


Key Points
CAG (Cache-Augmented Generation) is a new paradigm that preloads all necessary information into the model’s context window, avoiding the real-time information retrieval delays and error risks associated with traditional RAG (Retrieval Augmented Generation).
CAG uses a KV caching mechanism to preload the entire knowledge base as key-value pairs, enhancing response speed, accuracy, and system efficiency while reducing memory and processing power consumption.
Compared to traditional RAG methods, CAG is faster and more accurate, especially when the knowledge base is limited in size.
The limitation of CAG lies in the size restriction of the context window, which may lead to memory issues when the knowledge base is too large.
To address the large knowledge base issue, solutions such as segmented dynamic loading, CAG combined with RAG hybrid methods, pre-selection mechanisms, or larger models and resources can be employed.
Experimental results indicate that CAG outperforms RAG in knowledge-intensive tasks, and as the model’s context capacity increases, the applications of CAG will further expand.
This content is generated by AI.


Don’t do “RAG”, because now there is “CAG”.
In recent years, large language models ( LLM ) have made significant progress in knowledge-based tasks. Traditional retrieval-augmented generation ( RAG ) methods can generate better answers by providing external knowledge sources to LLM models.
However, this method is limited by information retrieval delays and selection errors.
This is where the new paradigm Cache-Augmented Generation (CAG) comes into play. CAG allows models with longer context windows to preload all information, thus completely disabling the information retrieval process.
CAG advantages:
-
Faster response times -
Reduced error risks -
Simplified architecture
CAG Theory
LLM has a specific context window. This window determines the maximum amount of information that can be provided to the model at once.CAG preloads all necessary information into the context window. Therefore, the model does not need to dynamically retrieve individual information sources during queries.
The key event is the key-value ( KV ) cache.
Standard KV Cache in LLM
Typically, in transformer models, each input token is associated with other tokens through self-attention mechanisms.
In this process:
- Key: A vector representing the meaning of the token. It determines how to associate with other tokens.
- Value: A vector of information contained in the token. This is the “actual content” considered during response generation.
For example: “I ate an apple.” The key for the word ‘apple’ indicates how it fits into the context of other words in the sentence. The value holds the meaning of the word “apple”.
This mechanism allows the model to compute how each Token interacts with all other Tokens. This is especially useful when processing long texts or when the same information is frequently needed.
CAG KV Cache is Slightly Different
In CAG, the entire knowledge base is loaded into the model as KV cache. This means that all KV values of documents in the knowledge base are precomputed and stored. When a query comes in, the model responds immediately using this cache instead of retrieving information from external systems. This prevents the same computation from being executed repeatedly for each query. It also creates a consistent context between queries because the information stored in the cache will be loaded into the model’s context window as a whole. This improves the accuracy of answers.
In this way:
-
Reduce time loss -
Reduce the likelihood of carrying false documents -
Ensure speed and efficiency -
Save memory and processing power -
More consistent contextual work -
Provide simplicity in system architecture
A critical point here is hardware. When processing large knowledge bases, GPU memory and RAM are crucial.KV cache requires time and processing power to perform initial encoding of the knowledge base. However, once this is done, recalculation is not needed.
RAG vs. CAG
The RAG method retrieves information sources dynamically independent of the model and uses this information in response generation. However, RAG has drawbacks such as delays, incorrect document selection, and system complexity.
In contrast, the proposed CAG eliminates the need for real-time information retrieval by preloading all relevant information into the model’s extended context window.

RAG vs. CAG
The table below shows the results obtained by researchers testing the differences between RAG and CAG using experimental methods. The experimental results indicate that the proposed CAG method has significant differences compared to traditional RAG systems.
CAG outperforms RAG by providing faster and more accurate answers, especially when the knowledge base size is limited.
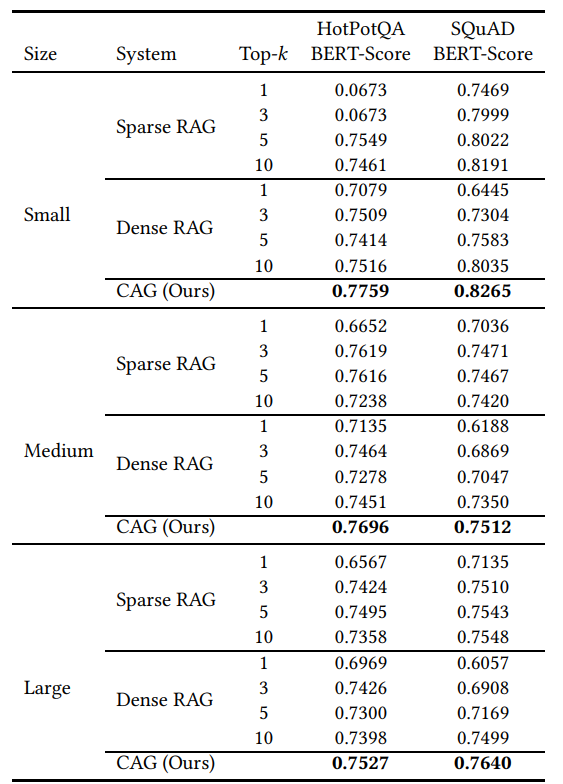
Experimental Results
By the way:
-
If you like this article, I am waiting for your applause 👏 -
To keep up with more content, please follow me👀
Can CAG be used in all cases?
CAG is limited by the model’s context window size. For example, if the model can handle up to 128,000 tokens, the knowledge base needs to be of this size.
For example:
We have 100 documents, each with over 150 pages.
Assuming each page contains an average of 300-500 tokens, a 150-page document has about 45,000-75,000 tokens.
For 100 documents, this means a total of 4.5 million — 7.5 million tokens.
However, a knowledge base of up to 4.5 million — 7.5 million tokens:
-
Then, it will not be possible to cache all information at once, as it exceeds the context limit. -
This may lead to memory issues. The size of the KV cache increases memory consumption, requiring larger GPU/CPU resources.
Solutions:
1- Segmented and dynamic CAG
-
You can divide the knowledge base into smaller, more manageable subsets. For example, let each subset contain 10 documents (~450,000–750,000 tokens). -
Only preload relevant subsets based on the scope of user queries.
2- Hybrid Method (CAG + RAG)
-
You can use CAG to cache the core knowledge base and load commonly used information. -
For less frequently used or edge cases, use RAG for real-time retrieval. -
The hybrid model offers speed and flexibility.
3- Pre-selection or filtering
-
If your queries usually focus on specific parts of documents, you can design a pre-selection mechanism to load only those parts. -
For example, when a user query is received, you can use a fast classifier to determine which document or section is relevant.
4- Larger models and resources
-
If you have the technical means, you can use models that support longer context windows or dedicated infrastructure (e.g., models with multiple GPUs for parallel context processing).
Conclusion
Experiments have shown that CAG outperforms RAG, especially when the knowledge base size is manageable. In the future, as the model’s context window capacity increases, the use cases for CAG may further expand.
In summary, if you are looking for a faster, more accurate, and easier solution for knowledge-intensive tasks, CAG may be your ideal choice.

Related Articles
Building Product Recommendations with Gemini 2.0 API: A Comprehensive Analysis of RAG: LangChain vs. Vertex AI
Using Knowledge Graphs and AI to Retrieve, Filter, and Summarize Medical Journal Articles, Building Graph RAG Applications
Closed AI Systems: The Data Sovereignty Battle, Fortune 500 Companies Have Quietly Laid Out Plans
Open Source Models Surpass OpenAI! DeepSeek R1 Emerges as the New Champion
From Drones to Robots: The Top Ten Innovative Applications of AI Empowering Agriculture
Human Intelligence Exchange
Bringing the Future of Intelligence Closer
Facilitating Communication between Humanity and Future Intelligence
All Network | Human Intelligence Exchange
Join the Group Chat ·

|
|
|
|
|
|


