Originally published by Algorithm Advancement
This article studies how data collection, processing, and analysis contribute to Explainable Artificial Intelligence (XAI) from a data-centric perspective. Existing work is categorized into three types, serving to explain deep models, reveal training data insights, and provide domain knowledge insights. It distills data mining operations and DNN behavior descriptors for different patterns, offering a comprehensive examination of data-centric XAI from the perspective of data mining methods and applications.
1 Introduction
With the advancement of artificial intelligence, deep neural networks have replaced traditional decision-making technologies, but their “black box” nature and extensive parameterization impede the transparency needed for critical applications. Explainable AI has become a crucial field, proposing solutions to improve the interpretability of machine learning, such as LIME. XAI methods follow an orderly process similar to traditional data mining, including data integration, algorithm integration, and human-centered analysis. XAI enhances the interpretability, trust, and even knowledge understanding of AI frameworks, facilitating improved human-AI collaboration. Compared to the aforementioned work, this article explores the gaps in the XAI literature from the perspective of data mining and emphasizes the challenges and importance of explaining deep models.
This article provides a comprehensive review of Explainable Artificial Intelligence (XAI) from the perspective of data mining, categorizing existing work into three types, serving to explain deep models, reveal training data properties, and provide insights into domain knowledge. XAI methods follow a process of data integration, algorithm integration, and human-centered analysis, including four phases: data acquisition and collection, data preprocessing and transformation, data modeling and analysis, and result reporting and visualization. This study provides a structured narrative that categorizes and clarifies current XAI methods through the three purposes of XAI and four different phases of data mining, highlighting the ability of XAI to reveal deeper insights from data, which is of great significance for AI-driven fields such as science and medicine.
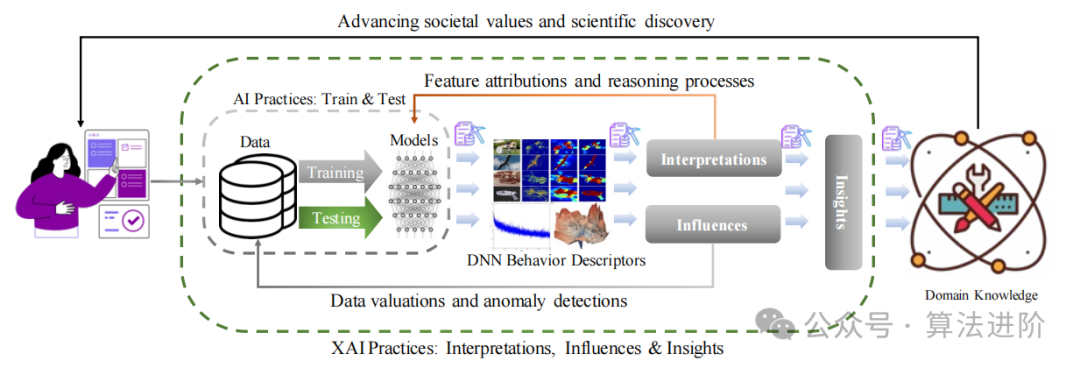
Figure 1 Overview of Explainable AI as a data mining method for explanation, influence, and insight
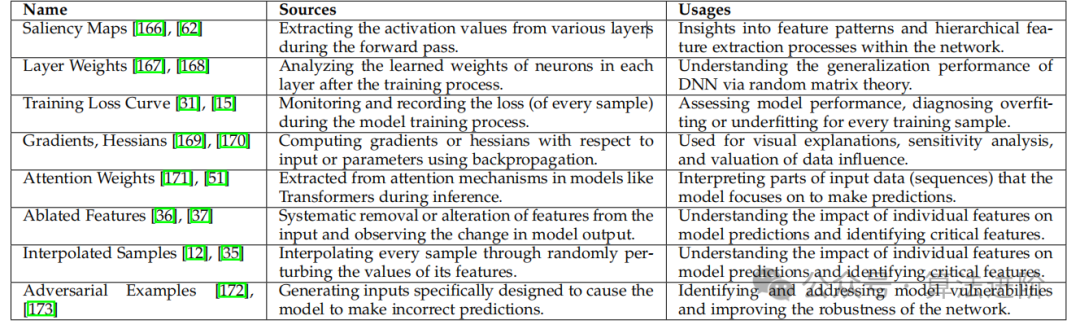
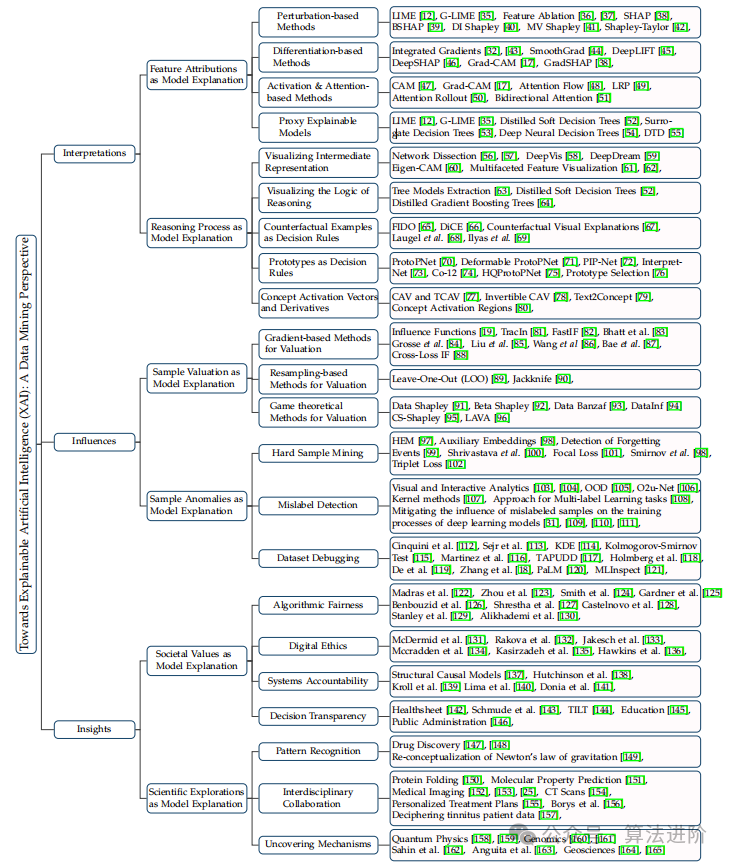
Figure 2 Classification of Explainable Artificial Intelligence (XAI) research from the perspective of data mining: deep model explanation, influence of training samples, and insights into domain knowledge.
2 Explanation: Feature Attributes of Deep Models and Inference Processes
Deep model explanation involves using feature attribution to assess the impact of each input on the model output and examining the inference process to understand the decision paths within the model.
2.1 Feature Attributes as Feature Importance Assessment for Model Explanation
To assess the importance of individual input features for model predictions, several representative methods have been proposed, as follows.
2.1.1 Perturbation-Based Algorithms
The importance of predictions by deep models can be understood through feature attribution explanations, commonly implemented by perturbation-based techniques such as LIME and G-LIME, which provide insights by constructing local surrogate models but come with computational demands and result uncertainty. Feature removal systematically eliminates identified key features but lacks consideration for feature interactions and incurs high computational costs. Shapley values and SHAP evaluate feature importance by calculating the contribution of feature combinations to model predictions, achieving accuracy and efficiency but are computationally intensive in high-dimensional spaces, posing challenges for practical applications.
2.1.2 Partition-Based Algorithms
Partition-based algorithms are an important branch of interpretability for complex models, realized through feature attribution. These techniques compute the gradient of model outputs relative to inputs, aligning each input feature with its corresponding gradient component, indicating its sensitivity to model predictions. The integrated gradient method calculates the importance of input features for model predictions through integration. The smooth gradient method enhances gradient-based interpretability by averaging the gradients of nearby points, reducing noise and improving attribution quality. Deep LIFT increases transparency by comparing the contributions of features against reference points to distinguish prediction differences. DeepSHAP extends this concept by integrating Shapley values, comparing the impact of input features relative to typical baselines. GradSHAP combines gradient signals and Shapley values to attribute feature importance, emphasizing their influence on decisions.
2.1.3 Activation/Attention-Based Methods
XAI enhances the interpretability of DNN models through attention activation mechanisms, providing feature attribution for the decision-making process. In CNNs, activation maps and GradCAM can highlight relevant areas of predictions, showcasing important image regions affecting model results. Transformers based on self-attention mechanisms can capture sequential dependencies, with XAI inferring feature importance by detecting attention distributions. Techniques such as attention propagation and attention flow aggregate attention scores, revealing pathways that significantly influence model outputs. Hierarchical importance propagation traces back relevance scores from outputs to inputs, determining the contributions of features. Bidirectional attention flow, Transformer attribution, and attribution propagation utilize attention weights in Transformers to estimate feature attribution for specific predictions. Figure 3 showcases a series of feature importance techniques, demonstrating their applications across various models. These methods emphasize the variability of feature attribution results, necessitating fidelity tests to validate accuracy. However, visual explanation consistency across different image classifiers can be utilized for pseudo-labeling tasks.

Figure 3 Visualization of commonly used feature attribution methods in visual and NLP models: (a)-(d) fine-tuned ViT-base model for bird classification and its derived models; (e) fine-tuned BERT model on IMDb movie reviews.
2.1.4 Surrogate Explainable Models
Surrogate explainable models use simple surrogates to simulate the decision boundaries of complex deep neural network models, including global surrogates and local surrogates (as shown in Figure 4). Global surrogates apply to training or testing datasets, providing overall behavioral insights into deep neural networks; local surrogates decode the principles behind predictions in the vicinity of specific input instances. Decision trees or ensemble tree methods like random forests are highly regarded for their inherent interpretability, capable of establishing logical rules that link DNN inputs and outputs, often used for global explanations. Linear surrogates such as LIME and G-LIME distill the decisions made by classifiers or regressors into local linear approximations, revealing complex decision patterns. Although decision trees and forests are suitable for reflecting the nonlinear characteristics of deep neural networks as global surrogates, techniques like random forests can distill the behavior of deep neural networks to determine broader feature importance.
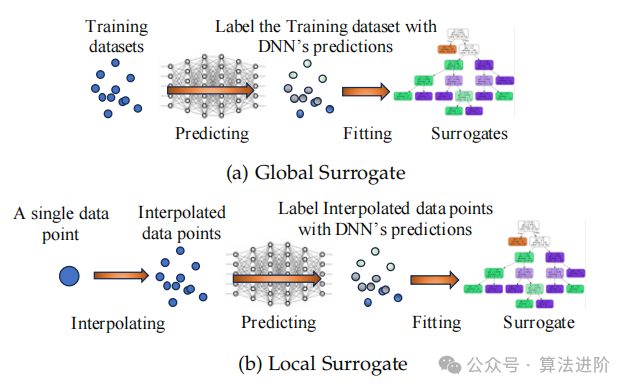
Figure 4 Examples of global and local surrogate models for interpretability, including global and local surrogate models.
2.2 Inference Process as Model Explanation
To explore the decision paths within models, the following methods have been proposed.
2.2.1 Visualizing Intermediate Representations
Visualizing intermediate representations in deep learning models is crucial for understanding their information processing. Intermediate feature visualization transforms complex transformations in hidden layers into interpretable formats, revealing key patterns that the model focuses on during predictions. Network dissection evaluates the interpretability of deep visual representations by associating neurons with semantic concepts, identifying registrations based on intersection and union (IoU) metrics, thereby explaining neuron activations in a human-understandable way. Deconvolution networks and related methods explain layers by mapping features to pixel space. These reconstructions are used to reverse-engineer learned representations. Voita et al. proposed a strategy focusing on stimulating neurons to high activation and examining input modifications, providing insights into learned patterns through neurons. Similarly, DeepVis and DeepDream visualize neuron activations to explain learned content. Eigen-CAM utilizes principal component analysis to support class-specific activation maps in CNNs, while methods proposed by Quach et al. leverage gradient information to improve these visualizations for better class representation. These techniques surpass basic heatmap visualizations by accurately learning specific image features by highlighting activated image segments.
2.2.2 Visualizing Inference Logic
Decision trees and ensemble models (such as random forests and gradient boosting trees) serve as surrogate models that reveal the logic behind deep neural network decisions. These algorithms construct interpretable surrogate models that replicate the complex reasoning of deep neural networks by transforming their predictions into a series of simple, logical decisions. Surrogate models utilize inputs and outputs from deep neural networks, leveraging feature attributes provided by these black-box models to convert neural networks into a set of understandable rules or pathways. By representing the model’s decision logic as a branching structure, where each node encodes rules based on feature values, these tree-based algorithms break down the complex reasoning process of deep neural networks into an understandable format, ultimately making predictions at the leaf nodes. This attribute grants the model apparent intuitiveness and interpretability, allowing for easy tracking and visualization of end-to-end decision processes.
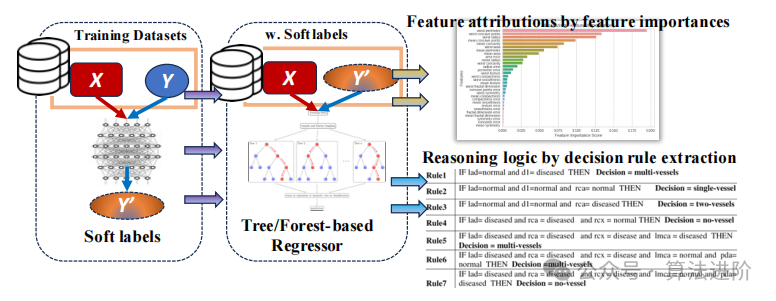
Figure 5 Visualization of feature importance and inference logic using tree/forest-based surrogates
2.2.3 Counterfactual Examples as Decision Rules
Counterfactual examples are an intuitive method for explaining model decisions, illustrating what would happen if certain inputs were changed in the prediction model. These examples transform the decision process into a constrained optimization problem aimed at determining the minimal amount of change in input data required for the model’s prediction, thus providing clear insights into the model’s decision boundary. FIDO emphasizes generating counterfactual examples that comply with fixed feature constraints, while DiCE promotes creating diverse counterfactual examples to facilitate understanding across a range of plausible scenarios. Incorporating causal inference perspectives into counterfactual reasoning further enhances model interpretability, exploring the causal mechanisms of model predictions and identifying which feature changes lead to different outcomes. Related to counterfactual examples are adversarial examples, which also utilize optimization techniques to modify inputs but aim to challenge the robustness of the model, revealing its weaknesses and providing insights into the learning process.
2.2.4 Prototypes as Decision Rules
Mining prototypes from training data is a method to refine and explain deep learning model decisions by identifying examples or representative features. This approach traces back to previous work, but recent methods such as ProtoPNet actively learn prototypes from the last layer of deep models to provide interpretable connections between model decisions and training data. These prototypes provide visual explanations for classification predictions, enhancing the network’s interpretability. Deformable ProtoPNet extends this by capturing prototype parts and considering variations in posture and context, enriching the dual implications of model accuracy and interpretability. Nauta et al. proposed a benchmark for evaluating ProtoPNet-based image classification and interpretability performance. The introduction of supporting prototypes and trivial prototypes further aids in understanding DNN model behavior at decision boundaries. To achieve global interpretability, PIP-Net introduces the aggregation of learned prototypes, transparently showcasing the model’s reasoning process. These prototype-based interpretability methods primarily focus on creating self-explanatory classifiers rather than explaining existing DNN models.
2.2.5 Concept Activation Vectors and Derivative Concepts
Concept Activation Vectors (CAVs) are interpretable dimensions in the activation space of neural networks, representing abstract “concepts” such as objects and colors. CAVs are defined as vectors orthogonal to hyperplanes that differentiate activations with and without the concept. Based on CAVs, the Testing with Concept Activation Vectors (TCAV) provides a quantitative method for assessing the influence of specific concepts on model predictions. TCAV scores indicate the extent to which concepts participate in model outputs, with positive derivatives indicating positive TCAV scores; class-specific scores are calculated as the proportion of instances positively correlated with the concept. Inverse CAVs are used to explain visual models of non-negative CAVs, while Text2Concept extends the CAV framework to NLP, allowing for the extraction of interpretable vectors from text. Concept Activation Regions (CARs) utilize a set of CAVs to define decision boundaries in DNN models.
2.3 Summary and Discussion
In summary, XAI techniques explain model decisions through feature attribution or inference process. We map the processes of these representative methods to the data mining domain and discuss as follows.
2.3.1 Data Acquisition and Collection
Various types of data are crucial in the field of deep neural network explanation, including tabular, text, and image data. Interpretability techniques such as LIME, GLIME, feature removal, and SHAP adeptly handle these data, clarifying the role of each feature in predictive outcomes. In the context of image data, the focus shifts to revealing the importance of individual or clustered pixels in model predictions. G-LIME employs superpixel clustering strategies to construct features for attribution.
2.3.2 Data Preparation and Transformation
Data transformation methods are essential for interpreting deep neural networks, including LIME and G-LIME generating data perturbations, feature removal setting input features to predetermined baselines, SHAP traversing all feature subsets, integrated gradients, and noise instances in SmoothGrad, as well as gradient-based attribution methods, layer-wise relevance propagation, and network dissection to study representations across layers. The derivatives of CAM also facilitate feature extraction from networks.
2.3.3 Data Modeling and Analysis
Data modeling and subsequent analysis methods differ in interpretability methods. LIME and G-LIME primarily fit interpretable models to perturbed data, while decision trees and related nonlinear rule-based models provide comprehensive global explanations. Feature removal assesses the impact of omitted features, while SHAP quantifies the marginal contribution of each feature using game-theoretic methods. Additionally, other methods such as integrated gradients compute the path integrals of feature influences for clarification, SmoothGrad averages gradients of multiple noisy inputs for stable explanations, and deep Taylor decomposition traces neuron outputs back to input signals to determine feature relevance.
2.3.4 Result Reporting and Visualization
Visualization strategies for interpreting image data play a key role in reporting. Techniques such as LIME, GLIME, SHAP, DTD, integrated gradients, and SmoothGrad highlight important regions of images through heatmaps. G-LIME, SHAP, and feature removal project feature attributions as ranked lists, emphasizing order rather than exact values. Feature removal visualizes “deprived images,” indicating critical pixel/superpixel configurations. Visualization of intermediate representations may involve significance or attention maps derived from activation maps. Counterfactuals use comparative data rows, while concept activation vectors clarify through variance maps and correlation maps. Selected visualization methods depend on model complexity and interpretability approaches, always pursuing clarity in explanations.
3 Influencing Factors: Data Valuation and Anomaly Detection of Training Samples
Explaining deep models by measuring the influence of training samples on model decisions is crucial for understanding and validating these models’ outputs. This process typically involves several techniques that map the correlation between individual training samples and the decisions made by the model. In this paper, we categorize existing work into the following three types.
3.1 Sample Valuation as Model Explanation
Sample contribution-based methods form a unique category of interpretability techniques aimed at explaining deep models by determining the influence of individual training examples on model decisions. The fundamental idea behind these methods is to measure how much the prediction of a test instance would change if a specific training instance were excluded from the training dataset. While most of these methods stem from robust statistics, we summarize some of them as follows.
3.1.1 Gradient-Based Valuation Methods
Influence functions have become a crucial analytical tool in XAI for measuring the sensitivity of model predictions to marginal changes in training data and understanding the differing contributions of data points to final model outcomes. Although valuable for identifying outliers and influential instances, the computational cost of calculating influence functions remains high for large datasets. Some studies have proposed interpretability and debugging methods for large NLP datasets to expand the estimation scope of influence functions. Additionally, TracIn introduces a complementary paradigm that utilizes backpropagation to determine the impact of training samples on predictions, which is crucial for diagnosing biases and enhancing fairness in visual and language models. However, its effectiveness depends on data integrity, and the fundamental assumption of loss function smoothness may not be suitable for complex neural architectures. A robust computational investment related to gradients and Hessian calculations needs to be optimized to reasonably scale these interpretative tools to high-dimensional DNN models.
3.1.2 Resampling-Based Valuation Methods
Resampling strategies such as Leave-One-Out (LOO) and Jackknife resampling are crucial for assessing the contribution of individual data points to predictive models. The LOO method evaluates the impact of each data point by excluding it, capable of detecting outliers and significantly influential samples, but computationally inefficient when handling large datasets. Jackknife resampling quantifies the imposed influence of each observation when omitted, extending this evaluation framework, performing better than traditional perturbation functions in handling the complexities of DNN responses. Compared to LOO, Jackknife estimates provide more manageable approximations of sampling distributions while avoiding the need for model retraining with each resampling, but assume linearity, which may fail when faced with nonlinear data structures or outliers. Figure 6 shows a simple comparison of influence functions and LOO resampling. Both strategies aim to evaluate the influence of samples on decisions, with resampling-based methods requiring sample exclusion and model retraining, while influence function-based strategies can directly measure influence through gradient or Hessian calculations.
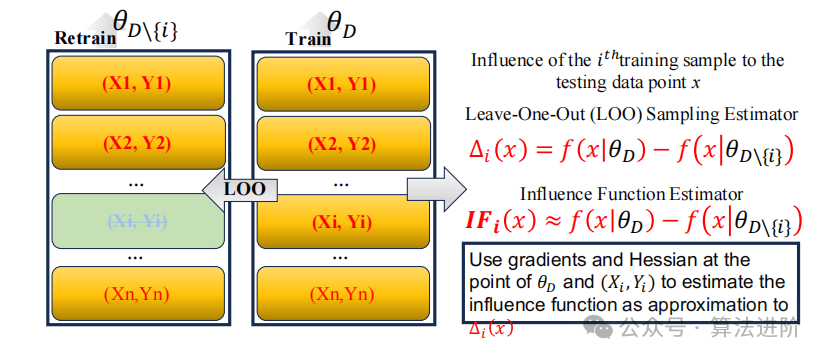
Figure 6 Evaluating the impact of training samples: Leave-One-Out (LOO) resampling vs. influence function
3.1.3 Game-Theoretic Methods in Valuation
Shapley values provide a robust framework for estimating the contribution of individual training samples to model predictions, extending existing applications to feature attribute normalization. Data Shapley values directly link training samples to model outputs, providing a measure of the influence of data points on predictive outcomes. Beta Shapley values further improve this process by proposing a noise-reducing data valuation method that accelerates computations while maintaining key statistical properties. The use of Banzhaf values has recently gained traction in the field of data valuation, employing the Banzhaf power index to assess the influence of samples on model predictions. DataInf has emerged as a non-gradient, non-resampling game-theoretic method particularly suited for understanding sample influence in fine-tuned large language models. Non-model methods like LAVA and CS-Shapley show potential to serve as more practical influence estimators, relying on Wasserstein distances or Shapley values of classes, respectively.
3.2 Sample Anomalies as Model Explanation
This content primarily discusses research work on mining anomalous samples from training datasets, aimed at addressing predictions of the trained model. These works are categorized based on application purposes.
3.2.1 Hard Sample Mining
Hard Sample Mining (HEM) is an algorithmic strategy aimed at identifying the most challenging subset of training samples to enhance the learning process of machine learning models. Based on statistical learning concepts, HEM adjusts sample weights using mechanisms like AdaBoost to improve generalization capabilities. In Support Vector Machines (SVM), hard samples are support vectors close to the defining hyperplane, marked as key training instances. In computer vision research, HEM has addressed data bottlenecks and class imbalance issues, employing algorithms like Monte Carlo Tree Search (MCTS) for difficult sample identification and online HEM to enhance object detection. Innovations like auxiliary embedding have improved the effectiveness of HEM in image dataset applications, while detecting forgetting events can help identify hard samples. HEM has transcended the field of computer vision, playing roles in active learning, graph learning, and information retrieval, meeting the challenges posed by complex data elements in their respective fields. These recent attempts demonstrate the expanding scope and utility of hard sample mining in enriching learning paradigms in data science.

Figure 7 Samples that experienced forgetting events and those that have never been forgotten during training on CIFAR-10
3.2.2 Label Error Detection
Detecting, eliminating, or correcting mislabeled samples in training datasets is crucial in machine learning, with methods broadly categorized into three types: visual and interactive analysis, model-based analysis, and studies focusing on the impact of mislabeled samples on the training process of deep learning models. Visual and interactive analysis identifies mislabeled data points by detecting anomalies in low-dimensional representations, such as OOD sample detection techniques, using visual methods to identify samples deviating from expected patterns. Interactive visualization is effective in areas like health data, enhancing label accuracy. Model-based analysis combines algorithmic detection with human supervision, such as kernel methods detecting distribution anomalies to locate mislabeled points but faces scalability issues. Methods like O2u-Net focus on label error detection in large image datasets, while multi-label learning task methods concentrate on identifying noisy labels to optimize learning. Recent studies have focused on the impact of mislabeled samples on the training process of deep learning models, understanding these effects is crucial for developing algorithms that can mitigate such samples’ impacts on model performance.
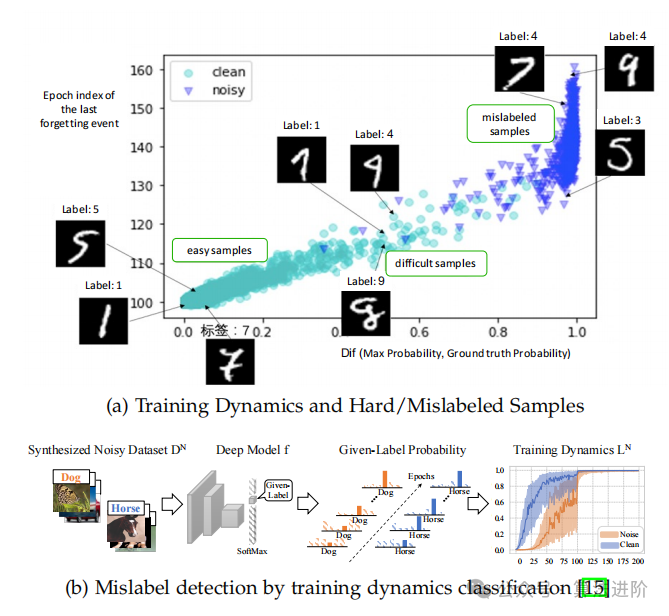
Figure 8 Ensuring data integrity in machine learning pipelines for training dynamic and mislabeled sample detection by providing unique insights and tools
3.2.3 Dataset Debugging
The integrity of training datasets is vital for the effectiveness of machine learning models, especially for real-world applications. The focus of dataset debugging strategies is to address issues such as missing values, outliers, and noisy data to enhance the performance of deep neural networks. In addressing missing values, Cinquini et al. proposed a post-hoc interpretable method, while Sejr et al. viewed outlier detection as an unsupervised classification problem, providing interpretable insights. Traditional kernel-based methods and statistical tests may fail when handling unstructured data types. Recently, the development of XAI has created new methods to overcome these shortcomings, such as the method proposed by Martinez et al. for anomaly sample detection using post-hoc explanations and TAPUDD, while Holmberg et al. utilized visual concepts for this purpose, and De et al. applied weighted mutual information for OOD identification. Zhang et al. proposed a method that first identifies correctly labeled items and then minimally adjusts the remaining labels to produce accurate predictions. MLInspect developed by Grafberger provides a means to diagnose and correct technical biases in machine learning pipelines. Additionally, PalM was introduced by Krishnan et al. through exploring interactive debugging tools.
3.3 Summary and Discussion
In conclusion, XAI techniques can quantify the influence of training samples on model decisions, whether viewed from the perspective of data valuation or anomaly detection. We map representative methods belonging to these categories in the data mining process and discuss.
3.3.1 Data Acquisition and Collection
XAI methods provide a comprehensive framework suitable for various data types, such as tabular, text, and image, in the fields of data valuation and anomaly detection. Sample valuation interpreters like influence functions, TracIn, Leave-One-Out (LOO), Jackknife, and Shapley valuation exhibit great applicability in image and text scenarios. In contrast, sample anomaly interpreters are often optimized for specific data patterns, with methods suitable for various data formats, such as those by Jia et al., while PaLM focuses on tabular datasets.
3.3.2 Data Preparation and Transformation
Various anomaly interpreters apply preprocessing techniques to prepare data, such as generating image-assisted embeddings by Smirnov et al., O2u-Net capturing training loss with oscillation training methods, Jia et al. shuffling labels and tracking iterative training loss, TAPUDD extracting heatmaps from deep neural network models, and PaLM using decision tree nodes to partition datasets. These preparatory steps enrich XAI applications, enhancing understanding of the influence of training data on model outputs.
3.3.3 Data Modeling and Analysis
XAI is used to reveal the impact of training data on predictive models in data modeling and analysis. Sample valuation interpreters such as influence functions and TracIn use gradients for evaluation, while LOO measures sample influence by changes in model predictions after exclusion. In anomaly detection, Smirnov et al. pair challenging samples for training, O2u-Net ranks samples based on loss curves, highlighting potential mislabeled instances, and Jia et al. use time series classifiers to discover mislabeled instances. TAPUDD clusters outliers through heatmaps, while PaLM provides global explanations through decision tree partitions, and these methods contribute to better understanding of the impact of training data on model decisions.
3.3.4 Result Reporting and Visualization
The result reporting and visualization methods of XAI tools vary widely. Influence functions calculate the impact of individual training samples, facilitating targeted insights, while TracIn quantifies positive and negative training influences. LOO techniques display the impact through prediction shifts, with Jackknife and Shapley valuations distributing numerical values representing influence magnitudes. Other tools enhance visual clarity, such as PaLM showcasing iterative model responses. These methods ensure visual scrutiny of key training data elements to understand their impact on the model, aiding systematic exploration of influence landscapes.
4 Insights: Extracting Patterns and Knowledge Discovery from Data
XAI algorithms facilitate the extraction of highly readable insights, partly through identifying and interpreting patterns, correlations, and anomalies in complex multidimensional or multimodal data. Two sets of efforts have been completed, one involving social values and the other focusing on advancing scientific discoveries.
4.1 Social Values as Model Explanation
Here, XAI aims to enhance the interpretability and trustworthiness of algorithms and models in decision-making, thereby promoting social choice and ultimately improving social fairness, ethics, accountability, and transparency.
4.1.1 Algorithmic Fairness
XAI is crucial for improving biases in machine learning models, as it can demonstrate the fairness of automated decisions through Counterfactual Fairness methods and provide transparency to clarify the logic of deep neural networks, laying the groundwork for fair AI applications. In micro-loans and education systems, considering diverse stakeholder perspectives is crucial. Benbouzid et al. and Shrestha et al. emphasize the importance of optimizing AI to embrace scientific fairness and effective collective decision-making. Castelnovo et al. explore the practical applications of XAI in fairness, proposing new strategies that integrate human behavioral insights for continuous model improvement. Stanley et al. highlight the role of XAI in revealing subgroup biases in medical imaging. Alikhademi et al. propose a tripartite framework for assessing the capabilities of XAI tools in bias detection and mitigation, revealing that the capabilities of XAI in bias detection often fall short.
4.1.2 Digital Ethics
Research at the intersection of ethics and XAI is gradually emerging, focusing on the impact of data-driven decisions on social ethical practices. The application of environmental justice perspectives in algorithmic auditing is advocated to achieve equitable solutions. Divergence between AI professionals and the public on ethical issues reflects differing perceptions of the priority of responsible AI values, and understandable XAI systems help build trust and adhere to social norms. The JustEFAB principle promotes clinically transparent machine learning models, emphasizing bias checks and corrections within a lifecycle perspective. Research on counterfactual reasoning in XAI warns of the risks of misusing social classifications and emphasizes the need for cautious development under fairness and transparency principles. AI benchmarking is viewed as a key part of ethical AI development, driving progress by identifying and mitigating inherent biases. At the same time, the ethical dilemmas of AI data augmentation underscore the significant role of XAI in addressing ethical complexities.
4.1.3 System Accountability
Accountability in artificial intelligence is crucial for ensuring fair, lawful, and socially aligned decisions. Kacianka et al. reveal the layers of accountability within the autonomous vehicle domain through structural causal models (SCMs), enhancing the transparency and reliability of decisions. Hutchinson et al. propose an accountability framework applicable to the machine learning data lifecycle, ensuring traceable and accountable decisions. Kroll et al. explore the application of traceability in XAI, establishing a set of requirements for responsible AI systems. Lima et al. discuss accountability in autonomous XAI applications, emphasizing the importance of establishing a robust regulatory framework. Donia et al. explore normative frameworks in XAI, emphasizing the importance of ensuring that AI technologies meet ethical, social, and legal standards.
4.1.4 Decision Transparency
XAI has made progress across various fields, meeting the demands for transparency and trust in AI systems. In healthcare, Healthsheet promotes transparency by providing detailed dataset documentation, revealing biases and facilitating transparency in data sources. In education, XAI plays a key role in clarifying the AI-driven admissions process in New York City schools, promoting parental involvement and contributing to accountability and fairness. Chile’s implementation of algorithmic transparency standards in public administration reflects a commitment to making automated government decisions transparent and accountable, fostering public trust. The project systematically evaluates the use of automated decision systems by the government, emphasizing that these systems should be understandable and accessible to the public according to transparency frameworks.
4.2 Scientific Exploration as Model Explanation
XAI provides practical technologies and tools for scientific research, with immense potential. These works are categorized into three groups based on different approaches to leveraging XAI technologies.
4.2.1 Pattern Recognition
Scientific data is crucial in research, data mining reveals new patterns, and deep learning excels at detecting complex patterns but struggles to extract information. XAI clarifies the AI decision-making process through interventions, enhancing the utility of deep learning in fields like drug discovery. Incorporating XAI techniques such as Concept Whitening (CW) into graph neural network models can improve credibility, enhancing interpretability and performance in drug discovery. The field of computational chemistry benefits from XAI’s role in mitigating the ambiguity of deep learning models, facilitating understanding of molecular structure-property relationships. Counterfactual explanations and attribution methods elucidate the complex associations learned by deep learning models, enhancing predictive confidence and guiding molecular adjustments to engineer desired properties, boosting deep learning’s capability to identify and predict chemical phenomena. Machine learning methods combined with XAI reawaken the role of classical scientific principles, such as the reconceptualization of Newton’s law of universal gravitation through analyzing vast astronomical data using graph neural networks, improving the accuracy of predicting planetary motion trajectories and enhancing the confidence of the insights gained.
4.2.2 Interdisciplinary Collaboration
Interdisciplinary collaboration is crucial in translational research, fostering cross-disciplinary innovation and accelerating the transformation of laboratory discoveries into practical applications. XAI paves the way for collaboration across multiple fields, leading to interdisciplinary breakthroughs. Advanced AI technologies facilitate these interdisciplinary explorations, developing integrated models that drive scientific progress. In biophysics and computational science, XAI plays a prominent role in the AlphaFold protein folding project, improving the accuracy of molecular property predictions and revealing complex molecular patterns. In medical imaging, XAI serves as a communication channel between deep learning algorithms and clinicians, revealing disease indicators in MRI scans, which is crucial for accurate diagnosis. XAI is essential for collaborative translational medicine, combining deep learning with clinical practice to design lung cancer detection models from CT scans, revealing known and unknown diagnostic patterns. AI systems like IBM Watson for Oncology demonstrate how AI can assist clinicians in developing personalized treatment plans, providing transparency for medical professionals and patients. XAI plays a significant role in translating scientific advances into practical clinical practice, integrating data-driven insights with actionable medical decisions.
4.2.3 Revealing Mechanisms
XAI plays a key role in interdisciplinary scientific advancement, particularly in unraveling the complexities of natural systems and enhancing the depth and accuracy of scientific investigations. Machine learning algorithms decouple the dynamics of complex systems in quantum physics, aiding in the understanding of quantum entanglement and quantum state dynamics, with practical applications. In genomics, AI elucidates the complexities of gene regulation, deepening the understanding of gene interactions and regulatory mechanisms. XAI plays a crucial role in revealing hidden relationships in photovoltaic materials, optimizing predictions of organic solar cell efficiency, and identifying gene expression patterns associated with obesity. In the field of Earth sciences, XAI aids in approximating mineral water content, elucidating the various elemental roles in hydrogen diffusion. XAI makes AI models comprehensible, helping scientists verify or refute hypotheses, birthing new insights. XAI is an ideal pathway for interdisciplinary research, vital for the future of scientific exploration.
4.3 Summary and Discussion
From the perspective of data mining stages, XAI used to drive social values and scientific discoveries integrates the following four steps.
4.3.1 Data Collection and Acquisition
Research utilizes complex multidimensional and multimodal datasets that support XAI analysis, involving data types relevant to social applications, including demographic, financial, medical imaging, behavioral, and educational datasets, aiding in addressing issues of algorithmic fairness, digital ethics, and system accountability. In the field of scientific discovery, data types range from genomic sequences to quantum system properties to molecular structures in drug discovery and clinical imaging data in healthcare applications.
4.3.2 Data Preparation and Transformation
Data preprocessing is necessary under XAI support, including standardization in social contexts to mitigate biases, ensuring fairness and transparency, and transforming inconsistent or missing financial data to adapt to dynamic environments. In scientific exploration, research can use normalization, feature extraction, and selection techniques to refine domain-relevant datasets, such as chemical properties in drug discovery or physiological and environmental factors in medical diagnostics.
4.3.3 Data Modeling and Analysis
XAI models and analyzes data using techniques aligned with target tasks, such as Counterfactual Fairness methods and transparency techniques for deep neural networks to achieve social fairness and system accountability. In scientific discovery, XAI predicts drug efficacy through classification recognition and graph neural networks while revealing quantum entanglement through restricted Boltzmann machines. These methods model and analyze data to extract interpretable patterns, fostering trust and deepening understanding.
4.3.4 Result Reporting and Visualization
The reporting and visualization of XAI results vary by application field. In social applications, subgroup analysis visualizes fairness in medical datasets, while comprehensive documentation like “Healthsheet” enhances transparency. In scientific discovery, intuitive visualization tools like XSMILES convey predictions of molecular properties, or develop non-visual methods like medical imaging. XAI enhances the clarity and interpretability of model decision processes, from aiding medical professionals in diagnosis to assisting policymakers in evaluating algorithms in public administration. Overall, deploying XAI in social and scientific domains emphasizes interactive and accessible visualizations optimized for respective audiences to enhance understanding and application of AI insights.
5 Limitations and Future Directions
In summary, Explainable Artificial Intelligence (XAI) methods face the following key technical limitations:
-
Data Quality:The effectiveness of explanations from XAI methods is influenced by data quality. Therefore, robust data preparation and transformation are crucial to improve data quality and ensure more reliable results. -
Algorithm Complexity:As the complexity of AI models increases, explaining their decisions becomes a significant challenge. Therefore, advanced XAI techniques need to be developed to unravel complex models, especially on large datasets, while maintaining interpretability. -
Method Evaluation and Selection:Current evaluation frameworks may not adequately capture the broad range of XAI methods, leading to misunderstandings of their utility. Therefore, it is necessary to develop extensive and comprehensive evaluation frameworks to provide high-quality choices of XAI methods. -
XAI on Large Language Models (LLM):The scale and complexity of large language models (like GPT-4) may render current XAI methods insufficient in addressing biases or errors within them. Therefore, research into scalable XAI strategies is needed to provide clear explanations for the decisions of large models.