
We believe that the next major leap in artificial intelligence will come from systems capable of understanding the visual world and its changes. Therefore, we are launching a new long-term research initiative around General World Models.
Runway
(This article is translated and integrated by GigaAI; for reprints, please contact for authorization. Original text: https://research.runwayml.com/introducing-general-world-models)
Source|Runway Research
Runway: Introducing General World Models
General World Models are artificial intelligence systems that construct an internal representation of an environment and use it to predict future events within that environment. So far, research on world models has mainly focused on very constrained and controllable scenarios, either in simulated game worlds or in specific use cases such as world models applied to autonomous driving. The goal of general world models is to represent and simulate more general situations and interactions found in the real world, similar to the various situations encountered in reality.
We can view video generation systems like Gen-2 as very early and limited versions of general world models. To generate realistic short videos, Gen-2 has developed some understanding of physics and motion. However, its capabilities are still very limited and it struggles with issues like complex camera or object movements.
To build general world models, we still have some research challenges to address. Firstly, these models need to generate a “consistent map” of the environment (an internal representation of the physical world) and be able to effectively navigate and interact within these environments. They not only need to capture the dynamic information of the world but also understand the dynamics of its inhabitants (agents), which involves constructing models that reflect realistic human behaviors.
The Origin and Development of World Models
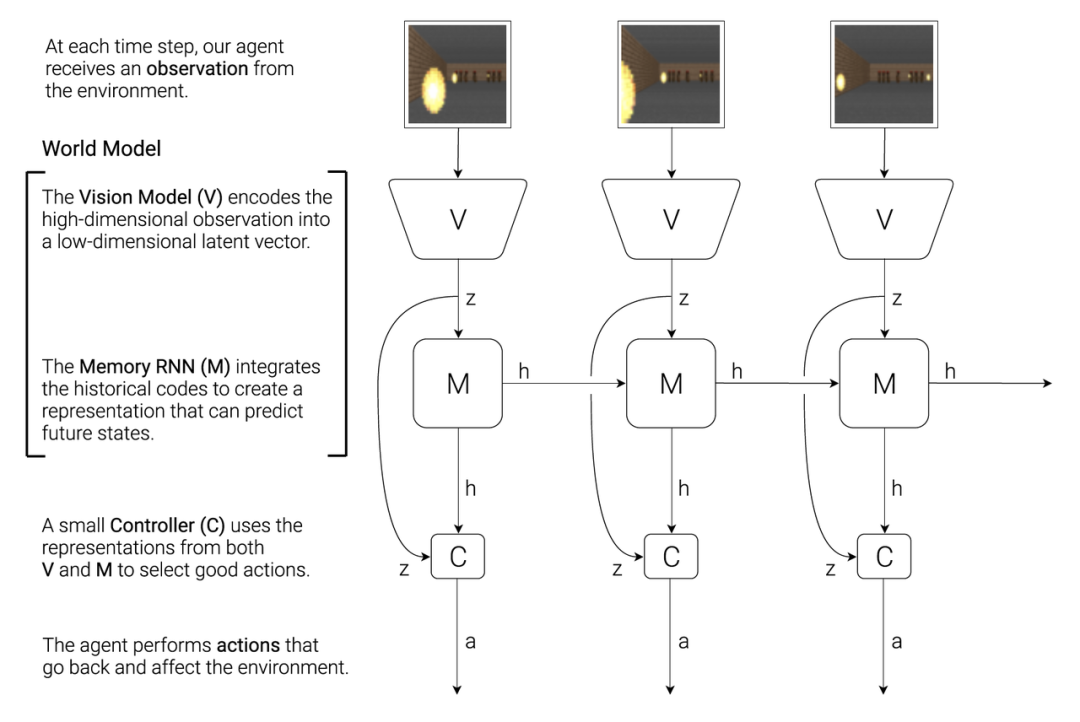
Early explorations of world models focused on game scenarios. For example, World Models[1] proposed a generative neural network model that learns compressed representations of space and time in gaming environments. This method takes visual observations as input, which are then encoded into high-dimensional vectors by the Vision Model in the world model, followed by encoding in the Memory module, which combines historical information to predict future states. Finally, a Controller module predicts future game actions. This work achieved high scores in the CarRacing (game) task and is even considered to have perfectly solved the CarRacing task.
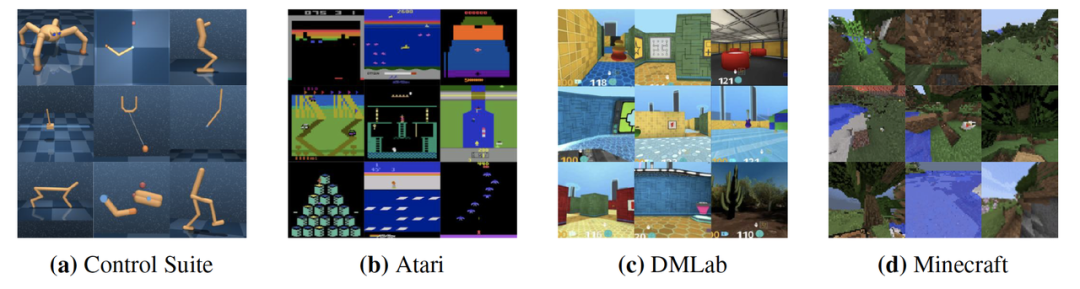
Next, the Dreamer series of papers[2,3,4] further validated the effectiveness of world models across various gaming scenarios. The latest DreamerV3[4] achieved high scores in different gaming scenarios using the same parameters, including 26 games in Atari, 23 scenarios in BSuite, 20 control tasks in Control Suite, and 3D scenes in DMLab. Most notably, DreamerV3 was able to spontaneously acquire gems in the Minecraft game without human intervention or guidance, which has been considered one of the most challenging tasks in the game.
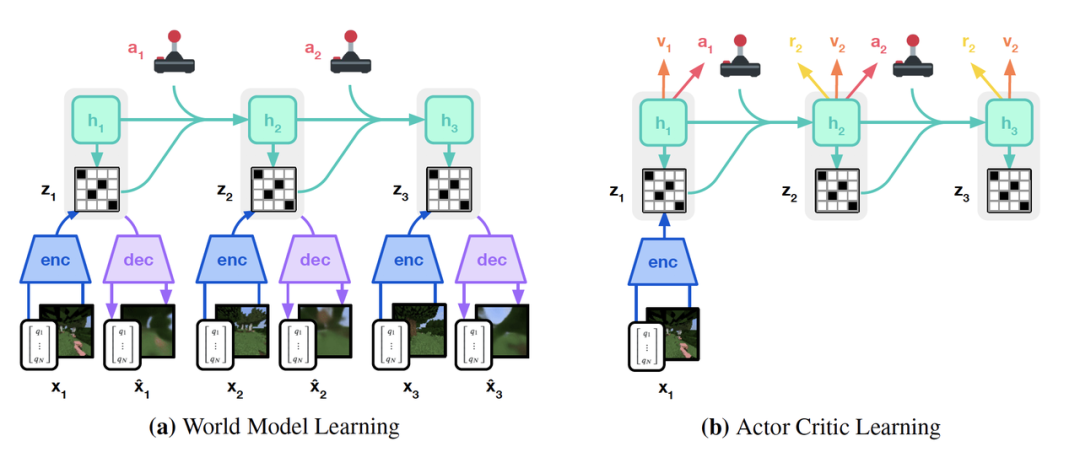
The method of DreamerV3 is similar to that of World Models[1]. Its training process is as follows: the world model receives visual input and encodes it into latent space, where latent space features interact with the current action and combine with historical latent space features to continuously predict the next moment’s latent space features. The predicted results can be used to predict the next action and rewards. A critic network can then be used for reward assessment and to select the most suitable action as output.
Moreover, the authors of the Dreamer series extended world models to real-world robotic scenarios and proposed DayDreamer[7]. DayDreamer uses a world model structure very similar to that of the Dreamer series and validated the algorithm’s effectiveness on four types of robots shown in the figure below. Experiments demonstrated that a robotic dog could learn to stand within one hour and learn to get back up after falling within the next ten minutes.

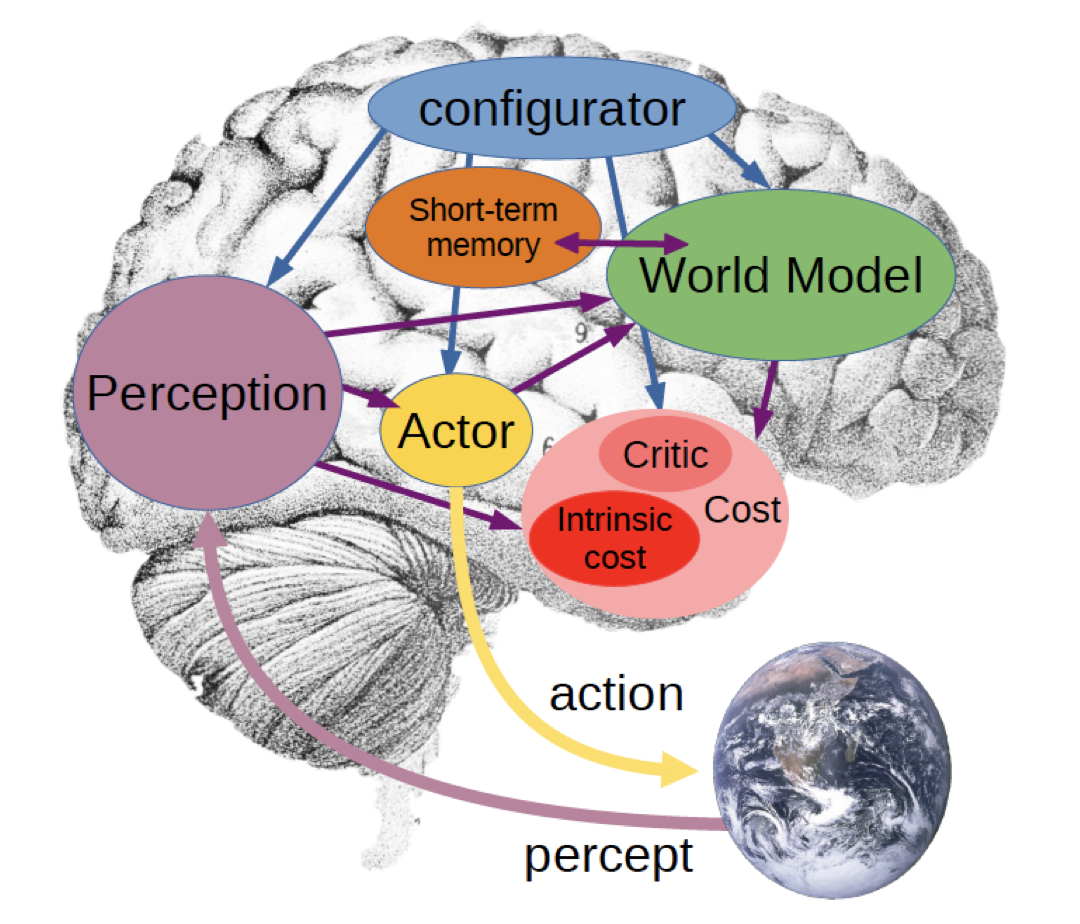
In addition, LeCun also summarized his views on world models in “A Path Towards Autonomous Machine Intelligence[5]”. As shown in the figure below, LeCun believes that intelligent systems should consist of six differentiable parts. The Configuration module is used to configure the intelligent system and can accept information from other modules as input. The Prediction module is used to predict the current state. The World Model module predicts future states based on historical information from the action module. The Cost module evaluates the system’s energy, consisting of non-trainable internal energy assessments (e.g., pain, stress, hunger) and trainable future energy predictions. The Short-term Memory module tracks current and predicted states, as well as assessed system energy. The Actor module takes information from the Short-term Memory module and the Perception module as input and outputs reasonable actions to minimize predicted future costs.
World Models for Autonomous Driving
Due to its structured nature and importance, autonomous driving is the first field where world models have been applied in real scenarios. In September 2023, researchers from GigaAI and Tsinghua University proposed DriveDreamer (link: https://drivedreamer.github.io/), which is the first real-world-driven world model framework for autonomous driving. DriveDreamer can generate videos that conform to structured traffic information; it can change the weather, time, etc., of the generated video according to text descriptions; and it can generate different future driving scene videos based on input driving actions. Finally, DriveDreamer also demonstrates the potential to predict future driving actions based on historical driving actions and image inputs.
After the technical report of DriveDreamer was made public, it received widespread attention from both industry and academia. Subsequently, companies such as Wayve, Huawei, Baidu, Megvii, and the Institute of Automation, Chinese Academy of Sciences released related work and compared their results with those of DriveDreamer.
Wayve’s GAIA-1[8] (Generative AI for Autonomy) model is a generative model that uses video, text, and action inputs to generate realistic driving scenes while providing fine-grained control over its own vehicle behavior and scene features. GAIA-1 can generate videos by executing future deployments starting from video prompts. These future deployments can further condition specific actions (e.g., turning left) that influence the vehicle’s behavior or text that drives changes in certain aspects of the scene (changing the color of traffic lights). For speed and turning curvature, the model can be adjusted by passing sequences of future speed and/or curvature values. The model can also generate realistic videos from text prompts or simply sample from its previous distribution (completely unconditional generation).
DrivingDiffusion[9] is a recent method proposed by Baidu for generating autonomous driving scenes. In training, DrivingDiffusion separately trains multi-view models and temporal models. In the inference phase, the two models are connected in a cascading manner. First, the multi-view model generates the initial multi-view frames of the video. Then, this frame is set as the key frame for the temporal model. Finally, the temporal model generates video frames for each view, forming the final multi-view video.
MagicDrive[10] is a work proposed by Huawei’s Noah’s Ark Lab, which can set conditions at three levels—scene, background, and foreground—by inputting different control conditions. For example, it can change scene lighting and weather, flip backgrounds based on camera angles, and edit vehicles in the foreground.
Megvii’s ADrive-I[11] processes video-text inputs using a multimodal large language model and iteratively predicts the next frame image and future control signals to achieve autonomous driving in its created world.
The Institute of Automation, Chinese Academy of Sciences, proposed Drive-WM[12], which presents a driving world model compatible with end-to-end driving. Drive-WM can enter multiple futures based on different driving operations and determine the best trajectory based on image-based rewards.
Conclusion
From large language models and video generation models to general world models, a new paradigm of general intelligence represented by GPT is reconstructing everything, with the digital world and the physical world welcoming rapid transformation and infinite possibilities!
Appendix:
[1] Ha D, Schmidhuber J. World models[J]. arXiv preprint arXiv:1803.10122, 2018.
[2] Hafner D, Lillicrap T, Ba J, et al. Dream to control: Learning behaviors by latent imagination[J]. arXiv preprint arXiv:1912.01603, 2019.
[3] Hafner D, Lillicrap T, Norouzi M, et al. Mastering atari with discrete world models[J]. arXiv preprint arXiv:2010.02193, 2020.
[4] Hafner D, Pasukonis J, Ba J, et al. Mastering diverse domains through world models[J]. arXiv preprint arXiv:2301.04104, 2023.
[5] LeCun Y. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27[J]. Open Review, 2022, 62(1).
[6] Wang X, Zhu Z, Huang G, et al. Drivedreamer: Towards real-world-driven world models for autonomous driving[J]. arXiv preprint arXiv:2309.09777, 2023.
[7] Wu P, Escontrela A, Hafner D, et al. Daydreamer: World models for physical robot learning[C]//Conference on Robot Learning. PMLR, 2023: 2226-2240.
[8] Hu A, Russell L, Yeo H, et al. Gaia-1: A generative world model for autonomous driving[J]. arXiv preprint arXiv:2309.17080, 2023.
[9] Li X, Zhang Y, Ye X. DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model[J]. arXiv preprint arXiv:2310.07771, 2023.
[10] Gao R, Chen K, Xie E, et al. Magicdrive: Street view generation with diverse 3d geometry control[J]. arXiv preprint arXiv:2310.02601, 2023.
[11] Jia F, Mao W, Liu Y, et al. ADriver-I: A General World Model for Autonomous Driving[J]. arXiv preprint arXiv:2311.13549, 2023.
[12] Wang Y, He J, Fan L, et al. Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving[J]. arXiv preprint arXiv:2311.17918, 2023.