
Source: Zhihu, Jishi Platform, Deep Learning Enthusiasts
Author: Li Muqing @ Zhihu
https://zhuanlan.zhihu.com/p/104854615
This article is about 5100 words long and is recommended for a 10-minute read.
This article first introduces some classic semantic segmentation networks and their innovations, and then discusses some applications of network structure design in the field of medical image segmentation.
This article summarizes the innovations in network structure when using CNNs for image semantic segmentation. These innovations mainly include the design of new neural architectures (different depths, widths, connections, and topologies) and the design of new components or layers. The former involves assembling complex large networks using existing components, while the latter is more focused on designing low-level components. First, we introduce some classic semantic segmentation networks and their innovations, and then discuss some applications of network structure design in the field of medical image segmentation.
1. Innovations in Image Semantic Segmentation Network Structure
1.1 FCN Network
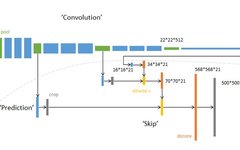
FCN Overall Architecture Diagram
The FCN network is singled out because it is the first network to tackle the semantic segmentation problem from a completely new angle. Previous neural network-based image semantic segmentation networks used image patches centered on the pixels to be classified to predict the label of the center pixel, typically constructed using the CNN + FC strategy. This approach clearly fails to utilize the global contextual information of the image and has a very low per-pixel inference speed; in contrast, the FCN network discards the fully connected layer (FC) and constructs the network entirely using convolutional layers. By employing transposed convolution and feature fusion from different layers, the network outputs a prediction mask directly from the input image, significantly improving both efficiency and accuracy.
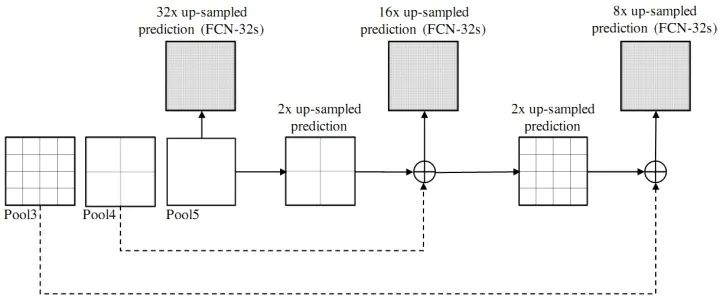
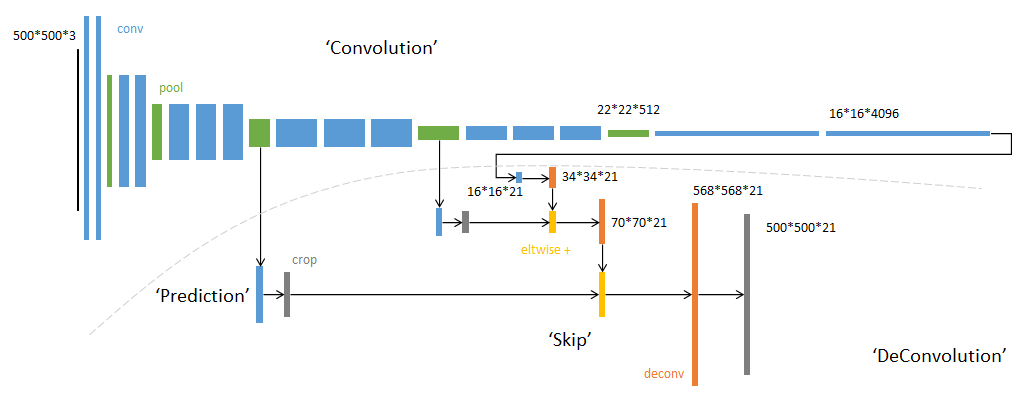
Illustration of Feature Fusion from Different Layers in FCNInnovations: Fully Convolutional Network (without FC layer); Transposed Convolution (Deconvolution); Skip Connections (Addition) of Feature Maps from Different Layers.1.2 Encoder-Decoder Structure
- SegNet has a similar approach to the FCN network. The encoder part uses the first 13 layers of VGG16 convolution, while the difference lies in how the decoder part performs upsampling. FCN achieves upsampling results by adding the results from the deconvolution of the feature maps to the corresponding size feature maps from the encoder; whereas SegNet uses the max-pooling indices from the encoder part for upsampling in the decoder (as described in the original text: the decoder upsamples the lower resolution input feature maps. Specifically, the decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling.).
Innovations: Encoder-Decoder Structure; Pooling Indices.
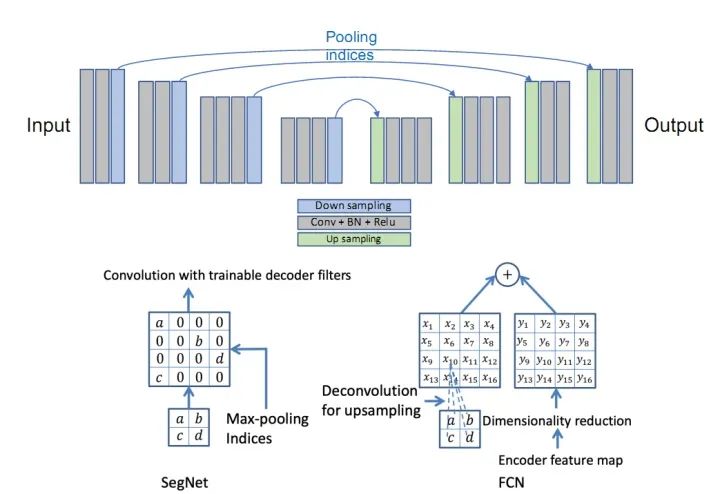
SegNet Network
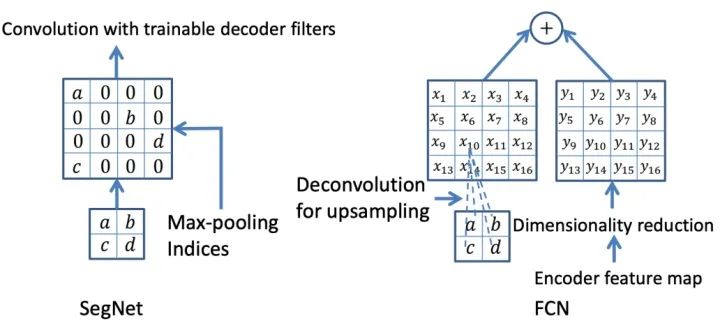
Comparison of Upsampling Methods Between SegNet and FCN
- The U-Net network was initially designed for biomedical images, but due to its outstanding performance, U-Net and its variants are now widely used across various subfields of computer vision. The U-Net network consists of U channels and skip connections, where the U channel is similar to the encoder-decoder structure of SegNet, with the encoding part (contracting path) performing feature extraction and capturing contextual information, while the decoding part (expanding path) uses the decoded feature maps to predict pixel labels. The skip connections improve model accuracy and address the vanishing gradient problem. Notably, the skip connection feature maps are concatenated with the upsampled feature maps, rather than added (unlike FCN).
Innovations: U-shaped Structure; Skip Connections.
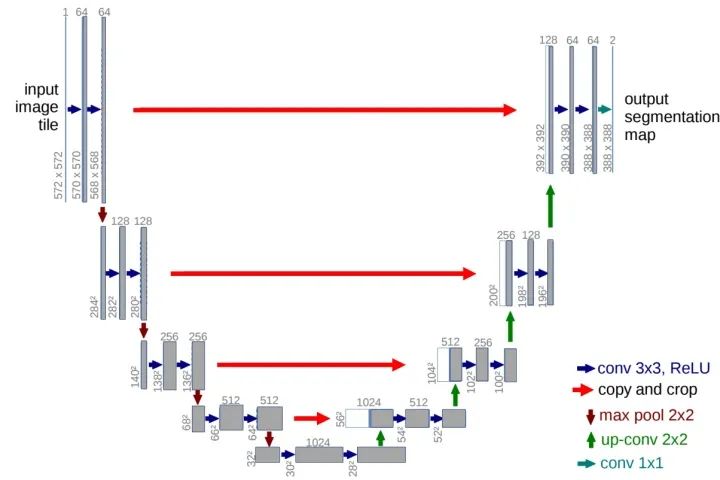
U-Net Network
- The V-Net network structure is similar to U-Net, but this architecture adds skip connections and replaces 2D operations with 3D operations to handle volumetric images. It is also optimized for commonly used segmentation metrics (such as Dice).
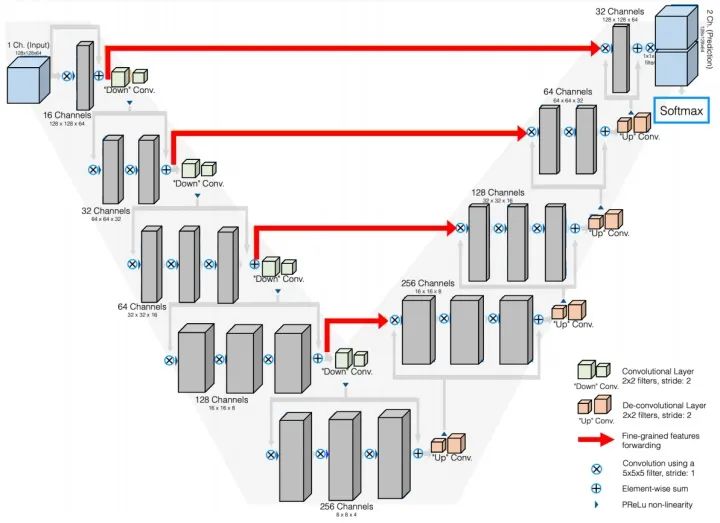
V-Net NetworkInnovations: Equivalent to a 3D version of the U-Net network.
- FC-DenseNet (One Hundred Layers Tiramisu Network) (paper title: The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation) is a network structure composed of dense connection blocks (Dense Block) and U-Net architecture. The simplest version of this network consists of two downsampling paths and two upsampling paths. It also contains two horizontal skip connections that concatenate the feature maps from the downsampling path with the corresponding feature maps in the upsampling path. The connection modes in the upsampling and downsampling paths are not the same: in the downsampling path, each dense block has a skip concatenation path, leading to linear growth in the number of feature maps, while there is no such operation in the upsampling path. (To add, this network can be abbreviated as Dense U-Net, but there is a paper called Fully Dense UNet for 2D Sparse Photoacoustic Tomography Artifact Removal, which is a paper on photoacoustic imaging artifact removal. I have seen many blogs reference illustrations from this paper to discuss semantic segmentation, which is entirely unrelated.)
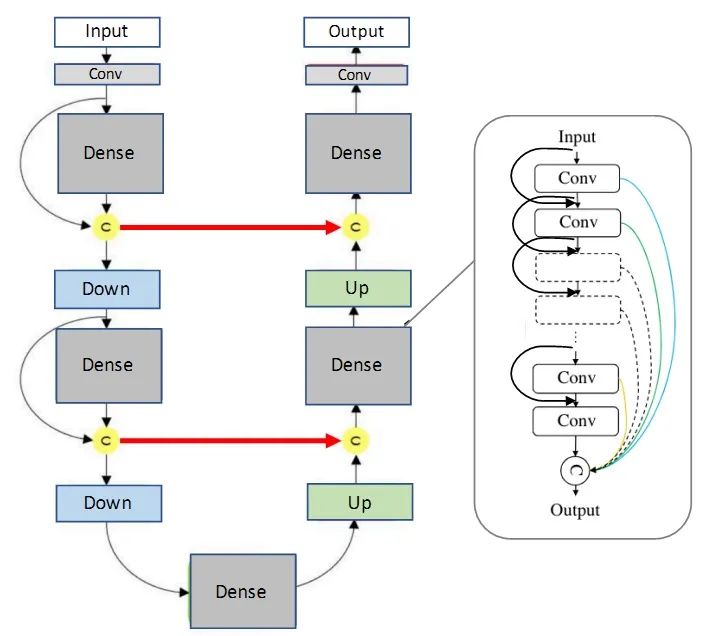
FC-DenseNet (One Hundred Layers Tiramisu Network)Innovations: Fusion of DenseNet and U-Net networks (from the perspective of information exchange, dense connections are indeed more powerful than residual structures).
- The DeepLab series networks are improved versions proposed based on the encoder-decoder structure. In 2018, DeepLabV3+ achieved state-of-the-art performance on the VOC2012 and Cityscapes datasets. The DeepLab series consists of four papers: V1, V2, V3, and V3+. Here are some brief summaries of the core content of each paper:
1) DeepLabV1: Combines Convolutional Neural Networks and Probabilistic Graph Models: CNN + CRF, improving segmentation localization accuracy;

2) DeepLabV2: ASPP (Atrous Spatial Pyramid Pooling); CNN + CRF.
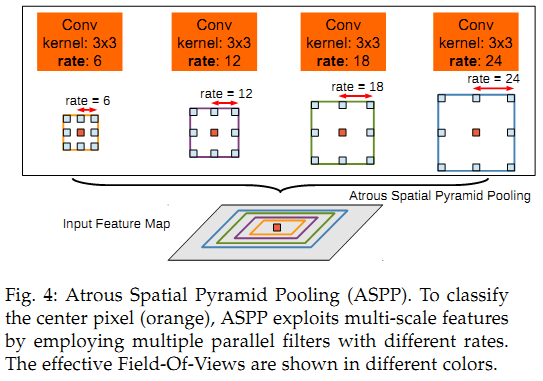
3) DeepLabV3: Improved ASPP, added 1×1 convolution and global average pooling; compared the effects of cascading and parallel dilated convolutions.
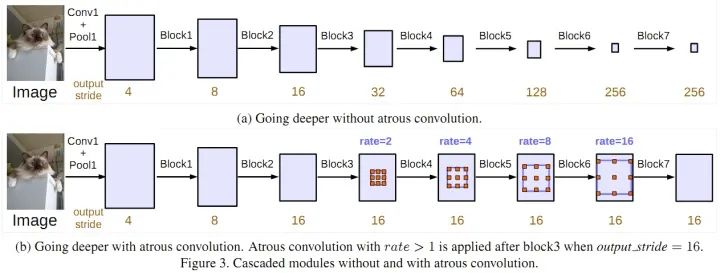
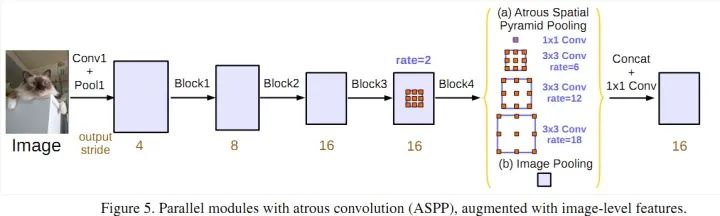
Parallel Dilated Convolution (ASPP)4) DeepLabV3+: Incorporates the encoder-decoder architecture, adding a decoder module to extend DeepLabV3; applies depthwise separable convolutions in both the ASPP and decoder modules; uses an improved Xception as the backbone.
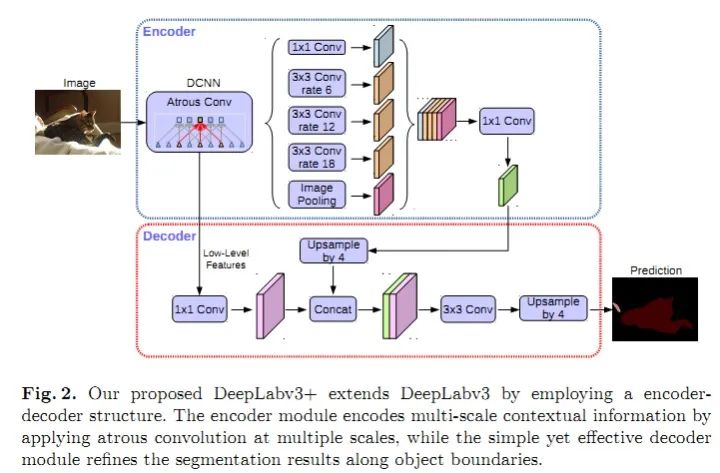
DeepLabV3+Overall, the core contributions of the DeepLab series are: dilated convolutions; ASPP; CNN + CRF (only V1 and V2 use CRF; it seems that V3 and V3+ solve the problem of blurred segmentation boundaries through deep networks, achieving better results than adding CRF).
- PSPNet (Pyramid Scene Parsing Network) enhances the network’s ability to utilize global contextual information by aggregating contextual information from different regions. In SPPNet, the different levels of feature maps generated by pyramid pooling are ultimately flattened and concatenated, then fed into a fully connected layer for classification, eliminating the requirement for CNN to have a fixed input size for image classification. In PSPNet, the strategy used is: pooling-conv-upsampling, followed by concatenation to obtain feature maps for label prediction.
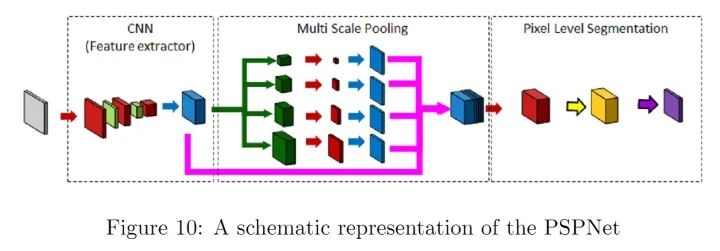
PSPNet NetworkInnovations: Multi-scale pooling, better utilizing global image-level prior knowledge to understand complex scenes.
- RefineNet refines intermediate activation maps and hierarchically connects them to combine multi-scale activations while preventing sharpness loss. Each Refine module consists of three main modules: Residual Convolution Units (RCU), Multi-Resolution Fusion (MRF), and Chain Residual Pooling (CRP). The overall structure is somewhat similar to U-Net, but a new combination method is designed at the skip connections (not simply concatenating). Personally, I believe this structure is very suitable as a design idea for one’s own network, as it can incorporate many CNN modules used in other CV problems, and using U-Net as the overall framework will not yield poor results.
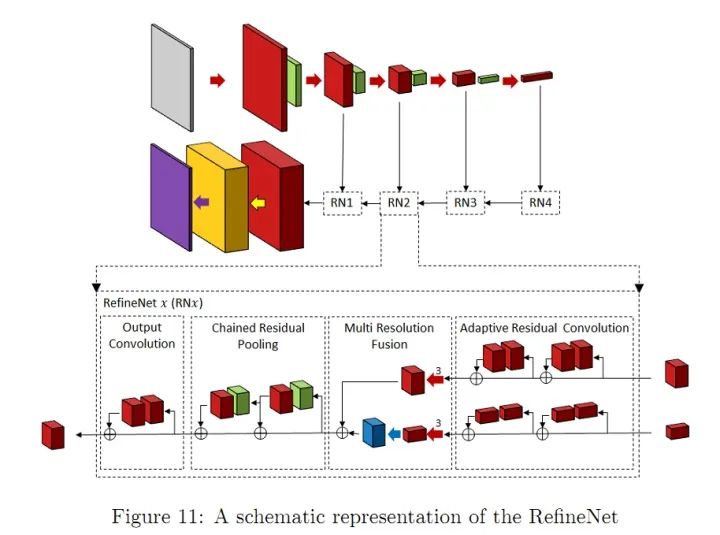
RefineNet NetworkInnovations:Refine Module1.3 Reducing Computational Complexity in Network Structures Many works are also dedicated to reducing the computational complexity of semantic segmentation networks. Some methods for simplifying deep network structures include: tensor decomposition; channel/network pruning; sparsification of connections. There are also some methods that use NAS (Neural Architecture Search) to replace manual design to search for modules or entire network structures. However, the GPU resources required for AutoDL may deter a large number of people. Therefore, some people have used random search to explore smaller ASPP modules and then build the entire network model based on these smaller modules.Lightweight network design is a consensus in the industry, as it is impossible to equip every machine on mobile deployments with a 2080ti. Additionally, issues such as power consumption and storage will also limit the model’s promotion and application. However, if 5G can be popularized, all data could be processed in the cloud, which would be very interesting. Of course, in the short term (ten years), it is uncertain whether comprehensive 5G deployment is feasible.1.4 Attention Mechanism-Based Network StructuresThe attention mechanism can be defined as: using subsequent layer/feature map information to select and locate the most decisive (or salient) parts of the input feature map. Simply put, it can be viewed as a way to weight feature maps (the weights are computed by the network). Depending on how the weights are applied, it can be divided into channel attention mechanism (CA) and spatial attention mechanism (PA). The Feature Pyramid Attention (FPA) network is a semantic segmentation network based on the attention mechanism that combines the attention mechanism and spatial pyramid to extract precise features for pixel-level labeling, without using dilated convolutions or manually designed decoder networks.1.5 Adversarial Learning-Based Network StructuresIn 2014, Goodfellow et al. proposed an adversarial method to learn deep generative models, where Generative Adversarial Networks (GANs) require training two models simultaneously: a generative model G that captures the data distribution and a discriminative model D that estimates the probability that a sample comes from the training data.● G is a generative network that receives a random noise z (random number) and generates images from this noise.● D is a discriminative network that determines whether an image is “real.” Its input parameter is x (an image), and the output D(x) represents the probability that x is a real image; if it is 1, it means 100% real, while an output of 0 means it is not likely to be a real image.The training procedure for G maximizes the probability that D is incorrect. It can be proven that within any function space of G and D, there exists a unique solution such that G reproduces the training data distribution, while D=0.5. During training, the goal of the generative network G is to generate realistic images to deceive the discriminative network D, while D’s goal is to distinguish between fake images generated by G and real images. Thus, G and D form a dynamic “game process,” and the final equilibrium point is the Nash equilibrium point. When G and D are defined by neural networks, the entire system can be trained using backpropagation.
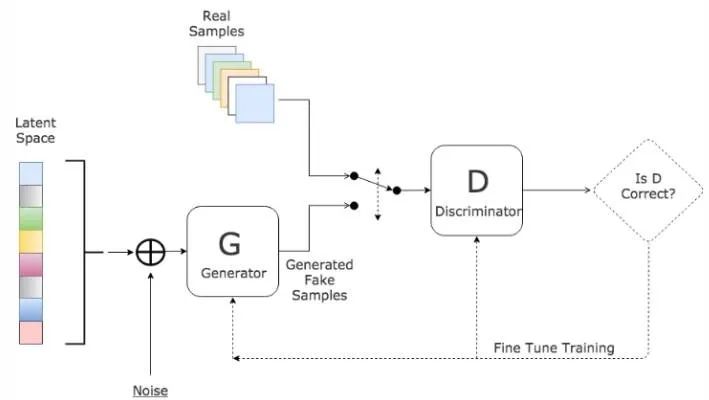
Illustration of GANs Network StructureInspired by GANs, Luc et al. trained a semantic segmentation network (G) and an adversarial network (D) to distinguish between segmentation maps from ground truth or the semantic segmentation network (G). G and D continuously learn through adversarial training, and their loss functions are defined as:
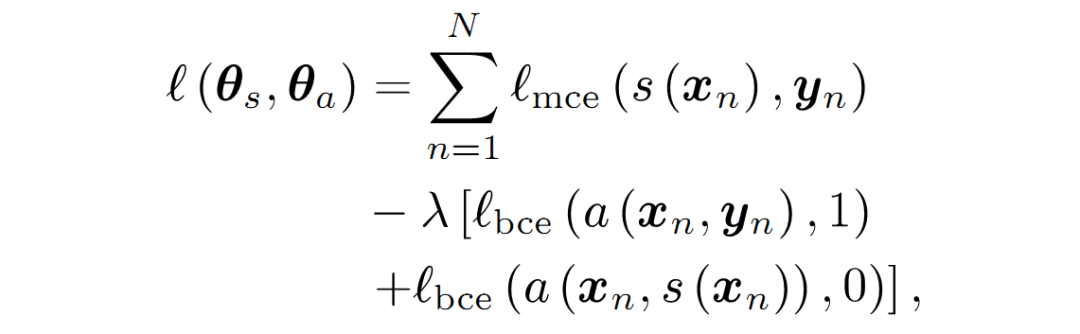
GANs Loss Function
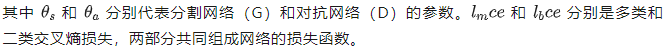
Reviewing the original GAN loss function:The loss function of GANs reflects a zero-sum game concept, and the original GAN loss function is as follows:
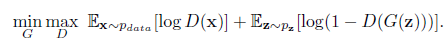
The loss is computed at the output of D (the discriminator), where D’s output is typically a fake/true judgment, so overall it can be considered that it adopts a binary cross-entropy function. From the form of the GAN loss function, training is divided into two parts:First, the maxD part, as training typically begins by keeping G (the generator) unchanged while training D. D’s training objective is to correctly distinguish fake/true; if we represent true/fake with 1/0, then for the first term E, since the input is sampled from real data, we expect D(x) to approach 1, making the first term larger. Similarly, for the second term E, since the input is sampled from G’s generated data, we expect D(G(z)) to approach 0, making the second term larger. Thus, this part aims to maximize D, hence the meaning of maxD. This part only updates D’s parameters.
The second part keeps D unchanged (no parameter updates) and trains G, where only the second term E is relevant. The key is that we want to deceive D, so we set the label to 1 (we know it is fake, hence the term deceive), hoping that D(G(z)) outputs close to 1, making this term smaller, which is minG. Of course, the discriminator is not so easily fooled, so at this point, the discriminator produces a significant error, which will update G, making G better; this time it didn’t fool you, so it has to work harder next time (source: https://www.cnblogs.com/walter-xh/p/10051634.html). At this point, only G’s parameters are updated.
From another perspective, GANs can be seen as a special loss function (constructed by neural networks, unlike traditional L1, L2, cross-entropy, etc.).Moreover, GANs have a unique training method and face issues such as gradient vanishing and mode collapse (there seem to be ways to address this), but its design concept is indeed a great invention of the deep learning era.1.6 SummaryMost deep learning-based image semantic segmentation models follow the encoder-decoder architecture, such as U-Net. Recent research findings indicate that dilated convolutions and feature pyramid pooling can improve the performance of U-Net style networks. In section 2, we summarize how to apply these methods and their variants to medical image segmentation.
2. Application of Network Structure Innovations in Medical Image Segmentation
This section introduces some research results on the application of network structure innovations in 2D/3D medical image segmentation.2.1 Segmentation Methods Based on Model CompressionTo achieve real-time processing of high-resolution 2D/3D medical images (such as CT, MRI, and histopathological images), researchers have proposed various model compression methods. Weng et al. applied NAS technology to the U-Net network, resulting in a compact network with better organ/tumor segmentation performance on CT, MRI, and ultrasound images. Brugger redesigned the U-Net architecture using group normalization and Leaky-ReLU to enhance the storage efficiency of the network for 3D medical image segmentation. Other methods designed modules with fewer parameters for dilated convolutions. Additional model compression methods include weight quantization (16-bit, 8-bit, binary quantization), distillation, pruning, etc.2.2 Segmentation Methods Based on Encoder-Decoder StructureDrozdal proposed a method that applies a simple CNN to normalize the raw input images before sending them into the segmentation network, improving segmentation accuracy for single-cell microscopy images, liver CT, and prostate MRI. Gu proposed a method that utilizes dilated convolutions in the backbone network to retain contextual information. Vorontsov proposed a graph-to-graph network framework that converts images with ROI into images without ROI (for example, converting images with tumors into healthy images without tumors) and then adds the tumors removed by the model to the new healthy images to obtain detailed structures of the objects. Zhou et al. proposed a method for rewiring skip connections in the U-Net network and tested its performance in tasks such as nodule segmentation in chest low-dose CT scans, nucleus segmentation in microscopy images, liver segmentation in abdominal CT scans, and polyp segmentation in colonoscopy videos. Goyal applied DeepLabV3 to dermoscopic color image segmentation to extract skin lesion areas.2.3 Segmentation Methods Based on Attention MechanismNie proposed an attention model that can segment the prostate more accurately compared to baseline models (V-Net and FCN). SinHa proposed a network based on a multi-layer attention mechanism for abdominal organ segmentation in MRI images. Qin et al. proposed a dilated convolution module to retain more details in 3D medical images. There are many other papers on attention mechanism-based segmentation.2.4 Adversarial Learning-Based Segmentation NetworksKhosravan proposed an adversarial training network for pancreatic segmentation from CT scans. Son used Generative Adversarial Networks for retinal image segmentation. Xue utilized fully convolutional networks as segmentation networks within the generative adversarial framework to segment brain tumors from MRI images. There are other successful applications of GANs to medical image segmentation problems, which will not be listed one by one.2.5 RNN-Based Segmentation ModelsRecurrent Neural Networks (RNNs) are primarily used for sequential data processing, and Long Short-Term Memory (LSTM) networks are an improved version of RNNs that maintain gradient flow over long periods by introducing self-loops. In the field of medical image analysis, RNNs are used to model temporal dependencies in image sequences. Bin et al. proposed an image sequence segmentation algorithm that combines fully convolutional neural networks with RNNs, incorporating information from the temporal dimension into the segmentation task. Gao et al. modeled the temporal relationships in brain MRI slice sequences using CNNs and LSTMs to improve segmentation performance in 4D images. Li et al. first obtained initial segmentation probability maps using U-Net, and then used LSTM for pancreatic segmentation from 3D CT images, improving segmentation performance. There are many other papers that utilize RNNs for medical image segmentation that will not be introduced one by one.2.6 SummaryThis section mainly discusses the application of segmentation algorithms in medical image segmentation, so there are not many innovations. The focus remains on adapting to the characteristics of different data formats (CT or RGB, pixel ranges, image resolutions, etc.) and different anatomical data characteristics (noise, object shapes, etc.), requiring classic networks to be improved for different data to better accomplish segmentation tasks. Although deep learning is a black box, the overall model design still follows certain principles; strategies to solve specific problems and the issues they cause can be adjusted based on specific segmentation challenges to achieve optimal segmentation performance.References:
1. Deep Semantic Segmentation of Natural and Medical Images: A Review
2. NAS-Unet: Neural architecture search for medical image segmentation. IEEE Access, 7:44247–44257, 2019.
3. Boosting segmentation with weak supervision from image-to-image translation. arXiv preprint arXiv:1904.01636, 2019.
4. Multi-scale guided attention for medical image segmentation. arXiv preprint arXiv:1906.02849, 2019.
5. SegAN: Adversarial network with multi-scale L1 loss for medical image segmentation.
6. Fully convolutional structured LSTM networks for joint 4D medical image segmentation. In 2018 IEEE.
7. https://www.cnblogs.com/walter-xh/p/10051634.html
Editor: Yu TengkaiProofread: Lin Yilin