
Author / Li Xi
0 Introduction
This article organizes previous research on multimodal visual structure learning from a new perspective, focusing on the characteristics and applications of spherical panoramic images.
Spherical images are mostly related to fisheye or 360° panoramic views, containing a wealth of structural knowledge, primarily aimed at applications such as autonomous driving, virtual reality, road monitoring, interior decoration, and more. Here, we hope to effectively model and structure scenes using a very inexpensive and simple expression method.
However, conducting image analysis and applications based on such spherical structures is a very challenging problem. Therefore, in our research on spherical images, we set aside their applications and focus solely on their mathematical reasoning or other problems, hoping to dissect these issues and form an academic problem. Currently, the methods for computing spherical images are more suitable for matrix operations, so tasks like image segmentation and detection are oriented towards these matrix images. For example, the latest applications for image generation also utilize knowledge from rectangular images to generate, transforming them into local spatial perceptions of points, which obey certain physical laws, allowing for reverse decoding; decoding involves propagation and noise reduction processes, thus forming a complete experience. However, analyzing spherical images directly is quite difficult since they do not conform to a regular matrix. Therefore, the usual approach is to unfold the spherical image. During the unfolding process, questions arise regarding the angle of unfolding, the connectivity between them, whether there are geometric properties, and even issues related to density. Due to the density at the center of the sphere, such as a higher density near the equator and a lower density at the poles, the images generated from unfolding the sphere become extremely uneven in density, making it very challenging for AI algorithms to handle.
Thus, how to conduct deep learning aimed at applications and prospects is a very interesting application technology.
During our research process, we find that the images we observe are either natural images or artificial images. For instance, after watching the process of food processing, we remember it; subsequently, knowledge is generated, and ultimately, we can create “delicious dishes.” Humans have formed a processing chain and sequence in their brains through this process, culminating in human cognition. Our perception of images is essentially oriented towards planar images. The so-called image perception today is based on planar image perception, which has significant limitations. For example, our resolution requirements of 4K, 8K, etc., are very high, but they do not reflect true perception, as the human eye’s retina is round; therefore, perception is absolutely not planar.
1 Research Work on Spherical Images
1.1 SGAT4PASS: Spherical Geometry Perception Transformer for Panoramic Semantic Segmentation
The spherical geometry perception transformer for panoramic semantic segmentation establishes a transformer image segmentation on the sphere using geometric knowledge (Li et al., 2023). The most challenging issue here is how to encode the geometric structure into a deep network? The spherical image shown in Figure 1 is a distorted, irregular grid, which can be handled using a transformer. However, it is an ‘s’ structure, not a simple patch or natural source AIP structure. Thus, when unfolded, two parallel small blue boxes indicated in Figure 1 appear, while in reality, they are on the same sphere. This situation arises because the unfolding method disrupts the original geometric structure, causing significant distortion and degrading image quality.
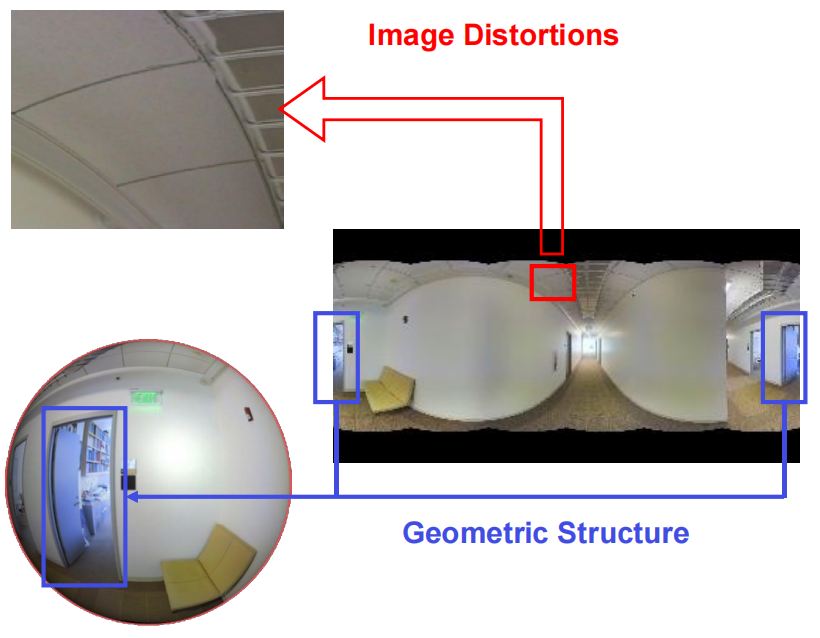
Figure 1 Unfolded Grid of Spherical Image
To address the above issues, we modeled and proposed a framework as shown in Figure 2, approaching it from data level, patch level, and loss level. First, SGA image projection. Since the sphere has three dimensions: α, β, and γ, we perform different rotations along these three dimensions, followed by different data augmentations. After spherical geometric augmentation, we use the image for segmentation, allowing it to perceive the entire variation, indicating that knowledge has been learned. Second, we increase symmetry constraints. Since the sphere, when cut along any meridian at any angle, exhibits symmetry on both sides. Symmetry reflects the direct variation of the left and right halves of the sphere when cut along the meridian, which is the knowledge of image variation Δ. Δ represents a symmetric relationship; if symmetric, it reflects structural changes. Therefore, we hope to model using symmetry knowledge. Third, pixel density, which we aim to adjust during the unfolding of the sphere along the red and blue lines shown in the lower right of Figure 2 (the red line area has the most pixels, while the blue line area has fewer). We utilize the variation in pixel density to weight the pixels, ultimately re-weighting them. As knowledge acquired is less, the pixels at the front are fewer, while those at the back are more, leading to an imbalance. We hope to correct this by re-weighting according to the latitude circumference.
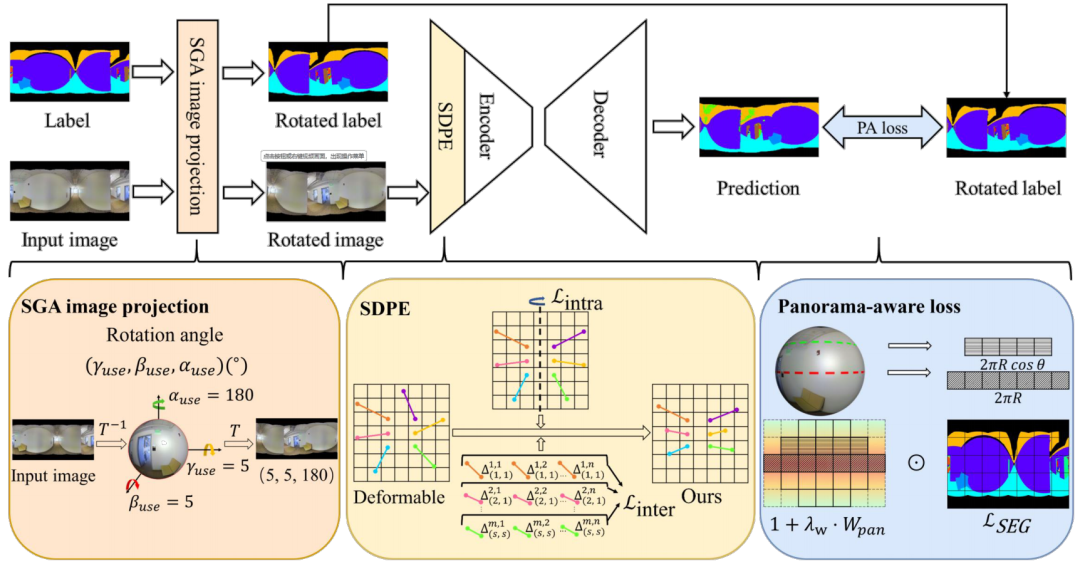
Figure 2 Framework
The results shown in Table 1 and Figure 3 indicate that through the above simple operations, the proposed method can quickly improve mIoU performance and PAcc, as well as its performance stability.
Table 1 Performance Comparison with SOTA

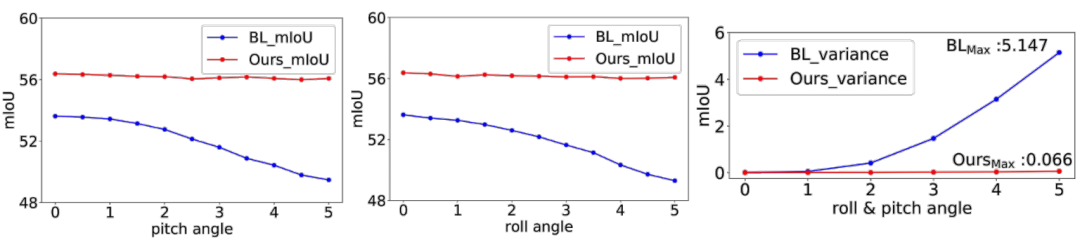
Figure 3 Performance Stability
Here, we utilize geometric structure knowledge to produce some qualitative results. For instance, from the original image shown in Figure 4, we can see a sofa and a door, where the floor is labeled and the door is cut in half. Because image segmentation emphasizes the receptive field, if we use an image segmentation algorithm, the receptive field of the door will not connect, thus leading to incorrect segmentation. Although the results are similar—being incomplete and messy—we can completely segment the sofa and most of the door because we considered the geometric structure and knew that these two structures are connected, allowing us to topologically complete it and flatten the receptive field to achieve good results. With this result, we can rotate the image arbitrarily, and at a certain degree of rotation, we find that the rotated labels align similarly with the original labels, maintaining a basic assistant, leading to geometric perception recognition. That is, with pitch/yaw/roll angles of 5°/5°/180°, SGAT4PASS achieved better results for semantic classes “door” and “sofa” (see the red dashed boxes in Figure 4).
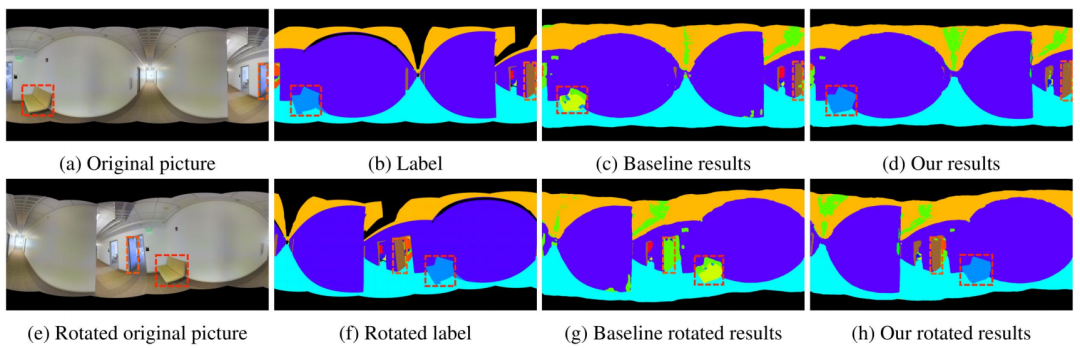
Figure 4 Comparison of SGAT4PASS and Trans4PASS+
1.2 SphereDiffusion: Spherical Geometry Perception Distortion Elastic Diffusion Module
Following the successful results in spherical image segmentation, we continue to delve deeper into spherical image generation.
Spherical panoramic images have two characteristics: one is spherical distortion, where text-object pre-training knowledge cannot be effectively utilized; the difficulty in feature extraction leads to semantic deviation. The second is that existing models lack geometric perception design, making it challenging to learn and utilize spherical geometric features. How to enable models to learn and utilize features to improve the quality of controllable spherical image generation is the specific research we have conducted below.
The process of spherical image generation is the opposite of the above work (see Figure 5). Because the generation task of spherical geometry involves a diffusion model, the noise is removed during the denoising and noising processes, and then noise is added back, continuously training and iterating to infer.In fact, we hope to incorporate geometric spherical features into the spherical model, and through reminders, achieve the final boundaries and knowledge re-utilization, integrating them.In this process, our key idea is to embed this special spherical geometry into the framework for generation.

Figure 5 Spherical Image Generation Process
Figure 6 displays our core denoising framework, which includes several basic operations. The first is the Spherical SimSiam Contrastive Learning Module, which performs spherical rotation operations. Here, we added a shared condition from ControlNet to ensure consistent results. The second operation module is the Deformable Distortion-aware Block (DDaB), which ensures that this interval is deformable. The third deformable module is Spherical Reprojection, where during each generation process, we intentionally rotate to generate a step, rotating the map to a certain degree before performing secondary projection to ensure rotational consistency; then we generate again, maintaining rotational consistency. In this process, diffusion and geometric knowledge are fully connected, yielding very good results.
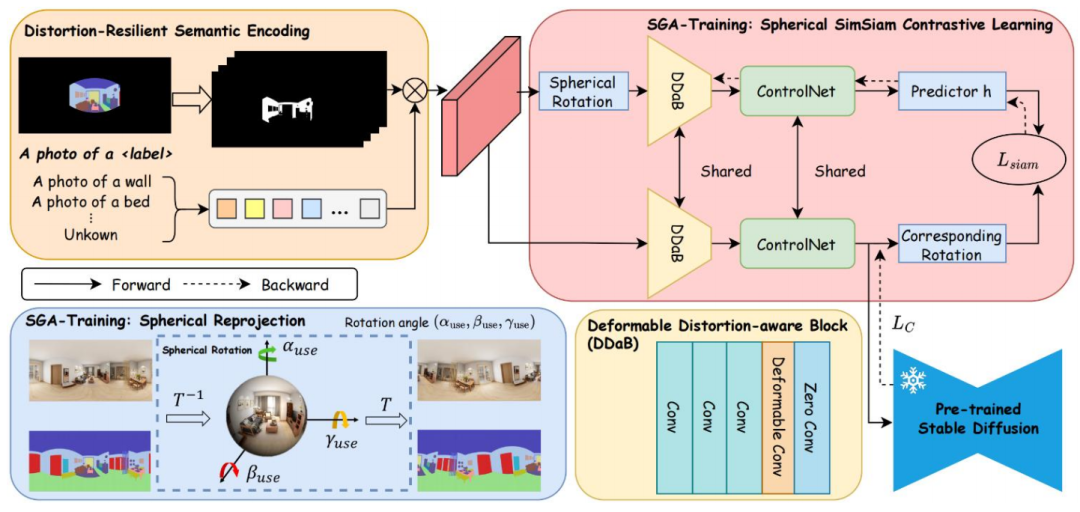
Figure 6 Spherical Image Generation Denoising Process
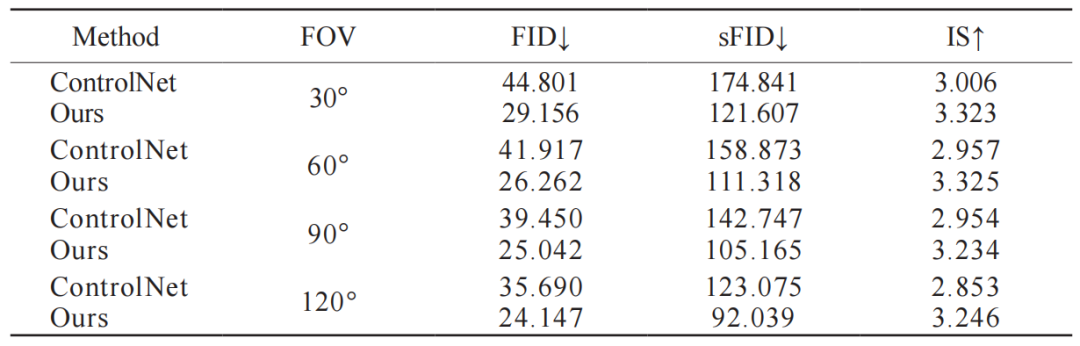
As shown in the results of Table 2, a fair comparison was made using the same hyperparameter settings and training cycles in the standard module. Our method can significantly reduce FID, FIDs, and IS metrics, addressing the special panoramic image generation problem, making it more suitable for applications.
Table 2 Comparison Results with Existing Methods on Structure3D Dataset
The final result we hope for is to have a text prompt, such as “A bedroom with white walls and a pink bed,” which serves as a segmentation text prompt. As shown in Figure 7, the results generated using our method are very good, with good controllability, allowing for the direct generation of panoramic images without the need to generate two-dimensional images directly on a three-dimensional sphere.

Figure 7 Image Generation Results
2 LayoutDiffusion: Controllable Diffusion Model for Layout to Image Generation
With the above achievements, we continue to delve deeper by incorporating planar image generation into the model. The knowledge of layout is a structure in advertising design, and we aim to create a layout on a spherical surface. The knowledge of layout is a controllable bounding box, where after placing its size and position labels, we use it as a controllable map to reverse-generate images. For example, we hope to encode the layout knowledge, such as encoding image, position, and coordinates, and then adding a text prompt to generate the desired decoration design diagram. The outcome is that we design and ultimately generate images, which is our original demand; that is, we hope to decode it. The first decoding involves combining the box’s position, size semantics, target background, and other structures together. The most important result is that we can achieve better controllable generation. The generation we are working on differs from mid-journey in that we hope to achieve editing capabilities; to generate, it requires training a large number of images. For instance, in applications, simply dragging a box can change the specific position and size of the image. We have also created an interface for this, which has been open-sourced.
3 Language Adaptive Inference for Expression Understanding
The previous sections mainly discussed image structural knowledge, such as spherical geometric structural knowledge and image advertising design structural knowledge. We hope to delve into networks, which involves cross-modal aspects, requiring resonance between natural language and structured knowledge of network visual processing. This means identifying different focal points through language prompts while viewing different images. For instance, observing adults and children reveals different visual characteristics. Thus, we aim to achieve language-adaptive visual structures, meaning that different languages yield different prompts, resulting in different feature visual pathways; similar to how human neural circuits operate, the neural circuits activated by different prompts vary, while the overall structure of the network remains the same. We hope to achieve a structure similar to a biomimetic network.
As shown in Figure 8, the language-adaptive dynamic subnet framework utilizes BERT methods for encoding, generating a switch vector like Blockbone and Christmas. The switch acts as a sigma filter. The filter learns how to generate filters; after the filter is completed, what is the network path? Finally, it is modeled into the Transformer, forming a visual pathway, a language feature filter gate variable, and ultimately generating an adaptive subnet; that is, different languages have different sub-networks, establishing such a mapping relationship. Thus, cross-modal refers to the mapping of language features and neural network feature inference structures, where these two mappings can form adaptive control.
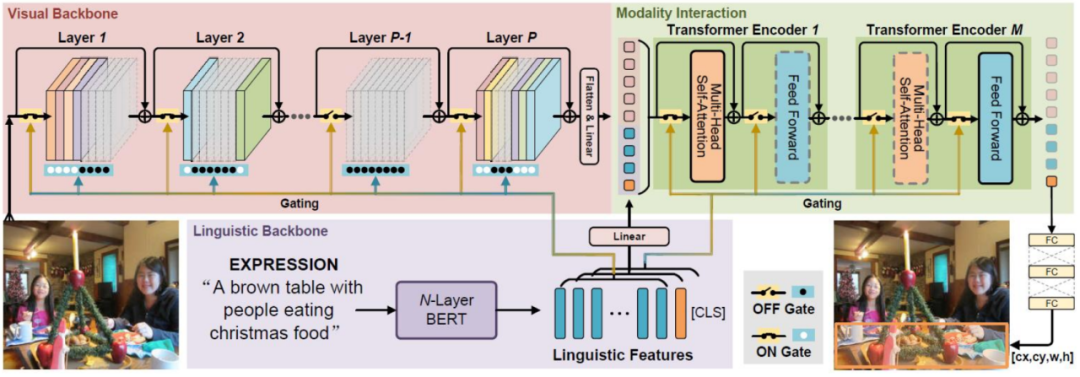
Figure 8 Language Adaptive Dynamic Subnet Framework
Figure 9 illustrates its technical principles, hoping that after generating features, a fully connected layer is produced, and binary features are embedded into the feature map, which is then used to generate the get vector, with Softmax performing normalization to obtain features.
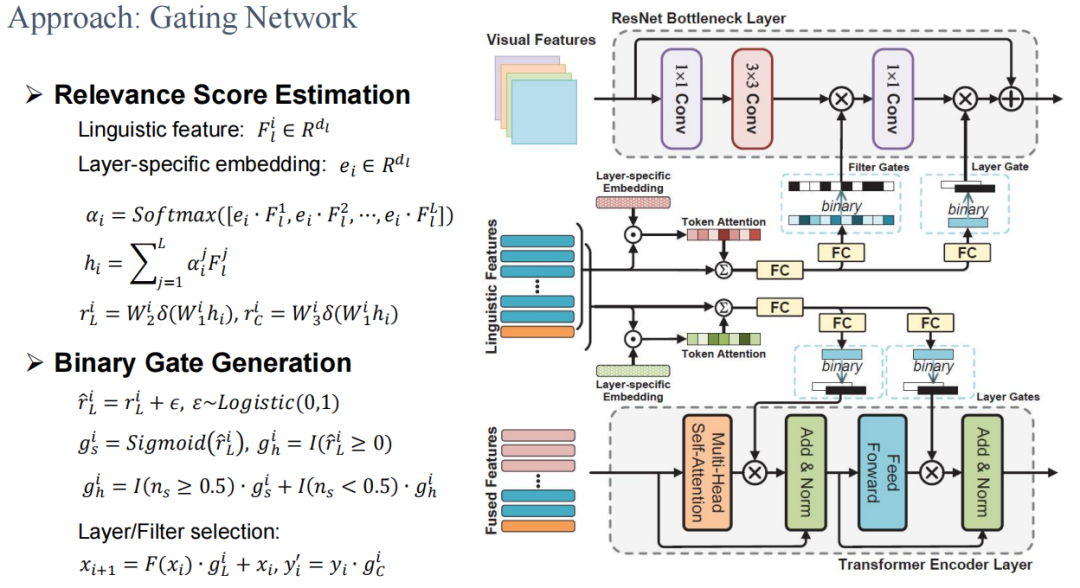
Figure 9 Gated Network Technical Principles
Figure 10 shows the features more intuitively. From the image, it can be seen that the gray bars are skipped and not executed, meaning that different photos will reveal completely different execution paths for the network. Because the computational mapping relationship is closely related to the model and the language, we hope that speaking differently will execute different pathways, thus achieving controllability and dynamic adaptability, which is the core idea.
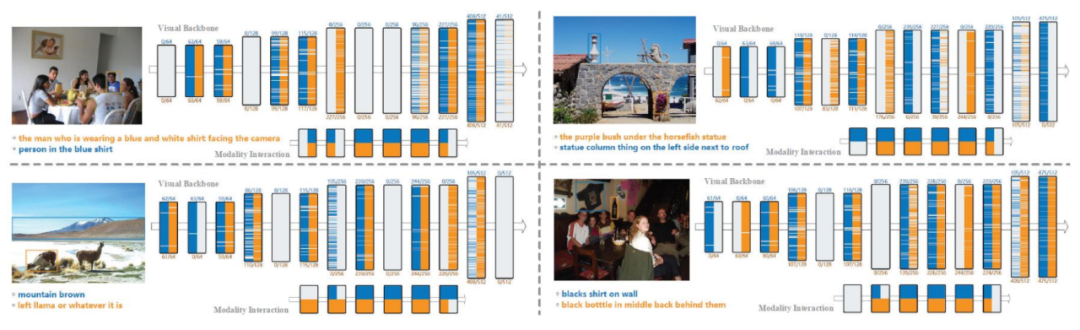
Figure 10 Dynamic Features of REC
4 Language Adaptive Weight Generation for Multitask Visual Foundation
The above mainly introduces the execution module through language modulation. Further, we researched directly generating feature parameters using language, meaning language control, where the controlled variables are key parameters in natural language, as shown in Figure 11 with visual parameters F(l: W, A), F(l: W, A), and F(l: W, A), which are then used for tasks or cross, which is the core idea.
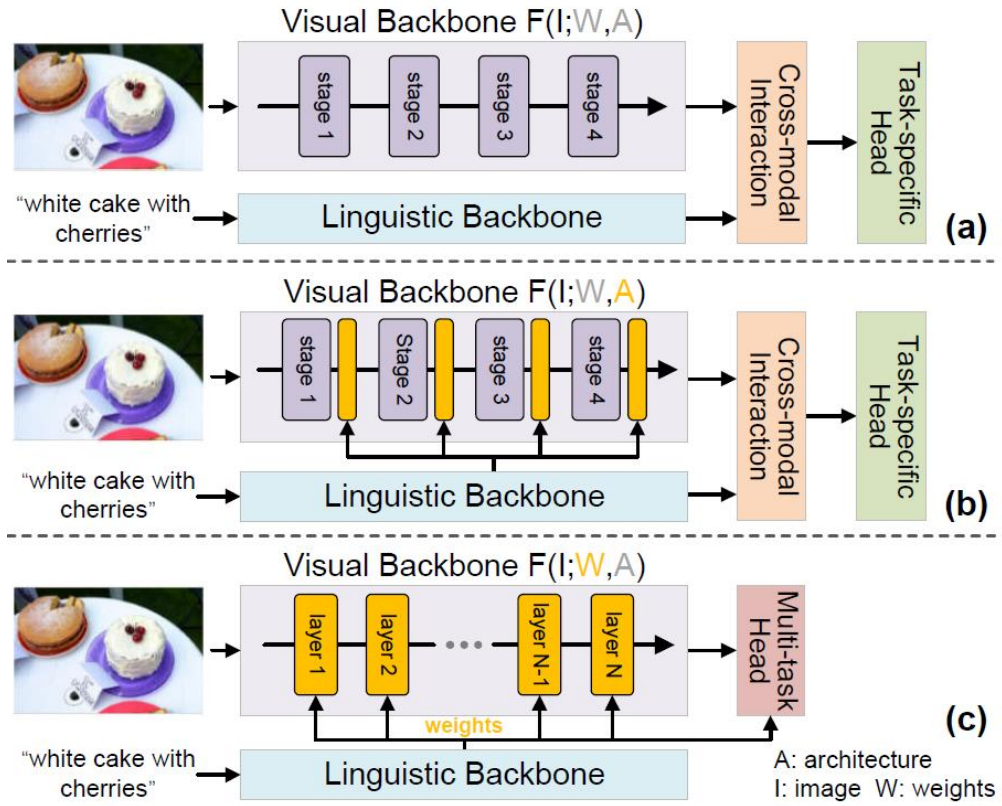
Figure 11 Technical Principles
The technical principle is to structure images using language features, employing external methods to perform query, key, and value, ultimately generating the desired results.
(References omitted)

Li Xi
Vice Dean and Professor at the Shanghai Advanced Research Institute, Zhejiang University, National Outstanding Youth Award recipient, IET Fellow; National-level Leading Talent, Head of the Major Science and Technology Project of the Ministry of Science and Technology – “New Generation Artificial Intelligence”; Principal Investigator of key projects from the National Natural Science Foundation of China and the Ministry of Education’s key planning research projects. He has published over 180 papers in internationally renowned journals and conferences, with several ESI highly cited. He has received the SAIL Award at the World Artificial Intelligence Conference, the International Conference Paper Award, the First Prize of the China Association for Invention’s Entrepreneurship Innovation Award, the First Prize of the Ministry of Education’s Scientific Progress Award, and the Second Prize of the CSIG Natural Science Award, among others.
Selected from “Communications of the Chinese Association for Artificial Intelligence”
2024, Vol. 14, No. 2
Science and Technology Frontiers Special Issue
Scan to Join Us for More Association Resources