DeepSeek-R1 uses reinforcement learning to significantly enhance the model’s inference capabilities. In tasks such as mathematics, coding, and natural language reasoning, its performance rivals that of OpenAI’s official version o1.The small model distilled from DeepSeek-R1 effectively inherits the reasoning patterns learned by the large model.This article primarily tests DeepSeek-R1-Distill-Llama-8B-GGUF using Llama Edge.
Welcome to experiment with the latest model with me:
First, use https://github.com/LlamaEdge/LlamaEdge
Follow the official README.md instructions, first download it, and copy the following command to the command line to try:
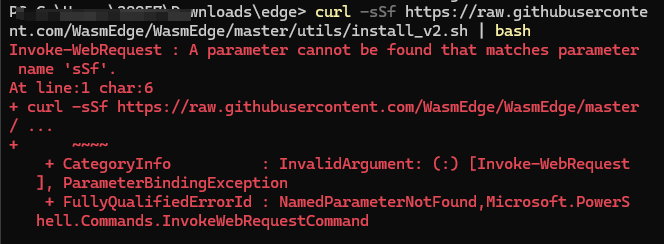
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install_v2.sh | bash
I am using a Windows computer, so I encountered an error. After taking a screenshot of the error, I sent it to Gemini2 for help in understanding it.
This command usually works on Unix-like systems (such as Linux and macOS). However, I am using Windows PowerShell, and due to network issues, we manually downloaded the three files.
First, create a new directory named edge (you can also rename it to your preference).
https://github.com/WasmEdge/WasmEdge/releases/download/0.14.1/WasmEdge-0.14.1-windows-msvc.msi(Download and run the installation)
<span>ggml</span> backend allows WasmEdge applications to execute inference for Llama 2 series large models. I used the cuda version:
https://github.com/WasmEdge/WasmEdge/releases/download/0.14.1/WasmEdge-plugin-wasi_nn-ggml-cuda-0.14.1-windows_x86_64.zip
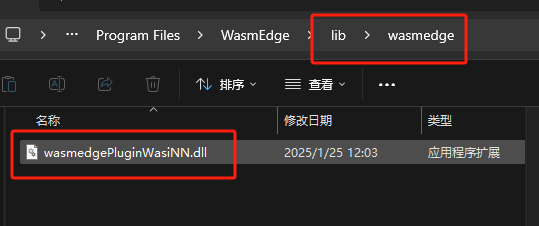
The ggml plugin must be installed; otherwise, it will prompt that nn-preload is invalid. You can download the plugin from the WasmEdge release page, unzip it, and copy it to <span>C:\Program Files\WasmEdge\lib</span> directory. Note that after unzipping, only the files in the lib directory are needed.
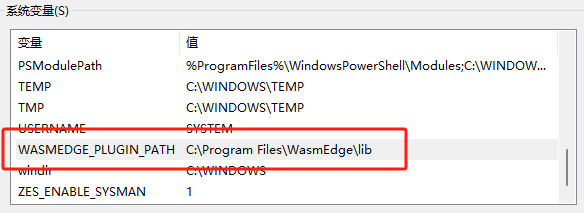
Next, you need to set the system’s environment variables:
<span>WASMEDGE_PLUGIN_PATH</span>
Refer to an issue on GitHub:https://github.com/WasmEdge/WasmEdge/issues/3920
https://huggingface.co/second-state/DeepSeek-R1-Distill-Llama-8B-GGUF/tree/main (Download a model of appropriate size; since this is a test, I chose the smallest 3GB one, which is also placed in the edge directory)
https://github.com/LlamaEdge/LlamaEdge/releases/download/0.16.1/llama-api-server.wasm Download and place it in the edge directory
Now the edge directory structure is as follows:
Use the following command to start the LlamaEdge API server for the model
wasmedge --dir .:. --nn-preload default:GGML:AUTO:DeepSeek-R1-Distill-Llama-8B-Q2_K.gguf llama-api-server.wasm --prompt-template llama-3-chat --ctx-size 8096
If everything goes well, we can send requests through the API to get results.I asked Gemini to write some JS code:
curl -X POST http://localhost:8080/v1/chat/completions \ -H 'accept:application/json' \ -H 'Content-Type: application/json' \ -d '{"messages":[{"role":"system", "content": "You are very good at thinking, reasoning, and summarizing. Please respond in Chinese"}, {"role":"user", "content": "Who is the most famous mythological figure in China, why, and what is the basis for this?"}], "model": "DeepSeek-R1-Distill-Llama-8B"}'
这是一个chat的api。帮我改成stream流式的fetch请求,写一个容易看懂的js方法,把ai对话的结果console出来,用黄色底,黑色字。
另外,还需要提供一个中断请求的方法,为了让我可以随时中断请求。
For detailed code, see : Read the original text.
Paste this JS code into the console panel of Chrome’s developer tools, and you should see the normal response result.Additionally, you can enter the API address into mixcopilot for use.
Welcome to join our AI programming community