
This article is authored by Wang Siyu, School of Finance, Zhongnan University of Economics and Law
Edited by: He Jiang
Technical Editor: Wen Heming
Stata and Python Data Analysis
The Crawling Club will hold acustom training on Stata programming techniquesandPython programming techniquesfromAugust 1 to 9, 2023atHenan University (Kaifeng, Henan), with live streaming on online platforms to provide online learning opportunities.Both online and offline training will have a dedicated Q&A team. If you are interested, please click the tweet link“Crawling Club 2023 First Programming Camp Registration is Open!”orclick the end of the articleto read the original textfor course details and registration methods!

Introduction

NLTK (Natural Language Toolkit) is a Python library for natural language processing (NLP). It provides a range of tools and resources for processing human language data, including text preprocessing, language models, language analysis, classification, tagging, corpora, and language datasets.

Installation

pip install nltk
Next, you can use the<span>nltk.download()</span>function to download the required corpora and model files. If an error occurs during execution, you can visit https://github.com/nltk/nltk_data to download the relevant data, by downloading the files in the packages folder and copying all subfolders under the packages folder to the path shown in the image below to resolve the issue.


Specific Applications

Text Processing
Using the functions and tools provided by NLTK, text preprocessing can be performed, mainly including tokenization, stopword removal, and part-of-speech tagging. Below, we will detail the workflow of text processing using NLTK tools.
First, import the modules and functions, and input the text to be processed into Python:
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk import pos_tag # Import modules and functions
text = "I really enjoy the movie called Lost In The Stars. It is amazing."
Next, process the imported text and view the preprocessed text data and results:
tokens = word_tokenize(text) # Tokenization
print(tokens)
stop_words = set(stopwords.words('english')) # Remove stopwords
tokens = [token for token in tokens if token.casefold() not in stop_words]
tags = pos_tag(tokens) # Part-of-speech tagging
print(tags)

Here, RB represents adverb, VB represents verb base form, NN represents noun, VBN represents verb past participle, NNP represents proper noun (singular), and . represents punctuation.
After basic text processing, NLTK can be used for noun phrase information extraction. First, we define the grammar rules:
from nltk import RegexpParser
grammar = r"""
NP: {<dt>?<jj>*<nn.*>+}
""" # Define grammar rules
</nn.*></jj></dt>Here,<span><dt></dt></span>represents determiners,<span><jj></jj></span>represents adjectives, and<span><nn.*></nn.*></span>represents any type of noun. This rule indicates that a noun phrase consists of an optional determiner, any number of adjectives, and a noun.
Next, we create a regular expression chunker, use it to parse the text, and combine them into a string as the extracted noun phrases:
chunk_parser = RegexpParser(grammar)
tree = chunk_parser.parse(tags)
noun_phrases = []
for subtree in tree.subtrees():
if subtree.label() == 'NP':
np = ' '.join([word for word, tag in subtree.leaves()])
noun_phrases.append(np)
print("Extracted noun phrases:", noun_phrases)
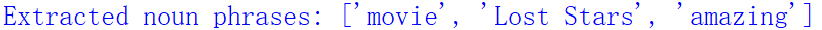
Finally, the extracted noun phrases are “movie”, “Lost Stars”, and “amazing”.
Sentiment Analysis
NLTK can also be used for sentiment analysis of text. First, import the NLTK library and sentiment lexicon in the Python code, and use the NLTK-provided sentiment analyzer<span>SentimentIntensityAnalyzer</span>to create a sentiment analysis object:
from nltk.sentiment.vader import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
Next, perform sentiment analysis on the text using the sentiment analyzer’s<span>polarity_scores()</span>method and view the sentiment analysis results:
scores = analyzer.polarity_scores(text)
print(scores)
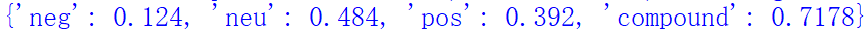
Here,<span>'neg'</span>represents the score for negative sentiment,<span>'neu'</span>represents the score for neutral sentiment,<span>'pos'</span>represents the score for positive sentiment, and<span>'compound'</span>represents the overall sentiment score. In this example, the overall sentiment score is 0.7178, indicating that this text is positive.
Natural Language Generation
NLTK also provides some tools and techniques for natural language generation, including rule-based methods, template methods, and machine learning-based methods. Below, we will generate sentences based on a template method, first defining a sentence generation template:
template = "The {adjective}{noun}{verb}{adverb}."
Next, define a function that randomly selects a word from the given vocabulary lists and inserts it into the template to generate a complete sentence:
import random
def generate_sentence(template, adjectives, nouns, verbs, adverbs):
adjective = random.choice(adjectives)
noun = random.choice(nouns)
verb = random.choice(verbs)
adverb = random.choice(adverbs)
sentence = template.format(adjective=adjective, noun=noun, verb=verb, adverb=adverb)
return sentence
Finally, by customizing vocabulary lists and calling the function, we can generate sentences:
adjectives = ["happy", "sad", "angry", "excited", "calm", "crazy", "brave", "shy", "smart", "funny"]
nouns = ["cat", "dog", "book", "computer", "phone", "car", "tree", "house", "city", "music"]
verbs = ["runs", "jumps", "reads", "writes", "talks", "listens", "dances", "learns", "thinks", "dreams"]
adverbs = ["quickly", "slowly", "loudly", "quietly", "happily", "sadly", "angrily", "excitedly", "calmly", "crazily"]
sentence = generate_sentence(template, adjectives, nouns, verbs, adverbs)
print(sentence)
This way, a random sentence is generated using a simple template and some vocabulary lists. The generated result is as follows:
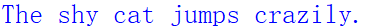
Above are some usage methods for NLTK, come and try it out~

END

Exciting Benefits! In order to better serve the research needs of students, the Crawling Club will continue to provide various indicators required for financial research on the Xiaoetong platform, including top ten shareholders of listed companies, stock price crashes, investment efficiency, financing constraints, corporate tax avoidance, analyst tracking, return on equity, return on assets, the Big Four audits, Tobin’s Q, the first largest shareholder’s shareholding ratio, book-to-market ratio, commonly used control variables for A-share listed companies, and other series of deep-processed data. Based on the data disclosed by various exchanges, we will use Stata to achieve real-time data updates while continuously launching more data indicators. We hope to support everyone’s research work with the most cutting-edge data processing technology, the best service quality, and the greatest sincerity! For related data links, please visit:(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)or scan the QR code:

If we receive more than 1000 yuan in cumulative rewards for our tweets, we can issue you an invoice, with the invoice category as “consultation fee”. We are committed to doing our best and appreciate your support!
XML Easily read: Discover data treasures with Python
Crawling Club Launches cnstata.com.cn
Markdown: Making Mathematical Formula Input More Convenient!
What’s new? Quick access to Stata 18
WeChat official account “Stata and Python Data Analysis” shares practical knowledge of data processing with Stata, Python, and other software. Reprints and rewards are welcome. We are a big data processing and analysis team composed of graduate and undergraduate students under the leadership of Professor Li Chuntao.
Wuhan String Data Technology Co., Ltd. has been providing data collection and analysis services to users. If you have such needs, please email [email protected], or directly contact our data platform chief engineer Mr. Si Haitao, phone: 18203668525, WeChat: super4ht. Mr. Si has long been engaged in research at the University of Hong Kong and is currently a doctoral student at a well-known 985 university, responsible for the courses on web crawling technology and regular expressions at the Crawling Club.
In addition, we welcome everyone to actively contribute articles introducing some data processing and analysis techniques related to Stata and Python.
