
Reinforcement Learning, abbreviated as RL, is a term you will frequently hear in today’s AI research. RL techniques have been applied in many projects, such as AlphaGo.
A Brief
The algorithms we learned earlier are actually based on supervised learning. In any case, we provided them with label tags. Whether it’s CNN, RNN, GAN, or self-supervised learning, they all rely on labels.
However, the field studied by RL is different because sometimes machines do not know which step is the best, or we do not know what the optimal output should be. For example, on a 13×13 chessboard, after an opponent has made a move, can you confidently determine the best next move? How should this label be provided? Perhaps humans themselves do not know. You might say you can refer to some chess manuals to observe and determine the best move. But can you be sure that this move is indeed the best? We do not know. Therefore, such label annotation work is very challenging.
In situations where you do not know what the correct answer looks like, RL might be very useful.
Of course, the machine is not entirely ignorant. While we do not know the correct answer, we still have an idea of what is relatively good or bad. The machine interacts with the environment and receives something called a Reward. That is to say, the machine can learn a model by interacting with the environment and knowing what kind of results are good or bad.
Basic Idea of Reinforcement Learning
Like the machine learning algorithms we learned previously, RL also follows three steps.
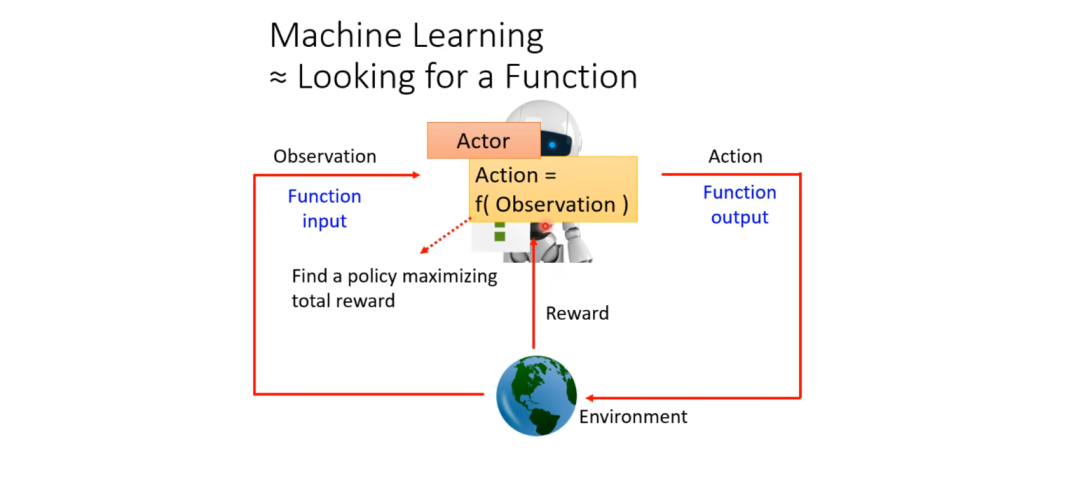
In our RL, there will be an Actor and an Environment, and this Actor will interact with the Environment.
Specifically, as shown in the diagram below, the environment gives the Actor an Observation, which serves as the input to the Actor. The Actor exists as a Function. The generated Action is the output of the Actor. In other words, the Actor functions by taking the Observation from the environment as input and generating an Action as output after transformation.
The generated Action will then affect the environment. The environment will provide the Actor with a new Observation based on this new Action, and the Actor will then generate a new Action.
In this process, the environment continuously gives the Actor some Reward to inform the Actor whether its Action is good or not.
Thus, we can say that we are looking for a function that takes Observation as input and Action as output, with the goal of maximizing the Reward. Note that the Reward should be the sum of the environmental incentives obtained from the environment.
If the above description seems abstract, let’s illustrate it with a specific example. We can use the example of Space Invaders, as shown in the diagram below.
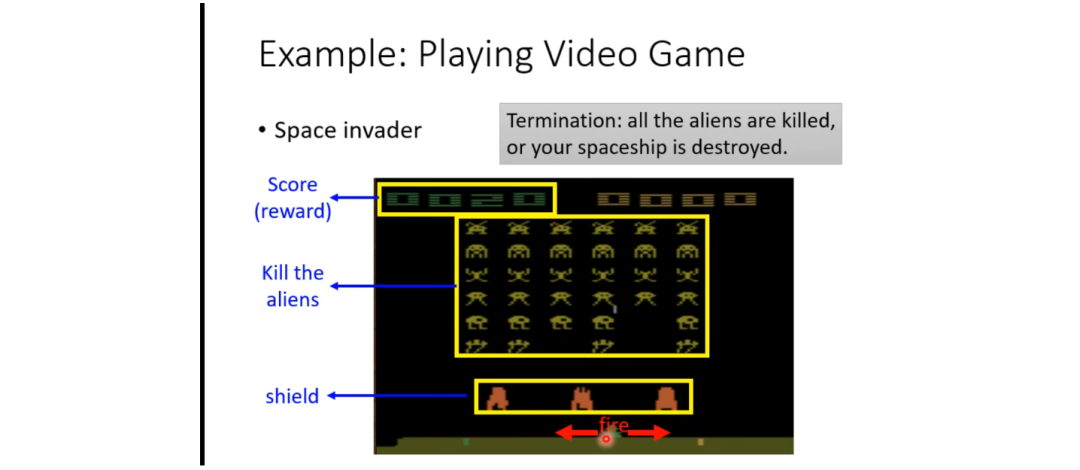
Here, the score in the upper left corner is equivalent to the Reward, and our Actions include moving left, moving right, and firing. Our goal is to eliminate all the aliens by firing while also having a shield to defend against their attacks. The game ends when all aliens are eliminated or when you are hit by an alien. Of course, in some versions, there might be a supply pack that grants bonus points when hit.
Now, if we use the model described above to depict this game, it looks like this (as shown in the diagram below):
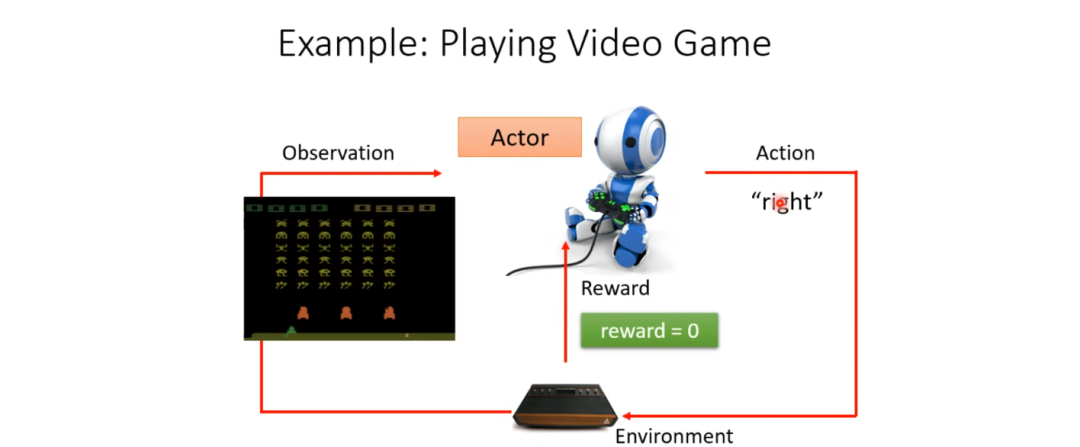
The observation is a series of game images from the console, and the Actions include moving left, moving right, and firing. When firing hits an alien, the environment will give the Actor a reward, say 5 points, while moving left and right gives 0 points. Our overall task is to train the Actor to maximize the reward obtained throughout the game.
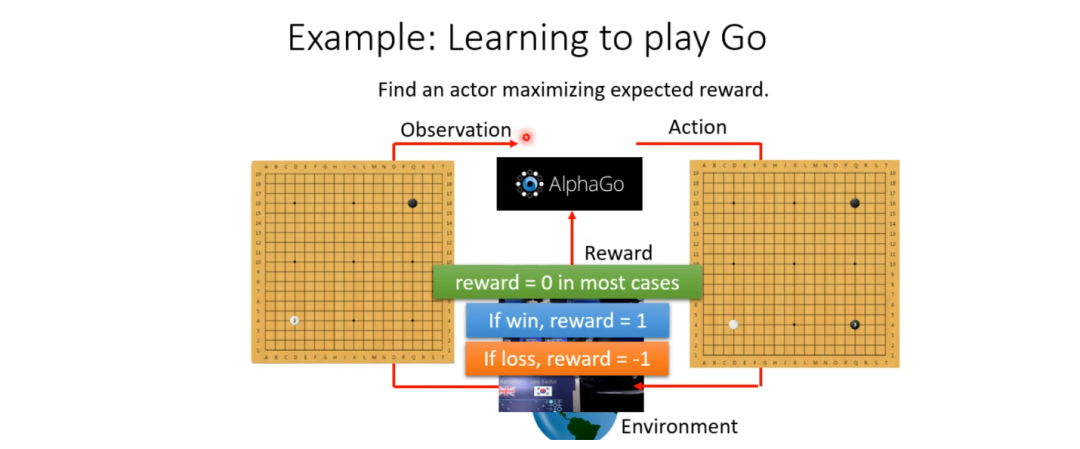
Next, let’s take another example of AlphaGo: when AlphaGo plays Go, its environment is its human opponent, while its input is the relative positions of black and white stones on the board, and its output is the position of the next move, each possibility corresponding to a position on the board, which is easy to understand.
After selecting the move position, the move is made, and the board after the move is fed back to the environment, which then generates a new Observation (this process is when the human opponent makes a move), and this is used as input for the Actor to generate a new Action, continuing this cycle.
Currently, we can assume that in most cases of playing Go, the reward is 0, and only when you win do you receive a reward, which we assume to be 1 point; if you lose, the reward is -1 point.
The Actor’s learning objective is to maximize its reward, which means it aims to win. Of course, we will discuss later how we can refine and optimize each move using other methods, such as sparse rewards. Training directly with this method is still too coarse.

As shown in the diagram above, in most cases of AlphaGo playing Go, the reward is 0, and only when you win do you receive a reward, which we assume to be 1 point; if you lose, the reward is -1 point.
This structure is intended to help everyone understand the entire RL process.
Previously, when we studied machine learning, we discussed that machine learning goes through three steps: finding a function with positional parameters, defining the Loss function, and optimizing.
RL also follows these three steps.
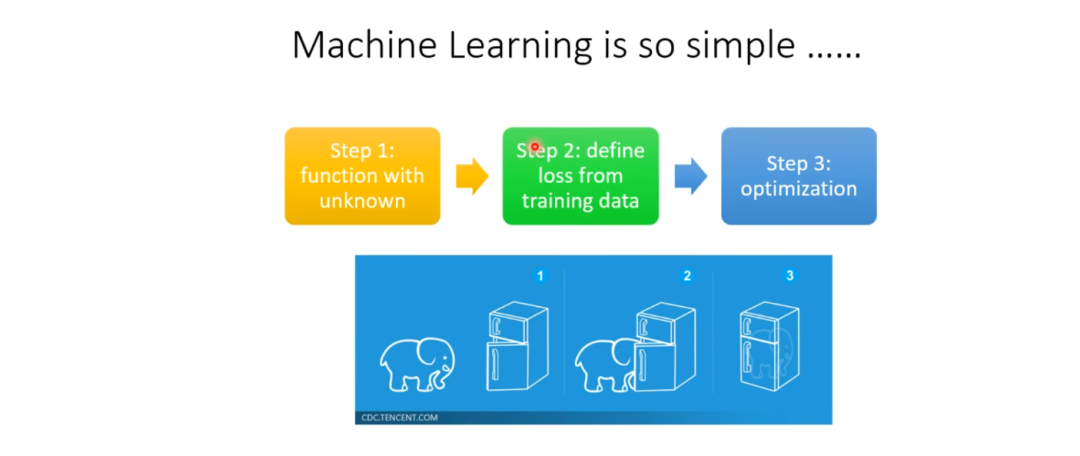
1. Finding a Function with Unknown Parameters
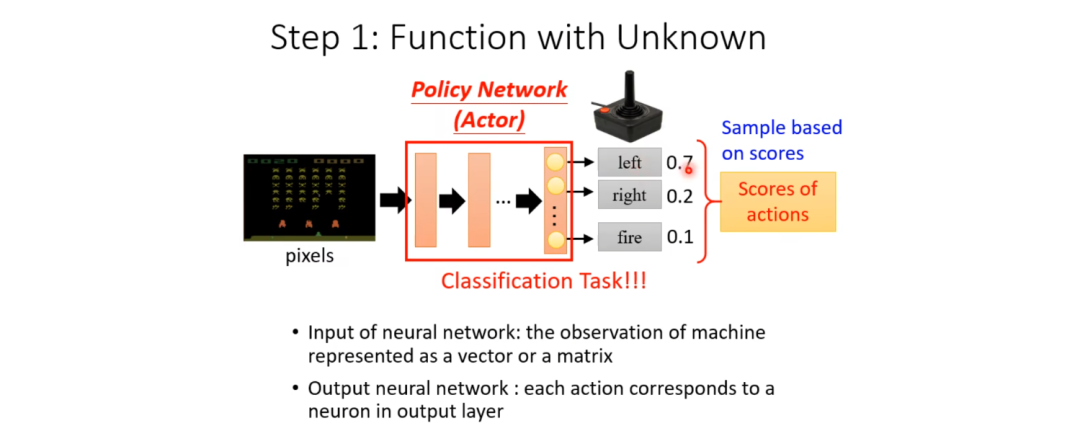
As we mentioned earlier, the function we are looking for with unknown parameters is actually the Actor. So what is the Actor? It is essentially a Network, which we now commonly refer to as a Policy Network. In the past, when Networks were not yet used for Actors, it might have just been a Look-Up Table, similar to a Key-Value structure, where you see what kind of result produces what kind of output.
Now we know that our function is a complex network.
In the examples we provided, the input is our pixels, and the output is the score for each action.
We can see that it is actually very similar to Classification.
For example, in the previous example, my input is my pixels, and my output is the choice to move left, move right, or fire, with their scores indicating a possibility.
How should the Network be structured? That is something you need to design yourself. For instance, when your input is an image, you might want to use CNN for processing. Of course, if you need to consider everything that has happened in the game so far, you might need RNN. You could also use Transformers, etc.
Ultimately, the machine’s decision on which Action to take depends on the probabilities obtained at the end; note that these final scores only represent the probabilities of performing these actions. The specific action the machine takes is actually sampled according to this probability. In other words, these scores only represent a probability; the action taken for each sample has a certain randomness. This randomness can be important for certain games, such as Rock-Paper-Scissors.
Returning to this major step, our first step is to find a function with unknown parameters, which is essentially a network with unknown parameters that we need to learn. This is our Actor.
2. Defining Loss
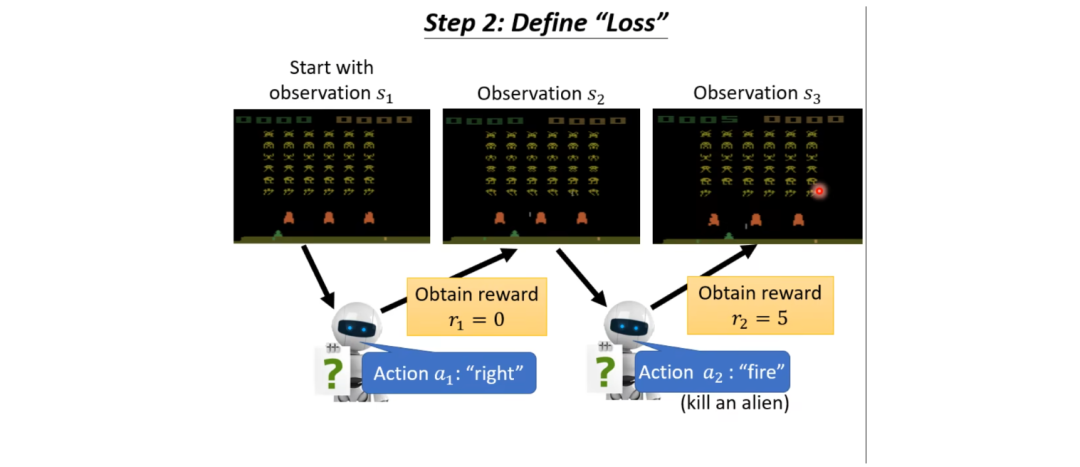
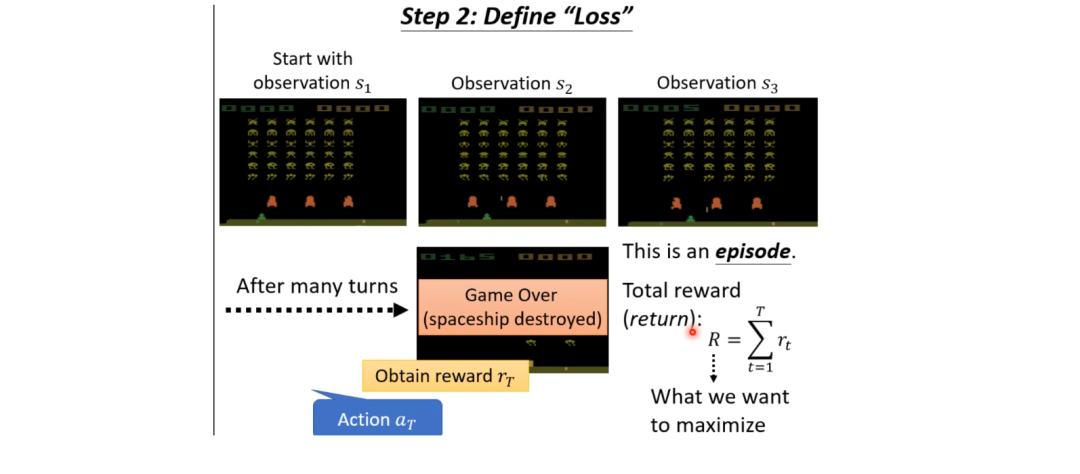
Now, let’s consider the following scenario (as shown in the diagram below):
Initially, we have a scene, which we call s1, and after processing by the Actor, it receives an action a1 (let’s assume this action is to move right), and since it did not kill any aliens, it receives a reward of 0; after moving right, a new observation is formed, which we call s2, and this s2 is then input into the Actor, which generates action a2 (let’s assume this action is to fire), and let’s say it kills an alien, receiving a reward of 5; then it obtains a new observation s3, and the machine continues to take new actions… This is one episode.
In such processes, the machine may take many actions, and each action corresponds to a reward. Our task is to gather all rewards to maximize the total reward (or return) of the game. 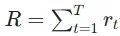 is what we aim to maximize. If you want to keep in line with the previous habit of minimizing the Loss, you can simply add a negative sign in front of R.
is what we aim to maximize. If you want to keep in line with the previous habit of minimizing the Loss, you can simply add a negative sign in front of R.
Specifically, the standard for judging an Actor’s quality is actually very similar to maximum likelihood estimation. Assuming we can enumerate all 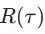 , then the expectation of Rθ can be expressed as
, then the expectation of Rθ can be expressed as 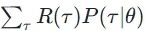 . If we sample n
. If we sample n 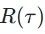 , then these n samples should be proportional to
, then these n samples should be proportional to 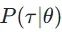 .
.
Note that what we will learn later (such as MC, TD, etc.) is to evaluate the quality of an Action, not the quality of an Actor.
3. Optimization
Let’s illustrate this with the following diagram:
The environment gives the Actor s1, and then s1 is processed by the Actor to obtain action a1, and then a1 is transformed through the environment to obtain s2, and then s2 is processed by the Actor to obtain a2, and so on; we call all actions and observations within the same episode s1, a1, s2, a2, etc. a trajectory; we obtain r1 from the Reward function based on s1 and a1, meaning that r1 is related to both a1 and s1. The reason is simple: sometimes an action must score in a specific environment. For example, firing must hit an alien to score.
We use R to represent the total score. Our goal is to maximize R.
So what is the specific problem of Optimization? It is to find a set of parameters in the Actor’s Network that maximizes the Reward when substituted into the Actor. That’s it. It’s just like a recurrent neural network.
However, RL differs from this, or the challenges lie in:
1. Your a1, … are sampled, meaning they are just samples and have a certain randomness. The a1 generated from the same s1 may not be the same each time.
2. Our Env and Reward are not Networks. They are merely black boxes. The term “black box” means that whatever input you provide, it will yield some output. However, you do not know what happens inside. Rewards often follow a rule, meaning that given such Observation and Action, you will receive a certain score. Therefore, it is often just a rule.
3. Sometimes it can be even worse—the environment and Reward can also be random. For example, in playing Go, when you make a move, your opponent’s next move may vary. Generally, for games, the Reward may be fixed. But in real-life scenarios, such as in autonomous driving, you may be unable to determine which method is good or bad; its Reward can also be random.

In fact, we also find that it is similar to GAN in some ways.
In training GANs, we connect the Generator and Discriminator for training. When adjusting the Generator’s parameters, we hope the Discriminator becomes larger. In RL, the Actor is equivalent to the Generator, and the Environment and Reward correspond to the Discriminator. We want to adjust the parameters of the Generator to maximize the Discriminator; in RL, we adjust the Actor’s parameters to maximize the Reward. Of course, there are differences: GAN’s Discriminator is also a Neural Network, allowing you to use Gradient Descent to adjust your parameters to achieve maximum output. But in RL, the Reward is not a Network; it is a black box. Therefore, you cannot use standard Gradient Descent methods to adjust your parameters to achieve maximum output.
Recruitment Requirements
Complete video production related to robots that meets the requirements.
Total duration must exceed 3 hours.
Video content must be a premium course, ensuring high quality and professionalism.
Instructor Rewards
Enjoy revenue sharing from the course income.
Receive 2 courses from GuYue Academy’s premium course offerings (excluding training camps).
Contact Us
Add the staff’s WeChat: GYH-xiaogu




