

Source: Hardware and Software Integration
Original Author: Chaobowx
Editor’s Note
With the popularity of ChatGPT, AGI (Artificial General Intelligence) has gradually seen the dawn of an explosion. In just one month, all the giants have quickly reacted, investing heavily and without regard for costs in the AGI field.
AGI is general intelligence based on large models; in contrast, the various previous forms of intelligence based on medium and small models for specific application scenarios can be termed specialized intelligence.
So, we can return to a topic that everyone often discusses: to the left (specialized) or to the right (general)? In the chip field, many specialized chips have been developed for specific scenarios. Can we, similar to the development of AGI, develop sufficiently general chips that can cover almost all scenarios while being extremely powerful in terms of functionality and performance?
1 Overview of AGI Development
1.1 The Concept of AGI
AGI, or Artificial General Intelligence, also known as Strong AI, refers to intelligence that possesses capabilities equal to or surpassing human intelligence, capable of exhibiting all intelligent behaviors characteristic of normal humans.
ChatGPT is the result of a qualitative change from the development of large models; it possesses certain AGI capabilities. With the success of ChatGPT, AGI has become the focal point of global competition.
Corresponding to AGI developed based on large models, traditional artificial intelligence based on medium and small models can also be called Weak AI. It focuses on a relatively specific business aspect, using models of relatively medium and small parameter scales and datasets to achieve relatively definite and simple applications of artificial intelligence scenarios.
1.2 One Feature of AGI: Emergence
“Emergence” is not a new concept. Kevin Kelly mentioned “emergence” in his book Out of Control, where “emergence” refers to the phenomenon where the collective of many individuals exhibits certain higher-level features that transcend individual characteristics.
In the field of large models, “emergence” refers to the significant performance improvement and the emergence of astonishing and unexpected abilities, such as language understanding, generative ability, and logical reasoning ability, when the model parameters exceed a certain scale.
For outsiders (like the author), the emergence ability can be simply explained as “qualitative change caused by quantitative change”: as the number of model parameters continues to increase, it finally breaks through a certain critical value, leading to qualitative changes that allow large models to exhibit many stronger and new capabilities.
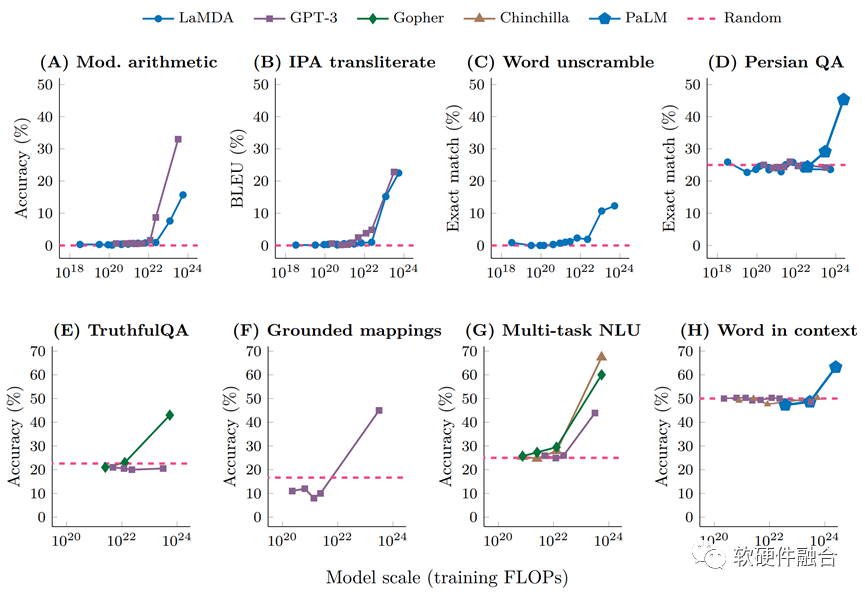
If you want to understand the detailed analysis of the emergence ability of large models, you can refer to Google’s paper Emergent Abilities of Large Language Models.
Of course, currently, the development of large models is still a very new field, and there are differing opinions on the “emergence” ability. For instance, researchers at Stanford University have questioned the claims regarding the emergence abilities of large language models, arguing that they are the result of artificially chosen metrics. See the paper Are Emergent Abilities of Large Language Models a Mirage? for details.
1.3 Another Feature of AGI: Multimodality
Each source or form of information can be referred to as a modality. For example, humans have touch, hearing, vision, etc.; the media of information include text, images, audio, video, etc.; various types of sensors, such as cameras, radar, and LiDAR. Multimodal, as the name suggests, refers to expressing or perceiving things from multiple modalities. Multimodal machine learning refers to learning from various modal data and enhancing its algorithms.
Traditional medium and small scale AI models are mostly unimodal. For instance, algorithms focusing on language recognition, video analysis, image recognition, and text analysis are all single-modal algorithm models.
Since the emergence of chatGPT based on Transformer, most subsequent large AI models have gradually achieved support for multimodality:
-
Firstly, they can learn from multimodal data such as text, images, audio, and video;
-
Moreover, the abilities learned from one modality can be applied to reasoning in another modality;
-
Additionally, the abilities learned from different modal data can fuse to form new abilities that exceed the learning capabilities of a single modality.
The classification of modalities is artificially divided; the information contained in various modal data can be uniformly understood by AGI and converted into the model’s capabilities. In medium and small models, we have artificially severed much information, thus limiting the intelligent capabilities of AI algorithms (in addition, the parameter scale of the model and its architecture also significantly impact intelligent capabilities).
1.4 Another Feature of AGI: Generality
Since deep learning entered our sight in 2012, AI models for various specific application scenarios have sprung up like mushrooms after rain. For example, license plate recognition, facial recognition, speech recognition, etc., including some comprehensive scenarios like autonomous driving and metaverse scenarios. Each scenario has different models, and within the same scenario, many companies have developed various algorithms and models with different architectures. It can be said that AI models during this period are extremely fragmented.
However, with the advent of GPT, people have seen the dawn of general AI. The ideal AI model can take training data in any form and for any scenario, learning almost “all” capabilities and making any necessary decisions. Of course, the key point is that the intelligent capabilities of AGI based on large models are far superior to those of traditional medium and small models used for specific situations.
Once fully general AI appears, on one hand, we can extend it to achieve AGI+ various scenarios; on the other hand, as algorithms gradually become certain, it provides space for AI to continuously optimize, thereby continuously optimizing AI computing power. The continuous improvement of computing power, in turn, promotes the model to evolve and upgrade to larger parameter scales.
2 The Relationship Between Specialized and General
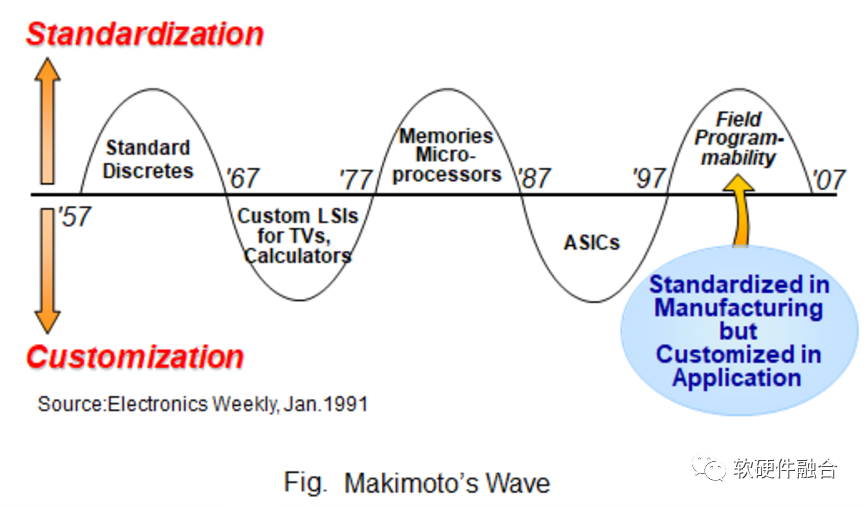
Makimoto’s Wave is a development law in the electronics industry similar to Moore’s Law, which posits that integrated circuits regularly alternate between “general” and “specialized,” with a cycle of about 10 years. Therefore, many people in the chip industry believe that “general” and “specialized” are equivalent, balancing on two sides of a scale. The design and development of products, whether leaning towards general or specialized, is based on the trade-offs of customer scenario needs.
However, from the perspective of AGI development, AGI based on large models is not a matter of weighing two ends against each other compared to traditional specialized artificial intelligence based on medium and small models; rather, it is a question of upgrading from low-level intelligence to high-level intelligence. Let’s revisit the history of computing chip development with this perspective:
-
Application-Specific Integrated Circuits (ASICs) have always existed as a chip architecture form throughout the development of integrated circuits;
-
Before the advent of CPUs, almost all chips were ASICs; however, after the emergence of CPUs, they quickly dominated the chip landscape; the ISA of CPUs includes basic instructions such as addition, subtraction, multiplication, and division, making CPUs completely general processors.
-
The initial positioning of GPUs was as specialized graphics processors; since GPUs were transformed into parallel computing platforms (GP-GPUs), aided by CUDA for user development, they have become the king in the heterogeneous era.
-
With the increasing complexity of systems, the differences in different customer systems, and the rapid iteration of customer systems, ASIC architecture chips are becoming less suitable. The industry has gradually seen the rise of Domain-Specific Architectures (DSA), which can be understood as a callback from ASICs to general programmable capabilities; DSA is an ASIC with certain programming capabilities. ASICs are oriented towards specific scenarios and fixed business logic, while DSA is oriented towards various scenarios in a domain, with its business logic being programmable. Even so, in AI scenarios that are extremely sensitive to performance, AI-DSA has not been successful compared to GPUs, mainly because AI scenarios change rapidly, while AI-DSA chip iteration cycles are too long.
From a long-term development perspective, the evolution of specialized chips is paving the way for general chips. General chips will extract more essential and sufficiently general computational instructions or transactions from various specialized computations and integrate them into the design of general chips. For example:
-
CPUs are completely general but have weak performance, so they achieve hardware acceleration and performance improvement through vector and tensor co-processors.
-
With limited acceleration capabilities, GPUs emerged as a general parallel acceleration platform. GPUs are still not the highest-performing acceleration method, which led to the development of Tensor Core acceleration methods.
-
The Tensor Core method still has not completely unleashed the performance of computing. Therefore, fully independent DSA processors have emerged.
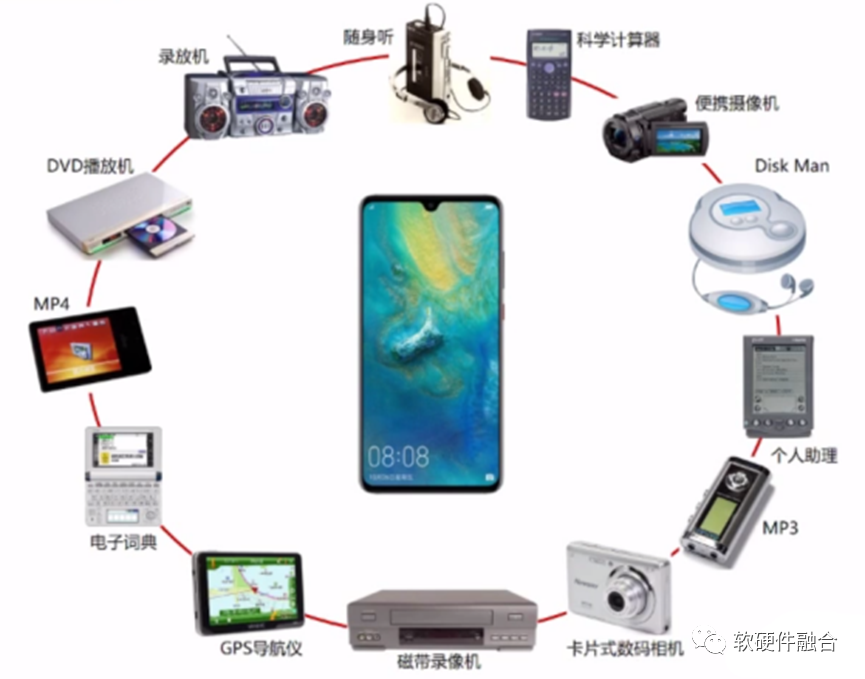
Smartphones are a classic case of general versus specialized: before the emergence of smartphones, various handheld devices were abundant; after the advent of smartphones, these function-specific devices gradually disappeared into history.
General and specialized are not equal aspects for designers to weigh; the transition from specialized to general is a process from low-level to high-level. In the short term, general and specialized progress alternately; however, from a longer-term development perspective, specialization is temporary, while generality is eternal.
3 Is a General Processor Feasible?
CPUs are general processors, but as Moore’s Law has failed, CPUs have become less useful. This has led to another wave of specialized chip design: in 2017, Turing Award winners John Hennessy and David Patterson proposed the “Golden Age of Architectures,” suggesting that the coming period would present significant opportunities for the development of specialized processors (DSA).
However, the past 5-6 years of practice have shown that the golden age of specialized chips represented by DSA has been insufficient. Instead, under the influence of large AI models, the golden age of general GPUs has been achieved.
Of course, GPUs are not perfect: like CPUs, GPU performance is about to reach its limit. Currently, GPU clusters supporting GPT large models require tens of thousands of GPU processors; on one hand, the overall efficiency of the cluster is low, and on the other hand, the construction and operation costs of the cluster are extremely high.
Can we design a more optimized processor that possesses the characteristics of a general processor, being as “universal” as possible, while also achieving higher efficiency and performance? Here are some viewpoints:
-
We can break down the systems running on computers into several work tasks, such that some software processes or combinations of similar software processes can be viewed as a work task;
-
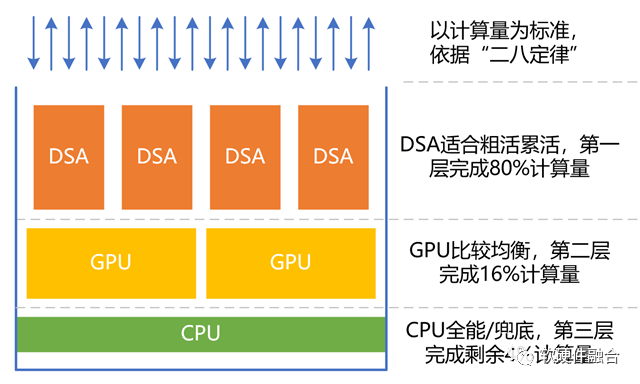
The widely known 80/20 rule: the work tasks in the system are not completely random; many work processes are relatively definite, such as virtualization, networking, storage, security, databases, file systems, and even AI inference, etc.; moreover, even the relatively random computing tasks at the application layer will still contain a large amount of deterministic computing components, such as some applications containing security, video graphics processing, and AI.
-
We can simply categorize processors (engines) into three types based on performance efficiency and flexibility: CPU, GPU, and DSA.
-
Similar to a “tower defense game,” based on the 80/20 rule, we assign 80% of the computing tasks to be handled by DSA, 16% of the tasks to GPU, while CPU is responsible for the remaining 4% of other tasks. The important role of the CPU is to provide a safety net.
-
By matching the characteristics of performance/flexibility to the most suitable processor computing engine, we can achieve extreme performance while maintaining sufficient generality.
4 The History and Development of General Processors
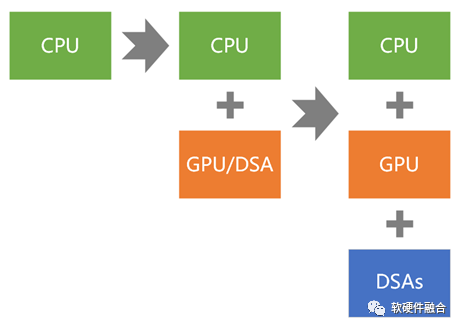
If we take general computing as a standard, the evolution of computing architecture can be simply divided into three stages: from homogeneous to heterogeneous, and then continuously evolving into super heterogeneous:
-
First Generation of General Computing: CPU Homogeneous.
-
Second Generation of General Computing: CPU + GPU Heterogeneous.
-
Third Generation (Next Generation) of General Computing: CPU + GPU + DSAs Super Heterogeneous.
4.1 First Generation of General Computing: CPU Homogeneous
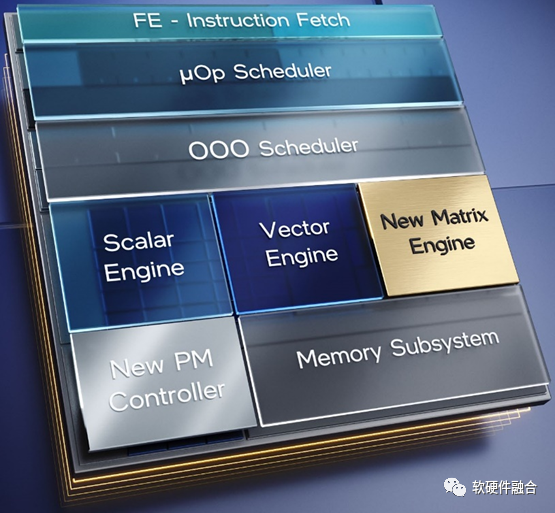
Intel invented the CPU, marking the first generation of general computing. This first generation of general computing established Intel’s dominant position for nearly 30 years until around 2000.
The performance of CPU scalar computing is very weak; thus, CPUs have gradually introduced vector instruction set processing with AVX co-processors and matrix instruction sets with AMX co-processors, continuously optimizing CPU performance and computational efficiency, and expanding the CPU’s operational space.
4.2 Second Generation of General Computing: CPU + GPU Heterogeneous
The approach of CPU co-processors is inherently constrained by the original architecture of the CPU, resulting in performance ceilings. In relatively small-scale acceleration computing scenarios, it may barely suffice. However, in large-scale acceleration computing scenarios such as AI, due to its low performance ceiling and inefficiency, it is not very suitable. Therefore, a completely independent and more robust acceleration processor is needed.
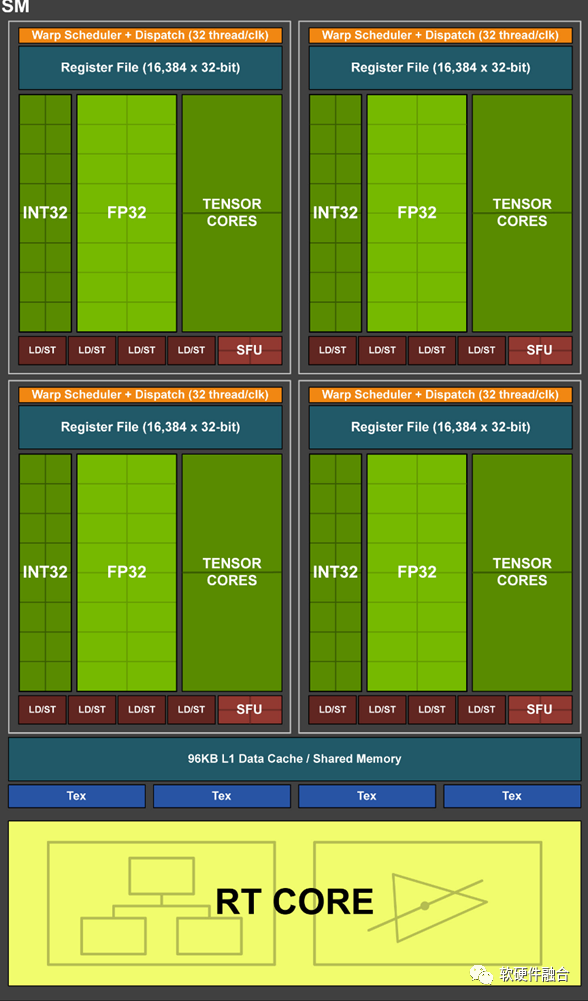
GPUs are the typical acceleration processor and are a general parallel computing platform. GPU computing requires a Host CPU for control and coordination, leading to the specific implementation form of CPU + GPU heterogeneous computing architecture.
NVIDIA invented GP-GPU and provided the CUDA framework, promoting the widespread application of the second generation of general computing. With the development of AI deep learning and large models, GPUs have become the hottest hardware platform, contributing to NVIDIA’s trillion-dollar market value (surpassing the combined market value of chip giants like Intel, AMD, and Qualcomm).
Of course, the thousands of CUDA cores within GPUs are essentially more efficient small CPU cores, so their performance efficiency still has room for improvement. Thus, NVIDIA developed Tensor Cores to further optimize the performance and efficiency of tensor computations.
4.3 Third Generation (Future-Oriented) General Computing: CPU + GPU + DSAs Super Heterogeneous
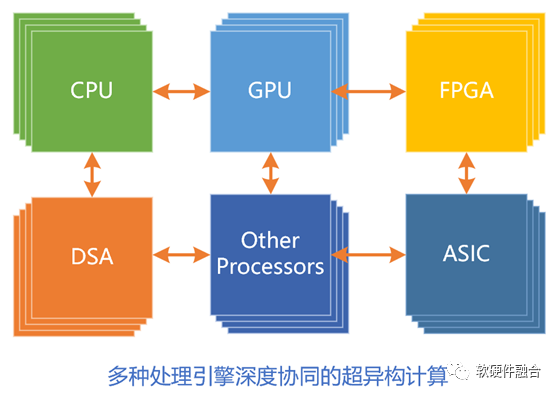
Technological development knows no bounds. The third generation of general computing, which is a super heterogeneous computing architecture integrating various heterogeneous components, faces challenges for future demands for greater computing power:
-
Firstly, there are three levels of independent processing engines: CPU, GPU, and DSA (correspondingly, the first generation only had one, and the second generation had two).
-
Various acceleration processing engines compose a CPU + XPU heterogeneous computing architecture alongside the CPU.
-
Super heterogeneous is not merely an integration of multiple heterogeneous computations but a deep fusion of various heterogeneous computing systems, from software to hardware levels.
-
For super heterogeneous computing to succeed, it must achieve sufficient generality. If generality is not considered, the more computing engines in the super heterogeneous architecture compared to the past will exacerbate the fragmentation issue. Software personnel will be at a loss, and super heterogeneous will not succeed.
Reproduced content only represents the author’s views
It does not represent the position of the Institute of Semiconductors, Chinese Academy of Sciences
Editor: Qian Niao
