the famous Scaling Law in 2020, which states that as the model scale increases, the performance of the model is mainly influenced by the scale of model parameters, the scale of training data, and the scale of computational power used[3].
The positive aspect of the Scaling Law is that it points to a direction for improving model performance: as long as the model and data scales are increased, it can be done. This is why in recent years the scale of large models has been growing exponentially, and the basic computational resources, graphics processing units (GPUs), are always in short supply; however, the Scaling Law also reveals a fact that has left many scientists in despair: that each step of improvement in the model requires humans to “exchange” with extremely exaggerated computational and data costs. The cost threshold for large models has become extremely high, and training large models from scratch has become a luxury in academia, with industry leaders like OpenAI, Google, Meta, Baidu, and Zhipu AI taking the lead.
The Ambition of GPT: In-context Learning and Prompt Engineering
In addition to hoping to improve performance by training models at a massive scale, the GPT model also has a very grand ambition during its development: in-context learning.
As mentioned earlier, in the past, if we wanted the model to “learn” something, we needed to train our model using a massive dataset. Even in the pre-training + fine-tuning paradigm mentioned earlier, it still requires training with a small batch of data on top of an already trained model (i.e., fine-tuning). Therefore, in the past, “training” has always been the core concept in machine learning. However, OpenAI proposed that training itself comes with costs and thresholds, and they hope that when the model faces new tasks, it does not require additional training, but can automatically learn by just providing some examples in the dialogue window. This mode is called in-context learning.
For example, in the case of Chinese-English translation, in the past, a massive Chinese-English dataset was needed to train a machine learning model for translation; however, in in-context learning, to accomplish the same task, it only requires giving the model some examples, such as telling the model:
Here are some examples of Chinese translated into English:
I love China → I love China
I like coding → I love coding
Artificial intelligence is important → AI is important
Now I have a Chinese sentence, please translate it into English. The sentence is: “I want to eat an apple today”.
At this point, the originally “dumb” model suddenly possesses the ability to translate automatically.
Readers who have used ChatGPT will find that this input is a prompt. In today’s world where ChatGPT is widely used, many people are unaware of how miraculous this is. It is like finding a child who has never learned English and showing him a few Chinese-English translation sentences, and that child can then fluently translate between Chinese and English. It is important to note that this model has never been specifically trained on a Chinese-English translation dataset, meaning that the model itself does not have the ability to translate between Chinese and English, but it suddenly “awakens” to the ability to translate through some examples in the dialogue, which is truly amazing!
The mechanisms related to in-context learning remain a hot topic of discussion in academia today. Precisely because the GPT model possesses the ability of in-context learning, a good prompt is crucial. Prompt engineering has gradually become a hot field, and even a new profession called “prompt engineer” has emerged, which involves writing better prompts to maximize the effectiveness of ChatGPT.
The principles of ChatGPT can be summarized as follows:
(1) ChatGPT is essentially playing a word chain game, where it selects the next word based on the probabilities of candidate words.
(2) Behind ChatGPT is a very large neural network; for example, GPT-3 has 170 billion parameters (training costs exceeding 1 million USD).
(3) Based on the large neural network, when faced with a sentence, the model can accurately provide the probabilities of candidate words, thus completing the word chain operation.
(4) This model, which processes language at a massive scale, is also called a large language model.
(5) Large language models represented by GPT possess in-context learning capabilities, making a good prompt essential.
Having understood the principles of ChatGPT, some readers may further question: Although ChatGPT is amazing, it is ultimately a language model. Why do people have such high expectations of it?
The Future of ChatGPT: Multimodal AI Agents
To understand why ChatGPT has attracted such high attention, we can review the three recognized industrial revolutions in human civilization.
(1) The first industrial revolution, represented by Watt’s steam engine, essentially invented and used some simple machines to liberate human physical labor.
(2) The second industrial revolution, represented by the use of internal combustion engines and electricity, essentially solved the power problem of machines using various energy sources.
(3) The third industrial revolution, represented by electronics and information technology, essentially accelerated the efficiency of information collection, transmission, and processing through electronic information, further optimizing control over machines.
The essence of the industrial revolution is to replace human labor with machines, thereby liberating productivity. The first three revolutions liberated human labor from the perspectives of machines, power (energy), and control (electronics and information). Humans have already been able to command machines to produce through simple means. At this point, the direct problem faced by human civilization is how to liberate the brain as well. This question has become the core issue in artificial intelligence research: the ability to respond quickly and accurately to complex problems like domain experts—this is precisely the capability of ChatGPT.
On the surface, the capability of large language models represented by ChatGPT is to answer questions correctly; in reality, it can make accurate decisions on complex problems like the human brain, thereby connecting all links of human technology. For example, in the field of automated experiments, we used to spend a lot of time researching programmable robots and their precise control, hoping to replace humans in conducting scientific experiments. However, we ultimately found that scientists still need to determine the specific operation of synthesis experiments and provide detailed coding (in hardware or software form) to the robots. With ChatGPT, scientists only need to express their needs, and ChatGPT will automatically search for relevant materials and formulations in the literature database, then write the relevant robot instructions and instruct the robot to automatically synthesize the relevant materials, thus achieving true automated experiments[5]. Such AI robots, capable of automatically sensing the environment, making decisions, and taking actions, are called AI agents.
Since we hope that AI agents can handle complex situations in real life, the traditional capabilities of large language models to converse only through language are insufficient. AI agents require models to read various types of input, such as image information, sound information, sensor information, internet information, etc., and to perform appropriate actions based on the decisions made by the agents, such as outputting an image or sound, writing code, or operating robots to complete actions. This ability to process information and tasks using multiple different types of input or output modes is called multimodal; and agents with this capability are called multimodal AI agents. The large language models represented by ChatGPT effectively provide a powerful “brain” for multimodal AI agents, and the relevant scientific and technological advancements of the past will be interconnected at an unprecedented speed, believing that the AI assistant J.A.R.V.I.S. in “Iron Man” will become a reality in the near future.
Looking at ChatGPT again: Do large language models really possess intelligence?
The introduction to ChatGPT is coming to an end; however, with the emergence of ChatGPT, another question has sparked widespread controversy: Do large language models represented by ChatGPT really possess intelligence or even self-awareness? This question is actually subjective; for example, some scholars believe that ChatGPT is essentially a probability game of word chains, and there is no intelligence to speak of, let alone self-awareness. Meanwhile, others believe that the massive parameters of large language models may contain some understanding of human knowledge, and although it may not reach the level of “consciousness,” it can be considered to possess some intelligence.
The essence of these debates is that, in the field of deep learning, practical applications have far outpaced theoretical research on models. Looking to the future, on the one hand, we hope to see more advanced artificial intelligence algorithms and applications implemented to better facilitate our lives; on the other hand, we hope that humans can better understand the artificial intelligence models we create, thereby building safer and more reliable models that truly assist the progress of human society.
Author’s Profile
Wang Yibo: Director of the Teaching Division at DPTechnology, Head of the open source community of the AI for Science Institute, Beijing 100080. [email protected]
Wang Yibo: DPTechnology’s Director of the Teaching Division, Head of the open source community of AISI (AI for Science Institute, Beijing), Beijing 100080.

[1] Rumelhart D E, Hinton E G, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533–536.
[2] Wei D L, Zhou B L, Torralba A,et al. mNeuron: A matlab plugin to visualize neurons from deep models. (2015)[2024-07-05]. https://donglaiw.github.io/proj/mneuron/index.html.
[3] Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models. arXiv preprint arXiv: 2001.08361, 2020.
[4] Zhao W X, Zhou K, Li J, et al. A survey of large language models. arXiv preprint arXiv: 2303.18223, 2023.
[5] Boiko D A, MacKnight R, Kline B, et al. Autonomous chemical research with large language models. Nature, 2023, 624(7992): 570-578.
Keywords: ChatGPT Machine Learning Neural Networks Large Models Multimodal Agents■


Science magazine has been rated as
2022 Annual
Comprehensive Evaluation of Chinese Humanities and Social Sciences Journals AMI (A-level) Extended Journal


Editorial office mailing address for Science:
Room 1006, Century Publishing Park A, No. 159, Haojing Road, Minhang District, Shanghai
Postal Code: 201101



