Author丨Error@ZhihuSource丨https://zhuanlan.zhihu.com/p/159173338Reprinted from | Jishi Platform
Abstract
This article first clarifies the differences between the definitions of semantic segmentation, instance segmentation, and panoptic segmentation. On this basis, it further analyzes the applicability of algorithms such as FCN, Unet, and Unet++ in medical imaging.
First, the table of contents:
- Explanation of Related Knowledge Points
- Understanding of FCN Network Algorithm
- Understanding of Unet Network Algorithm
- Understanding of Unet++ Network Algorithm
- Understanding of Unet+++ Network Algorithm
- Brief Overview of DeepLab v3+ Algorithm
- Applicability of Unet in Medical Imaging and Brief Summary of CNN Segmentation Algorithms
1. Explanation of Related Knowledge Points
1. Differences in Definitions of Image Segmentation
Semantic Segmentation: This refers to classifying all pixels in an image. (e.g., FCN/Unet/Unet++/…)
Instance Segmentation: This can be understood as a combination of object detection and semantic segmentation. (e.g., Mask R-CNN/…) Compared to the bounding box in object detection, instance segmentation can be precise to the edges of the object; compared to semantic segmentation, instance segmentation needs to label different instances of the same object in the image.
Panoptic Segmentation: This can be understood as a combination of semantic segmentation and instance segmentation. Instance segmentation only detects objects in the image and segments the detected objects; panoptic segmentation detects and segments all objects in the image, including the background.
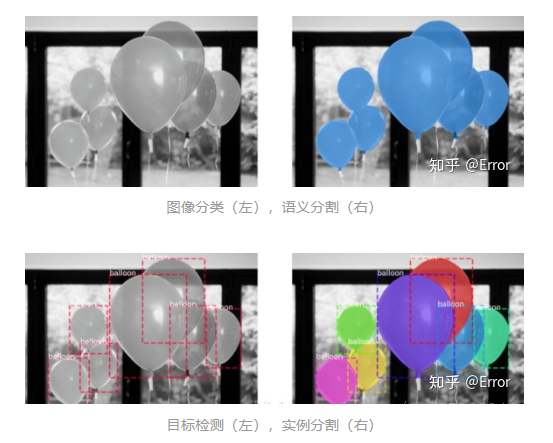
Image Classification: A balloon in the image is one category. [1] Semantic Segmentation: Segmenting the balloon and the background. Object Detection: There are 7 target balloons in the image, and the coordinates of each balloon are detected. Instance Segmentation: There are 7 different balloons in the image, with pixels belonging to each balloon provided at the pixel level.
2. Advantages of CNN Feature Learning
High-resolution features (shallower convolution layers) have a small receptive field, which is beneficial for aligning feature maps with the original image, providing more location information. Low-resolution information (deeper convolution layers) has a larger receptive field and can learn more abstract features, providing more contextual information, i.e., strong semantic information, which is conducive to precise pixel classification.
3. Upsampling (the significance is to restore small-sized high-dimensional feature maps)
Upsampling generally includes two methods:
Resize, such as bilinear interpolation directly scaling the image (this method is mentioned in the original text)Deconvolution (also known as Transposed Convolution) [2], which can be understood as the inverse operation of convolution.
4. Several Evaluation Metrics for Semantic Segmentation in Medical Imaging [3]
1) Jaccard (IoU)
Used to compare the similarity and differences between finite sample sets. The larger the Jaccard value, the higher the sample similarity.
For understanding TP, FP, TN, FN, you can refer to my other blog post on mAP calculation in object detection: https://zhuanlan.zhihu.com/p/139073511
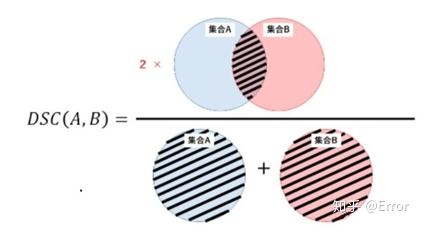
2) Dice Similarity Coefficient
A measure of set similarity, usually used to calculate the similarity between two samples, with a value range of 0~1, where the best segmentation result is 1 and the worst is 0. Dice similarity coefficient is sensitive to the internal filling of masks.
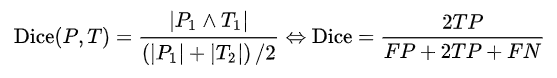
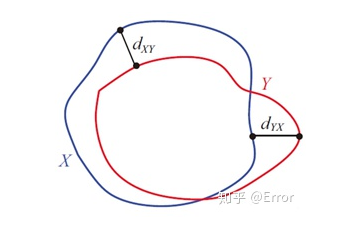
3) Hausdorff Distance
A measure of the similarity between two sets of points, sensitive to the boundaries of the segmented objects.
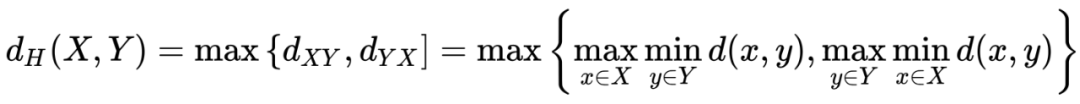
4) F1-score
A metric for measuring the accuracy of binary classification models, considering both the precision and recall of the classification model, which can be viewed as a weighted average of precision and recall.
2. Understanding the FCN Network
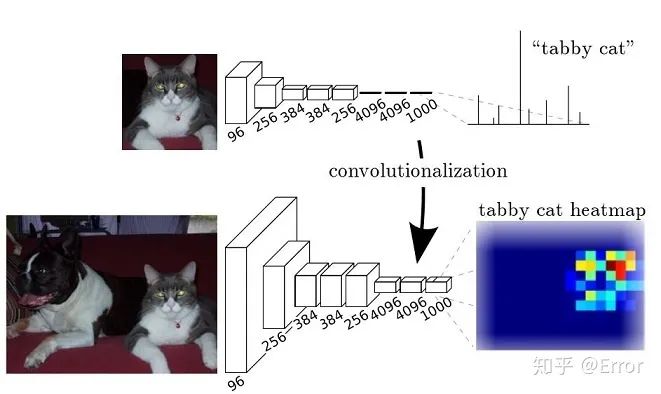
FCN replaces the last fully connected (FC) layer of a typical classical classification network model (VGG16…) with convolution, allowing classification information for each pixel to be obtained through a two-dimensional feature map followed by softmax, thus solving the segmentation problem.
Core Idea: – A fully convolutional (fully conv) network without fully connected layers (fc). Adaptable to arbitrary input sizes. – The deconvolution (deconv) layer increases the data size. It can output fine results. – A skip structure that combines results from different depth layers, ensuring robustness and accuracy.
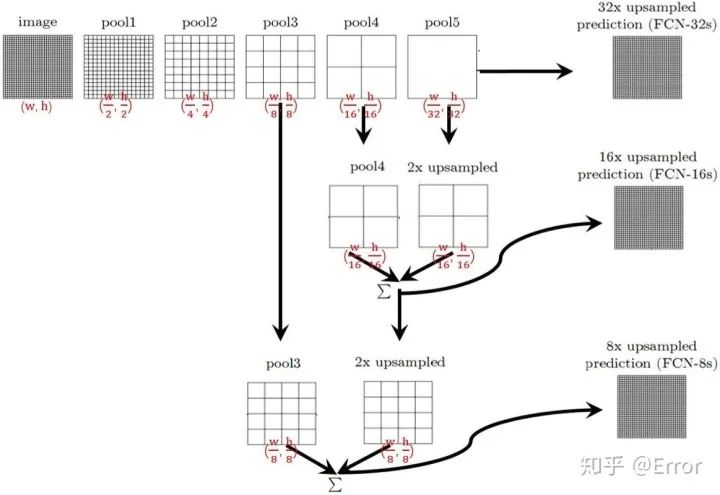
Illustration of FCN Structure
For FCN-32s, the pool5 feature is directly upsampled 32 times to obtain a 32x upsampled feature, and then softmax prediction is performed on each point of the 32x upsampled feature to obtain the 32x upsampled feature prediction (i.e., the segmentation map). For FCN-16s, the pool5 feature is first upsampled 2 times to obtain a 2x upsampled feature, then the pool4 feature is added pointwise to the 2x upsampled feature, and the combined feature is upsampled 16 times with softmax prediction to obtain the 16x upsampled feature prediction. For FCN-8s, the pool4 + 2x upsampled feature is added pointwise, and then the pool3 + 2x upsampled feature is added pointwise, i.e., more feature fusion is performed.

Disadvantages of FCN:
The results are not fine enough. Although 8 times upsampling is much better than 32 times, the upsampling results are still relatively blurry and smooth, and not sensitive to details in the image.
Classifying each pixel does not fully consider the relationships between pixels. It ignores the spatial regularization step used in typical pixel classification-based segmentation methods, lacking spatial consistency.
Attachment FCN paper link:https://arxiv.org/abs/1411.4038
3. Understanding the U-net Network
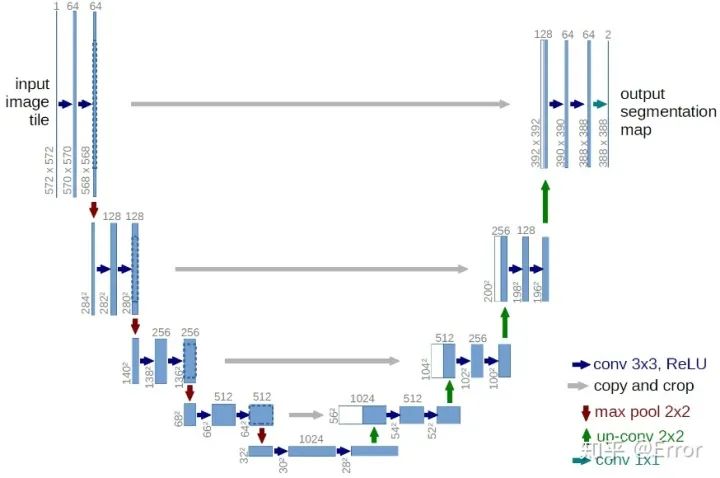
U-net Network Structure Diagram
The entire U-Net network structure resembles a large letter U, and like FCN, it is a small segmentation network that neither uses dilated convolutions nor follows with CRF, making the structure simple.
1. First perform Conv + Pooling downsampling; 2. Then perform deconvolution for upsampling, crop the previous low-level feature map, and perform fusion; 3. Upsample again. 4. Repeat this process until obtaining an output feature map of 388x388x2, 5. Finally, perform softmax to obtain the output segment map. Overall, it is very similar to the FCN approach.
The U-Net encoder downsamples 4 times, downsampling a total of 16 times, and its decoder correspondingly upsamples 4 times, restoring the high-level semantic feature maps obtained from the encoder to the original image resolution.
It adopts a different feature fusion method than FCN:
- FCN uses pointwise addition, corresponding to the tensorflow function tf.add()
- U-Net uses channel dimension concatenation, corresponding to the tensorflow function tf.concat()
Attachment U-net paper link:https://arxiv.org/pdf/1505.04597.pdf
4. Understanding the Unet++ Network [4]
The article improves upon Unet primarily through skip connections. The author believes that directly combining shallow features from the encoder with deep features from the decoder in Unet is inappropriate, as it creates a semantic gap.
The article hypothesizes: When the combined shallow features and deep features are semantically similar, the optimization problem of the network becomes simpler. Therefore, the improvement on skip connections aims to bridge/reduce this semantic gap.
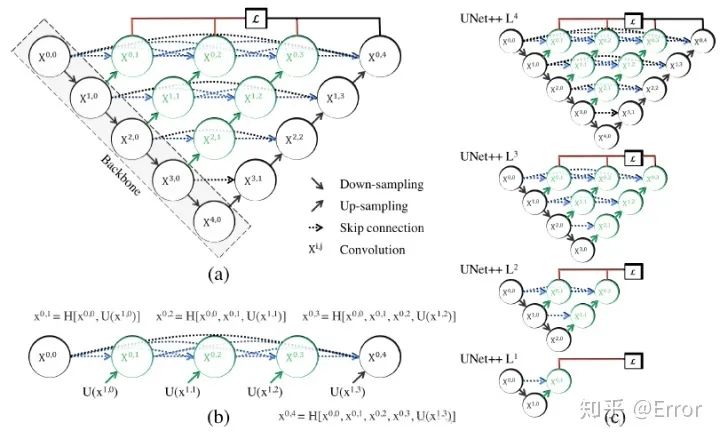
Attachment Unet++ paper link: https://arxiv.org/pdf/1807.10165.pdf
Code link:https://github.com/MrGiovanni/UNetPlusPlus
5. Understanding the Unet+++ Algorithm [5]
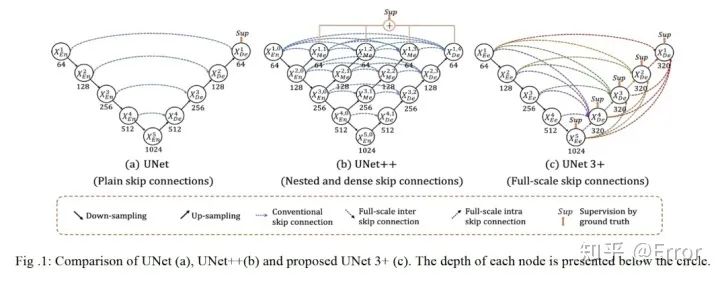
To compensate for the shortcomings of UNet and UNet++, each decoder layer in UNet 3+ integrates feature maps of small scale and the same scale from the encoder, as well as large-scale feature maps from the decoder, these feature maps capture fine-grained semantics and coarse-grained semantics across all scales.
Attachment U-net+++ paper link:https://arxiv.org/abs/2004.08790
6. Brief Overview of the DeepLab v3+ Algorithm [6]
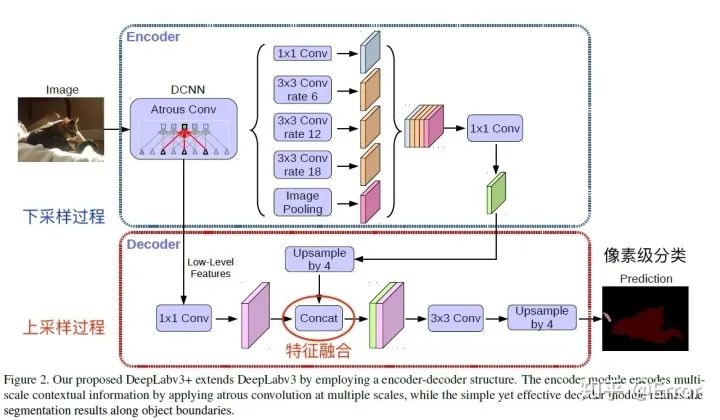
DeepLab v3+ Structure Diagram
Encoder Part
The encoder is the original DeepLabv3, with some points to note: 1. The input size to output size ratio (output stride = 16), and the dilation rate of the last stage is 22. The Atrous Spatial Pyramid Pooling module (ASPP) has four different rates, plus one global average pooling.
Decoder Part
First, upsample the encoder’s results by 4 times, then concatenate with the Conv2 features before downsampling in ResNet, followed by a 3×3 convolution, and finally upsample 4 times to obtain the final result. Points to note: Before integrating low-level information, perform a 1×1 convolution to reduce channels (for example, if there are 512 channels, while the encoder result has only 256 channels).
Attachment DeepLab v3+ paper link: https://arxiv.org/pdf/1802.02611.pdf
7. Applicability of Unet in Medical Imaging and Brief Summary of CNN Segmentation Algorithms
1. Characteristics of Unet Structure
Compared to FCN and DeepLab, UNet performs 4 upsampling operations and uses skip connections within the same stage, rather than directly supervising and backpropagating loss on high-level semantic features. This ensures that the final restored feature map integrates more low-level features, allowing for the fusion of features at different scales, thus enabling multi-scale prediction and Deep Supervision. The 4 upsampling operations also make the segmentation map restore edge information more precisely.
2. Why is it suitable for medical imaging? [7]
1. Because medical images have fuzzy boundaries and complex gradients, they require a lot of high-resolution information for precise segmentation. 2. The internal structure of the human body is relatively fixed, and the distribution of segmentation targets in human images is very regular, with simple and clear semantics. Low-resolution information can provide this information for object recognition. UNet combines low-resolution information (providing basis for object category recognition) and high-resolution information (providing basis for precise segmentation positioning), making it perfectly suitable for medical image segmentation.
3. Summary of Segmentation Algorithm Improvements:
- Downsampling + Upsampling: Convolution + Deconvolution/Resize
- Multi-scale Feature Fusion: Pointwise addition of features/channel dimension concatenation
- Obtaining Pixel-level Segment Maps: Judging the category for each pixel point
References
- Understanding Instance Segmentation https://blog.csdn.net/tony2278/article/details/90028747?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-4.nonecase
- Refer to several operations of convolution https://blog.csdn.net/attitude_yu/article/details/84697181
- https://zhuanlan.zhihu.com/p/117435908?from_voters_page=true
- Zhou Zongwei’s study of Unet https://zhuanlan.zhihu.com/p/44958351UNet3+(UNet+++) paper interpretation https://zhuanlan.zhihu.com/p/136164721Understanding the DeepLab series https://www.jianshu.com/p/755b001bfe38Why does the Unet neural network perform well in medical image segmentation? https://www.zhihu.com/question/269914775
