Click on the "Xiaobai Learns Vision" above, select to add "Star" or "Pin"
Heavyweight content delivered to you first
Jishi Guide
I personally believe that in the field of medical image segmentation, specifically abdominal organ segmentation or liver tumor segmentation, two aspects of knowledge must be mastered: (1) medical image preprocessing methods; (2) deep learning knowledge. The first point is a prerequisite for the second point, as you need to understand what kind of data is input into the DL network. This article mainly introduces common methods for reading and preprocessing medical images.
Recently, I have reviewed the methods for reading and preprocessing medical image data, and I would like to summarize them here.
When performing medical image data analysis based on deep learning, such as lesion detection, tumor or organ segmentation tasks, the first step is to have a general understanding of the data. However, when I first entered the field of medical image segmentation, I was very confused and didn’t know what to do or what knowledge to prepare. Gradually, I have established a rudimentary knowledge system. I personally believe that in the field of medical image segmentation, specifically abdominal organ segmentation or liver tumor segmentation, two aspects of knowledge must be mastered: (1) medical image preprocessing methods; (2) deep learning knowledge. The first point is a prerequisite for the second point, as you need to understand what kind of data is input into the DL network.
This article mainly introduces common methods for reading and preprocessing medical images.
1. Medical Image Data Reading
1.1 ITK-SNAP Software
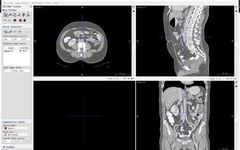
First, let me introduce the medical image visualization software ITK-SNAP, which can be used as a tool to intuitively perceive the 3D structure of medical images, and can also be used as a segmentation and detection box labeling tool. It is free, very useful, and I recommend it: ITK-SNAP official download address:http://www.itksnap.org/pmwiki/pmwiki.php. Additionally, mango (http://ric.uthscsa.edu/mango/) is another very lightweight visualization software that you can try. I usually use ITK-SNAP.
The usage of ITK-SNAP can refer to this blog post by a senior, which is very concise:
JunMa: Introduction to ITK-SNAP:
https://zhuanlan.zhihu.com/p/104381149
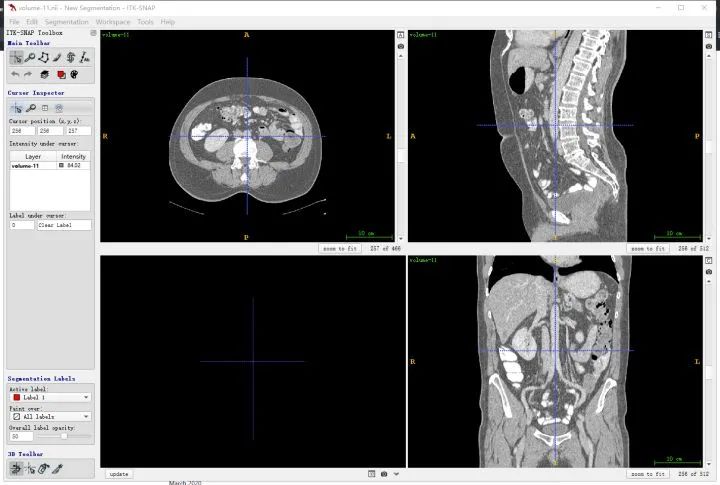
First, clarify the directions corresponding to the human body, where the three windows correspond to three planes, as shown in the figure below, indexed by letters. For example, the upper left image corresponds to the R-A-L-P plane, which is a cross-section viewed from the feet towards the head (i.e., the z direction), and the other two are similar.
You can also import segmentation results simultaneously for comparative observation.
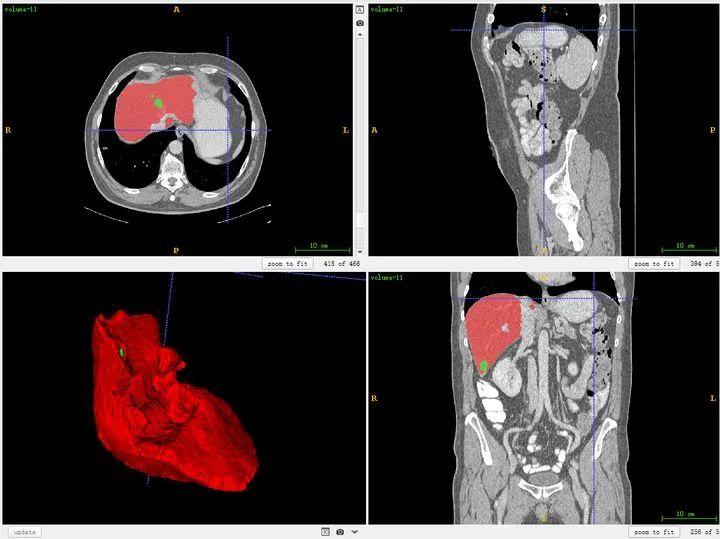
For areas with less precise labeling, you can refine them. Of course, for public datasets, most of them are quite good. Self-labeling is similar. (If the display is not clear and the contrast is too low, you need to adjust the window width and window level in the software.)
1.2 SimpleITK
We know that the most common medical images are CT and MRI, which are both three-dimensional data, and are more complex than two-dimensional data. Moreover, the saved data comes in many formats, commonly .dcm, .nii(.gz), .mha, .mhd(+raw). These types of data can be processed using Python’s SimpleITK, and additionally, pydicom can read and modify .dcm files.
The purpose of the reading operation is to extract tensor data from each patient’s data. Taking reading the .nii data above as an example with SimpleITK:
import numpy as np
import os
import glob
import SimpleITK as sitk
from scipy import ndimage
import matplotlib.pyplot as plt # Load required libraries
# Specify data root path, where data directory contains volume data and label contains segmentation data, both in .nii format
data_path = r'F:\LiTS_dataset\data'
label_path = r'F:\LiTS_dataset\label'
dataname_list = os.listdir(data_path)
dataname_list.sort()
ori_data = sitk.ReadImage(os.path.join(data_path,dataname_list[3])) # Read one of the volume data
data1 = sitk.GetArrayFromImage(ori_data) # Extract the array from the data center
print(dataname_list[3],data1.shape,data1[100,255,255]) # Print data name, shape and the value of a specific element
plt.imshow(data1[100,:,:]) # Visualize the 100th slice
plt.show()
Output result:
['volume-0.nii', 'volume-1.nii', 'volume-10.nii', 'volume-11.nii',...
volume-11.nii (466, 512, 512) 232.0
This indicates that the shape of the data is (466,512,512), and note that the corresponding order is z,x,y. z is actually the index of the slice. x and y are the width and height of a specific slice.
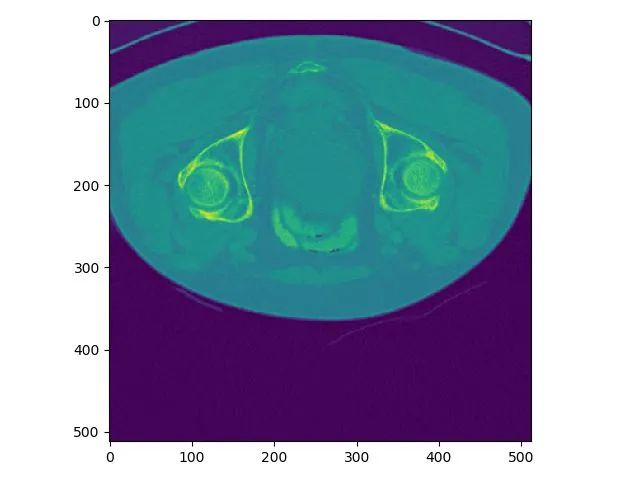
Plot result for z index 100:
The visualization result of the same slice in ITK-SNAP (note that here (x,y,z=(256,256,101)), because ITK-SNAP defaults to 1-based indexing):
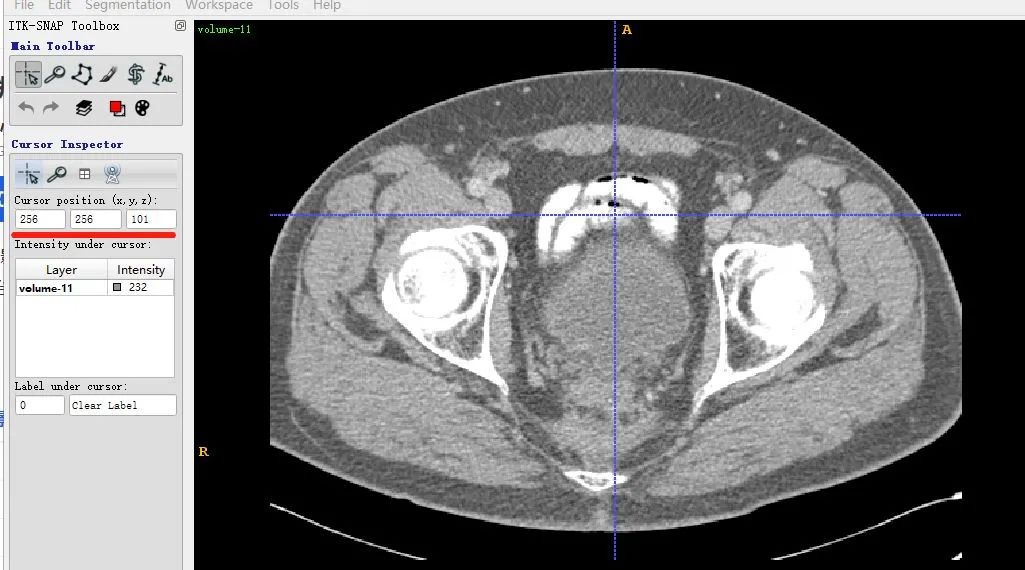
It can be seen that the x-axis of the two images is the same, but the y-axis direction is flipped up and down. This is due to the different display methods of matplotlib, but there will be no issue of misalignment in data reading.
For the processing of dicom and mhd, you can refer to this blog post:
Tan Qingbo: Common Medical Scanning Image Processing Steps:
https://zhuanlan.zhihu.com/p/52054982
2. Medical Image Preprocessing
This part of the content is relatively scattered. Because different tasks and different datasets usually have very different data preprocessing methods. However, the basic idea is to make the processed data more conducive to network training. Therefore, some methods of preprocessing two-dimensional images can be referenced, such as contrast enhancement, denoising, cropping, etc. Additionally, some prior knowledge of medical images can also be utilized, such as different affine doses (unit: HU) in CT images corresponding to different human tissues and organs.

Based on the above table, the original data can undergo normalization:
MIN_BOUND = -1000.0
MAX_BOUND = 400.0
def norm_img(image): # Normalize pixel values to (0,1), and cap overflow values at the boundary
image = (image - MIN_BOUND) / (MAX_BOUND - MIN_BOUND)
image[image > 1] = 1.
image[image < 0] = 0.
return image
You can also perform standardization/zero-centering to shift the data center to the origin:
image = image-mean
The above normalization processing is suitable for most datasets, while other operations are optional and specific to the data, including the above MIN_BOUND and MAX_BOUND, which are best referenced from the processing methods of excellent papers’ open-source codes.
It is recommended to save the preprocessed dataset locally to reduce resource consumption during training. Additionally, data augmentation steps such as random cropping and linear transformations still need to be performed during training.
References:
https://zhuanlan.zhihu.com/p/77791840
https://zhuanlan.zhihu.com/p/104381149
Tan Qingbo: Common Medical Scanning Image Processing Steps
Download 1: Chinese Version Tutorial for OpenCV-Contrib Extension Module
Reply "Chinese Tutorial for Extension Module" in the background of the "Xiaobai Learns Vision" public account to download the first Chinese version of the OpenCV extension module tutorial available online, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: 52 Lectures on Practical Python Vision Projects
Reply "Practical Python Vision Projects" in the background of the "Xiaobai Learns Vision" public account to download 31 practical vision projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: 20 Lectures on Practical OpenCV Projects
Reply "20 Practical OpenCV Projects" in the background of the "Xiaobai Learns Vision" public account to download 20 practical projects based on OpenCV, for advanced learning of OpenCV.
Discussion Group
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (which will gradually be subdivided in the future). Please scan the WeChat account below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes, otherwise, you will not be approved. After successful addition, you will be invited to join relevant WeChat groups based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~