Click on 'Xiao Bai Learns Vision' above, select 'Star' or 'Top'
Important content delivered at the first time

01
Introduction
A previous article introduced the installation and testing of Tesseract-OCR, which has already supported recognition of Chinese characters. Due to the high feedback from everyone, I decided to write another article mainly introducing the issues to pay attention to when using it for projects and some important function usages. This article mainly discusses how to achieve structured document analysis and related area positioning recognition in Tesseract-OCR.
02
Terminology
OEM – OCR Engine Mode
Tesseract-OCR supports LSTM starting from version 4.x, which can be set through the OEM parameter. The values of the oem parameter options are as follows:
0: Recognition engine before 3.x
1: Neural network LSTM recognition engine
2: Hybrid mode, traditional + LSTM
3: Default, use whichever is supportedPSM – Page Segmentation Mode
Tesseract-OCR supports structured analysis of each page document and outputs the results of structured analysis. PSM document structured analysis can obtain many useful document information. A total of 13 modes are supported, with the default PSM option parameter being PSM_AUTO=3. This option supports structured output information of the document including:
dict_keys([‘level’, ‘page_num’, ‘block_num’, ‘par_num’, ‘line_num’, ‘word_num’, ‘left’, ‘top’, ‘width’, ‘height’, ‘conf’, ‘text’]), among which the more important ones include:
'left', 'top', 'width', 'height' represent position information
'text' represents the coordinates of the upper left and lower right corners of each bounding box
'conf' represents confidence, with values between 0 and 100, values less than 0 should be automatically excludedOther useful options include:
0 Angle and language detection, do not recognize or analyze document structure
1 Angle + PSM modeMore models, too lazy to translate, please see below:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.03
Function Description
PSD Analysis Function
def image_to_data(image, lang=None, config='', nice=0, output_type=Output.STRING, timeout=0, pandas_config=None,)Supported in version 3.5 and above, analyzes and returns document structure, completing PSD analysis and output.
Document Angle and Language Detection
def image_to_osd(image, lang='osd', config='', nice=0, output_type=Output.STRING, timeout=0,):OSD detection, returns document rotation angle and language detection information
Code Demonstration Section
Using PSD to Achieve Document Structure Analysis
image = cv.imread("D:/images/text_xt.png")
h, w, c = image.shape
# Document structure analysis
config = ('-l chi_sim --oem 1 --psm 6')
dict = tess.image_to_data(image, config=config, output_type=tess.Output.DICT)
print(dict.keys())
print(dict['conf'])
n_boxes = len(dict['text'])Draw all BOX frames
# All document structures
text_img = np.copy(image)
for i in range(n_boxes):
(x, y, w, h) = (dict['left'][i], dict['top'][i], dict['width'][i], dict['height'][i])
cv.rectangle(text_img, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv.imwrite('D:/layout-text1.png', text_img)Display as follows:

Using conf attribute to filter BOX frames less than 0
# Filter after conf>0
for i in range(n_boxes):
if int(dict['conf'][i]) > 0:
(x, y, w, h) = (dict['left'][i], dict['top'][i], dict['width'][i], dict['height'][i])
cv.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv.imwrite('D:/layout-text2.png', image)
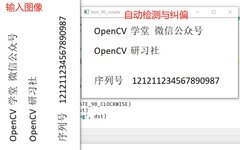
OSD Detection Document Tilt and Language Category
# Detect tilt angle
image = cv.imread("D:/images/text_90.png")
cv.imshow("text_90", image)
osd = tess.image_to_osd(image)
print(osd)
osd_array = osd.split("\n")
angle = int(osd_array[2].split(":")[1])
conf = float(osd_array[3].split(":")[1])
print("angle: ", angle)
print("conf: ", conf)
dst = cv.rotate(image, cv.ROTATE_90_CLOCKWISE)
cv.imshow("text_90_rotate", dst)
cv.imwrite('D:/layout-text3.png', dst)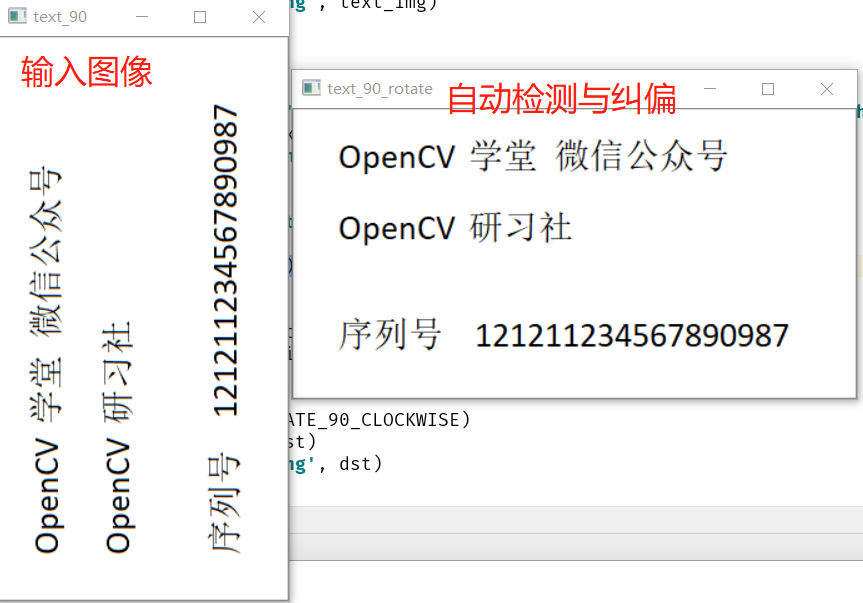
Detection Configuration and Whitelist Mechanism Filtering
# Only detect numbers
custom_config = r'--oem 1 --psm 6 outputbase digits'
ocr_result = tess.image_to_string(dst, config=custom_config)
print(ocr_result)
# Use whitelist method to only detect numbers
custom_config = r'-c tessedit_char_whitelist=0123456789 --psm 6'
ocr_result = tess.image_to_string(dst, config=custom_config)
print("Whitelist method number detection\n", ocr_result)
# Detect Chinese
ocr_result = tess.image_to_string(dst, lang="chi_sim")
print("\nChinese detection and output:\n", ocr_result.replace("\f", "").split("\n"))
# In the case of Chinese detection, only output numbers
ocr_result = tess.image_to_string(dst, lang="chi_sim", config=custom_config)
print("\nChinese detection + number output:\n", ocr_result.replace("\f", "").split("\n"))
cv.waitKey(0)
cv.destroyAllWindows()Running result:

In the last one, it can be seen that O was detected as 0, and others were OK! This is the Achilles’ heel of OCR, it can never tell the difference between 0 and O. Lastly, one more thing, Tesseract-OCR is correct only if the input is a binary image with a white background!
Good news!
Xiao Bai Learns Vision Knowledge Planet
Is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the backend of the 'Xiao Bai Learns Vision' public account to download the first OpenCV extension module tutorial in Chinese on the internet, covering more than twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of the 'Xiao Bai Learns Vision' public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of the 'Xiao Bai Learns Vision' public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (will gradually be subdivided in the future), please scan the WeChat number below to join the group, note: "nickname + school/company + research direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please note the format, otherwise it will not be approved. After successful addition, you will be invited to enter the relevant WeChat group according to your research direction. Please do not send advertisements in the group, otherwise you will be asked to leave the group, thank you for your understanding~