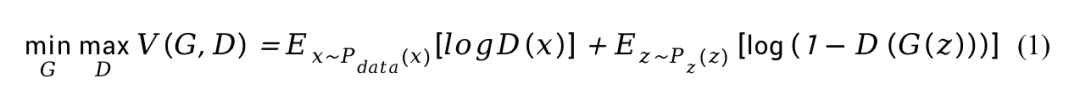
The “Outcome Overview” series of articles aims to disseminate important results from conferences and journals in the field of image graphics, allowing readers to quickly understand relevant academic dynamics in their native language through short articles. We welcome your attention and submissions~
◆ ◆ ◆ ◆
GAN Review: Models and Medical Image Fusion Applications
Zhou Tao , Li Qi , Lu Huiling , Cheng Qianru , Zhang Xiangxiang
School of Computer Science and Engineering, Northern Minzu University, Key Laboratory of Intelligent Processing of Images and Graphics, National Ethnic Affairs Commission, Northern Minzu University, Ningxia Medical University, School of Science
*Corresponding Author: Li Qi
◆ ◆ ◆ ◆
Generative Adversarial Networks (GANs) are a hot research topic in deep generative models and have been widely applied in the field of medical image fusion. This article summarizes GAN models from four aspects: First, it explains the basic principles of GANs from the perspectives of the basic model and training process; Second, it categorizes different GAN models into three directions (probability distribution distance, overall network architecture, neural network structure), summarizing typical models in recent years from eight dimensions: methods based on f-divergence, IPM-based methods, single-generator dual-discriminator GANs, multi-generator single-discriminator GANs, multi-generator multi-discriminator GANs, conditional constraint GANs, convolutional neural network structure GANs, and autoencoder neural network structure GANs; Third, it explores the advantages and applications of GANs in the field of medical image fusion from three aspects; Fourth, it discusses the main challenges faced by GAN models and GAN models in the field of medical image fusion and provides an outlook on future development directions. This article systematically summarizes various GAN models and their advantages and challenges in the field of medical image fusion, which is of great significance for future research on GANs.
Generative models have achieved great success in applications such as image processing, density estimation, and style transfer, but with the significant increase in the number and dimensions of observable samples, they have gradually been replaced by deep generative models with multiple hidden layers. Deep generative models have been successfully applied in computer vision, natural language processing, image generation, and semi-supervised learning, providing a good paradigm for unsupervised learning. Among them, the Generative Adversarial Network (GAN) proposed by Goodfellow et al. in 2014 is currently a hot research topic in deep generative models. This model can implicitly estimate the density function of data distribution and can use the powerful fitting ability of neural networks to generate samples that conform to the real data distribution through adversarial training. Given the excellent performance of GANs, they have gained widespread attention from researchers in the field of medical image fusion. This article analyzes and discusses GAN models and their advantages and applications in the field of medical image fusion, with the overall structure shown in Figure 1.
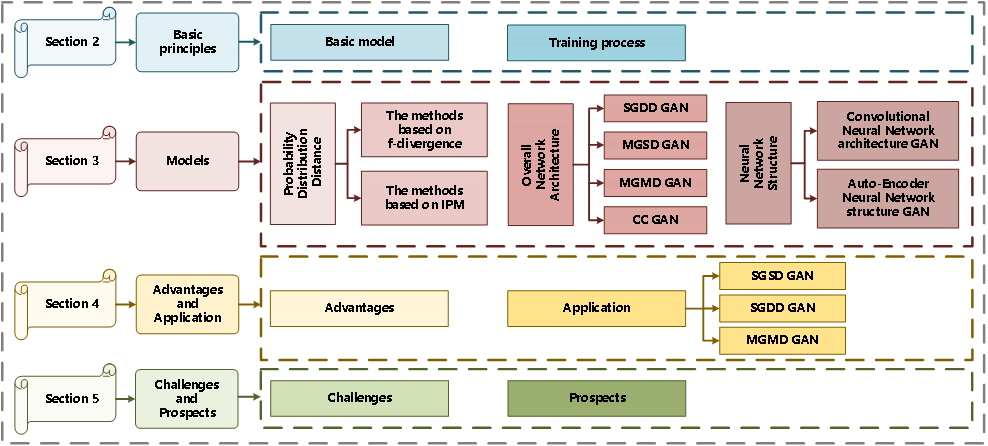
Fig 1 An overview of the structure of this paper from Section 2 to 5. SGDD GAN expresses Single-Generator and Dual-Discriminators GAN; MGSD GAN expresses Multi-Generators and Single-Discriminator GAN; MGMD GAN expresses Multi-Generators and Multi-Discriminators GAN; CC GAN expresses Conditional Constraint GAN; SGSD GAN expresses Single-Generator and Single-Discriminator GAN; SGDD GAN expresses Single-Generator and Dual-Discriminators GAN.
Inspired by zero-sum games in game theory, GANs view the generative problem as a game between the generator and the discriminator. The basic model is shown in Figure 2. The basic model is shown in Figure 2.
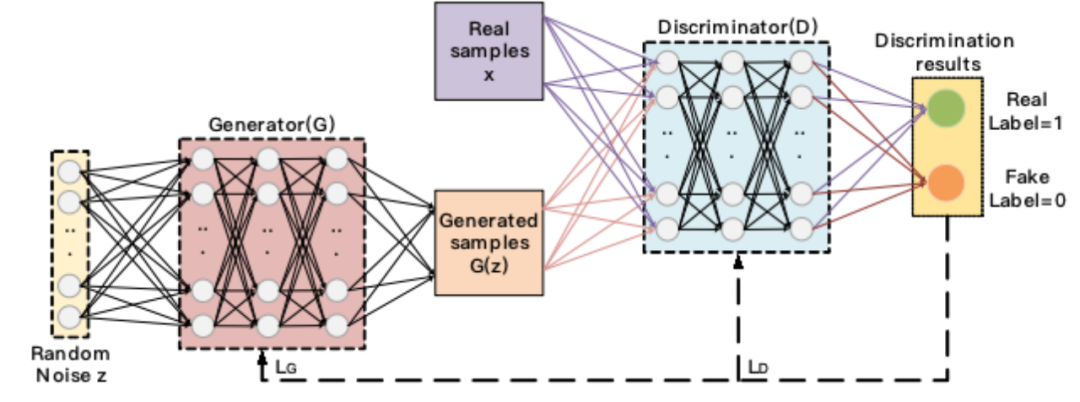 Fig 2 Basic model. expresses the loss function of Generator; expresses the loss function of Discriminator.
Fig 2 Basic model. expresses the loss function of Generator; expresses the loss function of Discriminator.