Big Data Digest Production
Source:Medium
Compiled by:Zhao Jike
In recent years, there have been significant advancements in deep learning hardware, with Nvidia’s latest products, the Tesla V100 and Geforce RTX series, featuring dedicated tensor cores designed to accelerate common operations in neural networks.
Notably, the V100 has sufficient capability to train neural networks at thousands of images per second, allowing small models based on the ImageNet dataset to be trained on a single GPU in just a few hours, a stark contrast to the 5 days it took to train the AlexNet model on ImageNet in 2012!
However, powerful GPUs can overwhelm data preprocessing pipelines.To address this issue, TensorFlow released a new data loader: tf.data.Dataset, which is written in C++ and uses a graph-based approach to link multiple preprocessing operations together.
On the other hand, PyTorch uses a data loader written in Python on the PIL library, which is convenient and flexible but lacks speed (although the PIL-SIMD library has slightly improved this situation).
Enter NVIDIA’s Data Loading Library (DALI): It is designed to eliminate data preprocessing bottlenecks, allowing training and inference to run at full speed.DALI is primarily used for preprocessing on GPUs, but most operations also have fast implementations on CPUs.This article mainly focuses on PyTorch, but DALI also supports TensorFlow, MXNet, and TensorRT, with particular emphasis on TensorRT having high support.It allows the training and inference steps to use the exact same preprocessing code.It should be noted that different frameworks (like TensorFlow and PyTorch) often have slight differences between data loaders, which can affect accuracy.
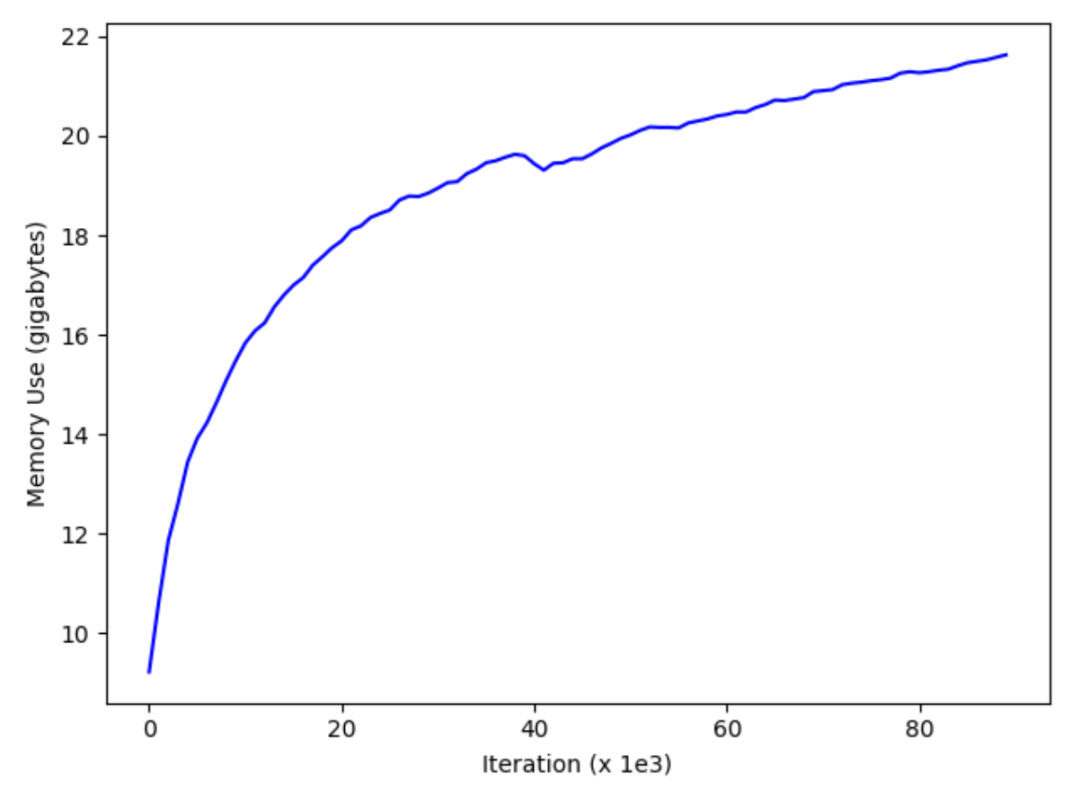
This article showcases techniques demonstrated by a blogger on Medium to enhance DALI’s utilization and create a fully CPU-based pipeline.These techniques are used to maintain long-term memory stability and can increase batch sizes by 50% compared to the CPU and GPU pipelines provided by the DALI package.
del self.train_loader, self.val_loader, self.train_pipe, self.val_pipe
import torch.cuda
import gc
import importlib
import dali
from dali import HybridTrainPipe, HybridValPipe, DaliIteratorCPU, DaliIteratorGPU
# <rebuild DALI pipeline>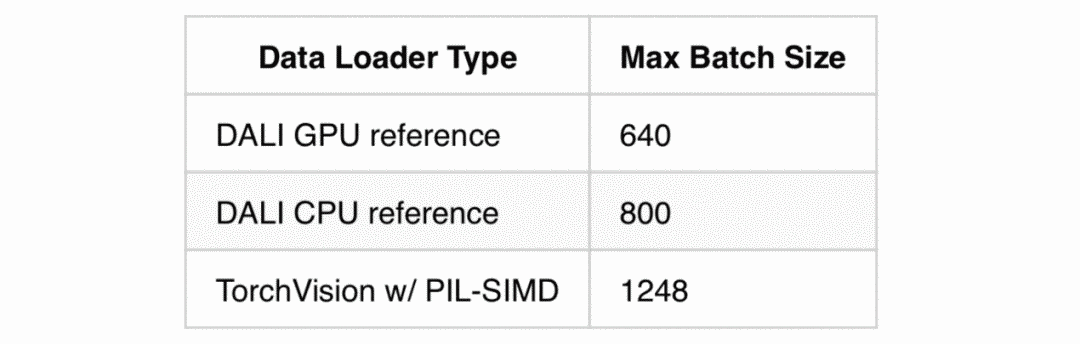
class HybridTrainPipe(Pipeline):
def __init__(self, batch_size, num_threads, device_id, data_dir, crop,
mean, std, local_rank=0, world_size=1, dali_cpu=False, shuffle=True, fp16=False,
min_crop_size=0.08):
# As we're recreating the Pipeline at every epoch, the seed must be -1 (random seed)
super(HybridTrainPipe, self).__init__(batch_size, num_threads, device_id, seed=-1)
# Enabling read_ahead slowed down processing ~40%
self.input = ops.FileReader(file_root=data_dir, shard_id=local_rank, num_shards=world_size,
random_shuffle=shuffle)
# Let user decide which pipeline works best with the chosen model
if dali_cpu:
decode_device = "cpu"
self.dali_device = "cpu"
self.flip = ops.Flip(device=self.dali_device)
else:
decode_device = "mixed"
self.dali_device = "gpu"
output_dtype = types.FLOAT
if self.dali_device == "gpu" and fp16:
output_dtype = types.FLOAT16
self.cmn = ops.CropMirrorNormalize(device="gpu",
output_dtype=output_dtype,
output_layout=types.NCHW,
crop=(crop, crop),
image_type=types.RGB,
mean=mean,
std=std,)
# To be able to handle all images from full-sized ImageNet, this padding sets the size of the internal nvJPEG buffers without additional reallocations
device_memory_padding = 211025920 if decode_device == 'mixed' else 0
host_memory_padding = 140544512 if decode_device == 'mixed' else 0
self.decode = ops.ImageDecoderRandomCrop(device=decode_device, output_type=types.RGB,
device_memory_padding=device_memory_padding,
host_memory_padding=host_memory_padding,
random_aspect_ratio=[0.8, 1.25],
random_area=[min_crop_size, 1.0],
num_attempts=100)
# Resize as desired. To match torchvision data loader, use triangular interpolation.
self.res = ops.Resize(device=self.dali_device, resize_x=crop, resize_y=crop,
interp_type=types.INTERP_TRIANGULAR)
self.coin = ops.CoinFlip(probability=0.5)
print('DALI "{0}" variant'.format(self.dali_device))
def define_graph(self):
rng = self.coin()
self.jpegs, self.labels = self.input(name="Reader")
# Combined decode & random crop
images = self.decode(self.jpegs)
# Resize as desired
images = self.res(images)
if self.dali_device == "gpu":
output = self.cmn(images, mirror=rng)
else:
# CPU backend uses torch to apply mean & std
output = self.flip(images, horizontal=rng)
self.labels = self.labels.gpu()
return [output, self.labels]def _preproc_worker(dali_iterator, cuda_stream, fp16, mean, std, output_queue, proc_next_input, done_event, pin_memory):
"""
Worker function to parse DALI output & apply final preprocessing steps
"""
while not done_event.is_set():
# Wait until main thread signals to proc_next_input -- normally
proc_next_input.wait()
proc_next_input.clear()
if done_event.is_set():
print('Shutting down preproc thread')
break
try:
data = next(dali_iterator)
# Decode the data output
input_orig = data[0]['data']
target = data[0]['label'].squeeze().long() # DALI should already output target
# Copy to GPU and apply final processing in separate CUDA stream
with torch.cuda.stream(cuda_stream):
input = input_orig
if pin_memory:
input = input.pin_memory()
del input_orig # Save memory
input = input.cuda(non_blocking=True)
input = input.permute(0, 3, 1, 2)
# Input tensor is kept as 8-bit integer for transfer to GPU, to save bandwidth
if fp16:
input = input.half()
else:
input = input.float()
input = input.sub_(mean).div_(std)
# Put the result
output_queue.put((input, target))
except StopIteration:
print('Resetting DALI loader')
dali_iterator.reset()
output_queue.put(None)
class DaliIteratorCPU(DaliIterator):
"""
Wrapper class to decode the DALI iterator output & provide iterator that functions in the same way as TorchVision.
Note that permutation to channels first, converting from 8-bit integer to float & normalization are all performed
"""
def __init__(self, fp16=False, mean=(0., 0., 0.), std=(1., 1., 1.), pin_memory=True, **kwargs):
super().__init__(**kwargs)
print('Using DALI CPU iterator')
self.stream = torch.cuda.Stream()
self.fp16 = fp16
self.mean = torch.tensor(mean).cuda().view(1, 3, 1, 1)
self.std = torch.tensor(std).cuda().view(1, 3, 1, 1)
self.pin_memory = pin_memory
if self.fp16:
self.mean = self.mean.half()
self.std = self.std.half()
self.proc_next_input = Event()
self.done_event = Event()
self.output_queue = queue.Queue(maxsize=5)
self.preproc_thread = threading.Thread(
target=_preproc_worker,
kwargs={'dali_iterator': self._dali_iterator, 'cuda_stream': self.stream, 'fp16': self.fp16, 'mean': self.mean, 'std': self.std, 'proc_next_input': self.proc_next_input, 'done_event': self.done_event, 'output_queue': self.output_queue, 'pin_memory': self.pin_memory})
self.preproc_thread.daemon = True
self.preproc_thread.start()
self.proc_next_input.set()
def __next__(self):
torch.cuda.current_stream().wait_stream(self.stream)
data = self.output_queue.get()
self.proc_next_input.set()
if data is None:
raise StopIteration
return data
def __del__(self):
self.done_event.set()
self.proc_next_input.set()
torch.cuda.current_stream().wait_stream(self.stream)
self.preproc_thread.join()dataset = Dataset(data_dir,
batch_size,
val_batch_size
workers,
use_dali,
dali_cpu,
fp16)train_loader = dataset.get_train_loader()
val_loader = dataset.get_val_loader()dataset.reset()dataset.prep_for_val()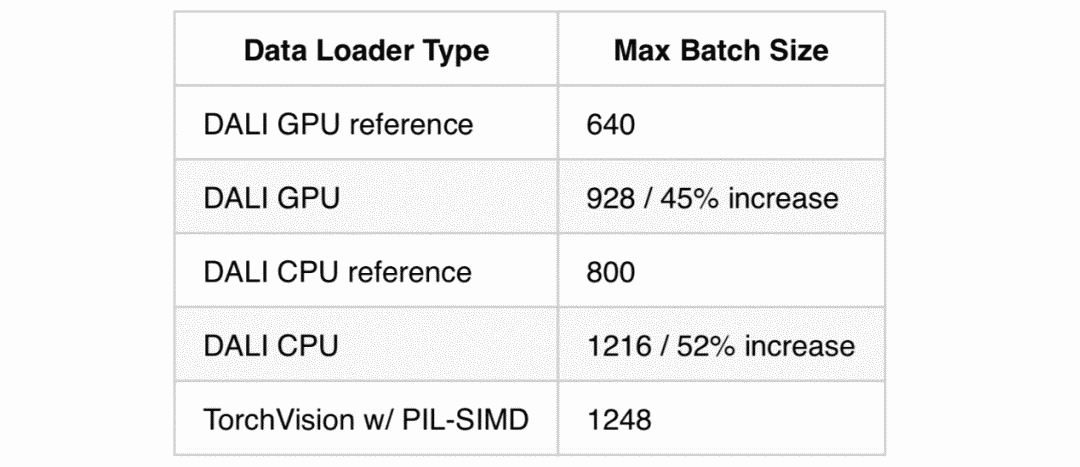
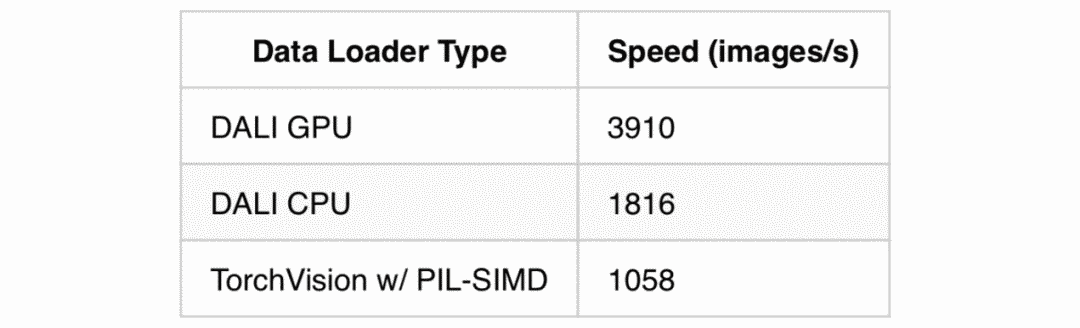
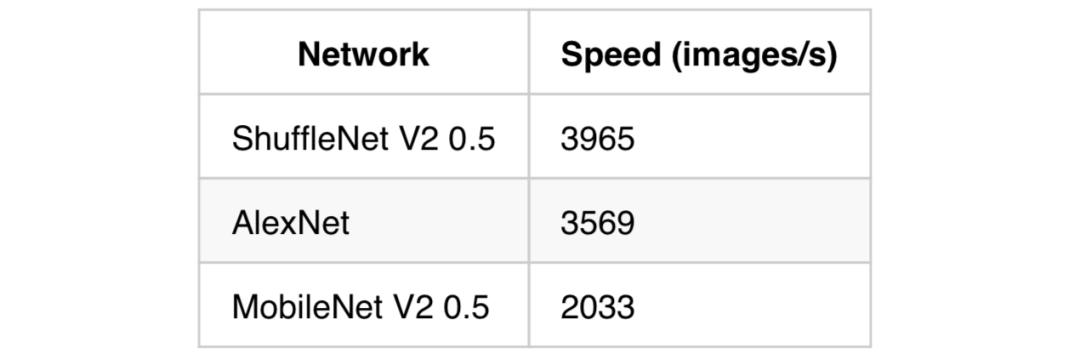
--fp16 --batch-size 512 --workers 10 --arch "shufflenet_v2_x0_5 or resnet18" --prof --use-daliIntern/Full-Time Editor Recruitment
Join us and experience every detail of writing at a professional tech media outlet, growing alongside a group of the best talents in the most promising industry. Located in Beijing, Qinghua East Gate, reply with “Recruitment” on the Big Data Digest homepage to learn more. Please send your resume directly to [email protected]