

Source: DeepHub IMBA
This article is approximately 2000 words long and is recommended for a 5-minute read.
This article introduces how to use the new FlexAttention and BlockMask features introduced in PyTorch version 2.5 and above to implement causal attention mechanisms and handle padded inputs.
Given the current lack of complete code examples and technical discussions on FlexAttention for handling padded input sequences online, this article will elaborate on an implementation method that also covers the implementation of causal attention mechanisms.
This article will not discuss the theoretical foundations of FlexAttention in detail; for more technical details, please refer to the official PyTorch blog.
Environment Configuration
git clone https://github.com/pytorch-labs/attention-gym.git cd attention-gym pip install . cd ../We install via the attention-gym repository to ensure compatibility between components while gaining access to its visualization tools.
MultiheadFlexAttention Implementation
To effectively use flex_attention within the transformer architecture, it needs to be implemented in the multi-head attention module.
class MultiheadFlexAttention(nn.Module): def __init__(self, d_in, d_out, n_heads, bias=False): """ Description: PyTorch module implementing multi-head self-attention based on flex_attention Parameters: d_in: int, input tensor dimension d_out: int, output tensor dimension n_heads: int, number of attention heads bias: bool, whether to use bias in query, key, and value calculations """ super().__init__() assert d_out % n_heads == 0, "d_out must be divisible by n_heads" self.n_heads = n_heads self.d_head = d_out // n_heads self.d_out = d_out self.in_proj = nn.Linear(d_in, 3 * d_out, bias=bias) self.out_proj = nn.Linear(d_out, d_out)This defines the core parameters of the model, including input and output dimensions and linear transformation layers.
def forward(self, x, block_mask): """ Description: The forward computation process of the multi-head self-attention module Parameters: x: torch.Tensor, input tensor with dimensions (batch_size, max_seq_len, d_in) block_mask: torch.Tensor, block mask used by flex_attention """ batch_size, max_seq_len, d_in = x.shape # Generate query, key, value representations through linear transformation qkv = self.in_proj(x) # Decompose and reshape qkv into multi-head format qkv = qkv.view(batch_size, max_seq_len, 3, self.n_heads, self.d_head) # Adjust tensor dimensions to fit flex_attention input requirements qkv = qkv.permute(2, 0, 3, 1, 4) # Parse to obtain query, key, value tensors queries, keys, values = qkv # Calculate attention weights using flex_attention attn = flex_attention(queries, keys, values, block_mask=block_mask) # Merge multi-head attention outputs attn = attn.transpose(1, 2).contiguous().view(batch_size, max_seq_len, self.d_out) # Perform output mapping attn = self.out_proj(attn) return attn, queries, keysThe implementation of this forward function is similar to the standard PyTorch MultiheadAttention class, with the main difference being the introduction of the block_mask parameter and the use of the flex_attention function for attention calculation.
mask_mod Function Implementation
The core advantage of FlexAttention lies in its ability to efficiently implement and use custom attention masks without writing specific CUDA core code.
To use this feature, the mask needs to be defined as a boolean tensor. First, we implement a causal mask, which is a basic example provided by the FlexAttention developers in their official blog.
Causal Mask
def causal(b, h, q_idx, kv_idx): return q_idx >= kv_idxParameter explanations:
-
b: batch size
-
h: number of attention heads
-
q_idx: query position index
-
kv_idx: key/value position index
For example, for an input sequence length of 5, q_idx is represented as torch.Tensor([0,1,2,3,4]).
q_idx >= kv_idx returns a causal boolean mask, ensuring that attention calculations only consider the current position and previous tokens.
Next, we will implement a padding mask to handle the padding part of variable-length sequences.
Padding Mask Implementation
The main difference between the padding mask and the causal mask is its batch dependency, meaning the mask values depend on the specific positions of padding tokens in each sequence. When implementing, it is necessary to identify the padding tokens to be ignored in the sequence using a padding token table.
def create_padding_mask(pads): def padding(b, h, q_idx, kv_idx): return ~pads[b, q_idx] & ~pads[b, kv_idx] return paddingpads is a boolean tensor with the shape (batch_size, max_seq_len), where padding positions are marked as True and valid token positions are marked as False. This padding mask_mod function generates a padding mask that only allows attention calculations when both query and key/value positions are non-padding tokens.
Experimental Setup and Data Preparation
Before combining masks and applying them to MultiheadFlexAttention, relevant parameters need to be set and experimental data prepared.
# Multi-head attention parameter configuration d_in = 64 d_out = 64 n_heads = 8 # Initialize multi-head attention module mhfa = MultiheadFlexAttention(d_in, d_out, n_heads).to(device) # Data dimension settings batch_size = 1 # Supports any batch size max_seq_len = 10 # Generate random input data input_data = torch.randn(batch_size, max_seq_len, d_in).to(device)Next, modify the input_data to add random trailing zero padding. # Add random zero padding pad = torch.zeros(1, d_in).to(device) pad_idxs = [(b, range(torch.randint(max_seq_len//2, max_seq_len + 1, (1,)).item(), max_seq_len)) for b in range(batch_size)] for b, idxs in pad_idxs: input_data[b, idxs] = padNow, we need to construct the padding token table for the padding mask_mod function.
# Build padding token mask collapsed_input = input_data[:, :, 0] # (batch_size, max_seq_len) pads = torch.eq(collapsed_input, 0).to(device)Note that the mask_mod function does not need to consider the embedding dimension of input_data, so the dimension can be compressed when creating the padding token table (pads).
Combining Causal Mask and Padding Mask
At this point, we have all the components needed to create a comprehensive attention mask.
# Build combined mask causal_mask = causal padding_mask = create_padding_mask(pads) masks = [causal, padding_mask] combined_mask = and_masks(*masks) causal_padding_mask = create_block_mask(combined_mask, B=batch_size, H=None, Q_LEN=max_seq_len, KV_LEN=max_seq_len, _compile=True)Here, we combine the causal and padding mask_mod functions using the and_masks function provided by torch.flex_attention to generate a unified BlockMask.
Note: The development team recommends enabling the _compile_ parameter to significantly improve the efficiency of BlockMask generation, which is especially important for batch-related mask processing.
Now we can use the MultiheadFlexAttention class to perform attention calculations on input_data while applying the compiled custom attention mask.
# Perform forward computation attn_output, query, key = mhfa(input_data, causal_padding_mask)Use the visualization tools provided by attention-gym to analyze the attention distribution.
# Visualize attention distribution for the first sequence visualize_attention_scores( query, key, mask_mod=combined_mask, device=device, name="causal_padding_mask", path=Path("./causal_padding_mask.png"), )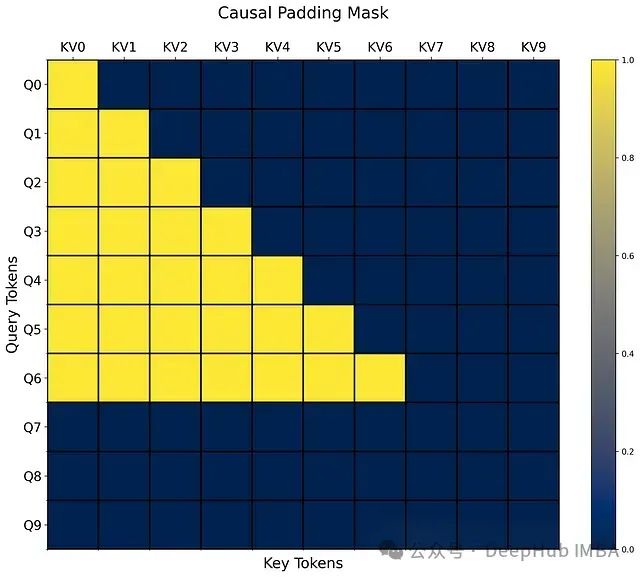
The above image shows the causal attention distribution after masking for a sequence containing three padding tokens.
From the visualization results, it can be observed that both the attention weights for padding tokens and future tokens are effectively masked, validating the correctness of the implementation.
About Us
Data Pie THU, as a public account for data science, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a data talent gathering platform, creating the strongest group of big data in China.

Sina Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today’s Headlines: 数据派THU