
✏️ Author Introduction:
Huang Wei, Senior R&D Engineer at Trend Micro (China)
Preliminary Research
Trend Micro is a global leader in information security software, providing security solutions for software vendors and individual users worldwide. The author of this article is currently responsible for building mobile security apps and developing infrastructure. The workflow involves scraping external APKs (Android application packages) from platforms like Google Play, using Trend Micro’s algorithms to detect virus-laden APKs. Milvus is used for similarity search of virus-laden external APKs in Trend Micro’s APK repository. If a similar virus-laden APK is found, timely notifications about the virus information are sent to relevant enterprises and individual users.
The aforementioned work requires a system that efficiently retrieves similar APKs. Due to the initial small number of APK samples in the project, the team could use SQL in MySQL for APK similarity searches. However, as the number of APK samples dramatically increased, MySQL could not guarantee performance, prompting the team to explore new solutions.
Faiss
In 2017, Facebook released the Faiss algorithm library. Faiss can quickly retrieve similar vectors and offers multiple indexes such as IndexFlatL2, IndexFlatIP, HNSW, IVF, which can solve most similarity search problems.
However, Faiss is merely a basic algorithm library with the following issues: it cannot manage vector data, lacks high availability, has no monitoring means, lacks distributed solutions, and is missing SDKs for various programming languages.
Plugins Developed Based on Faiss and Other Approximate Nearest Neighbor Search (ANN) Algorithm Libraries
Some plugins have been developed in the industry based on approximate nearest neighbor algorithm libraries like Faiss and NMSLIB, such as ES (Elasticsearch) plugins developed using Faiss and NMSLIB as the underlying libraries, as shown in the figure below:
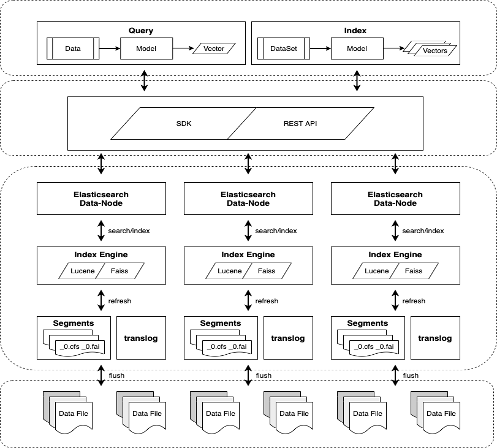
The advantage of such solutions is that there is no need to write an additional set of distributed code. Since the ES plugin is already very mature, users can quickly grasp the DSL provided by ES. One ES instance can retrieve both text and vectors, and it supports scalar field filtering.
Currently, Alibaba, NetEase, and Amazon have adopted such solutions. JD.com has also developed a distributed system called Vearch based on Faiss, but Vearch is still in its infancy and the community is not very active.
The problem with such solutions is that they consume a lot of memory and are not easy to tune for performance. To achieve optimal performance, segment merging is required.
Milvus
Milvus, an open-source vector similarity search engine developed in C++, stands out among many mainstream solutions. The comparison of Milvus with other solutions is shown in the figure below:
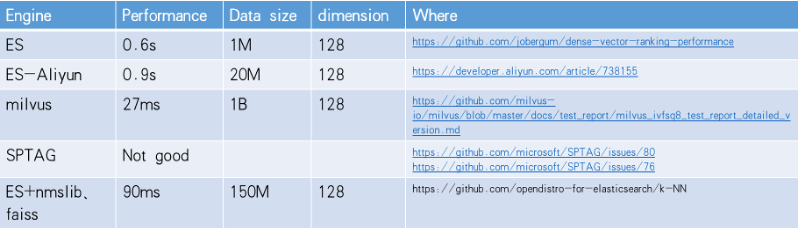
The comparative analysis indicates that Milvus performs well and has the following advantages:
-
Integrates mainstream vector index libraries such as Faiss, NMSLIB, and Annoy.
-
Provides a complete set of simple and intuitive APIs, allowing the selection of different index types for different scenarios.
-
Has relatively mature solutions for high availability, distributed systems, and monitoring.
-
Has a large user base and an active community, with current stars exceeding 5000.
Trend Micro ultimately decided to choose Milvus as the internal vector retrieval component.
Project Background and Architecture Design
Currently, Trend Micro stores tens of millions of APK sample data in MySQL, with daily increments reaching hundreds of thousands. The algorithm team extracts and calculates the Thash feature values from different parts of the APK for similarity retrieval. The team also uses different Sha256 algorithms to treat APKs as binary files, calculating multiple 256-bit long Sha256 hash values based on byte stream hashes to distinguish different APKs. Different APKs have different Sha256 hash values. Each APK’s Thash feature value corresponds to multiple different Sha256 hash values.
In short, the Sha256 hash value is only used to distinguish different APKs, while the Thash feature value is used for similarity retrieval. Similar APKs may produce the same Thash feature value, but have different Sha256 hash values.
Currently, Trend Micro needs to develop a system to retrieve similar Thash feature values and return the multiple Sha256 hash values corresponding to these Thash feature values, ultimately retrieving similar APKs. In this process, Trend Micro needs to develop functionality for storing and retrieving Thash feature values. With the support of Milvus, the Trend Micro team only needs to convert the Thash feature values into binary vectors and store them in Milvus.
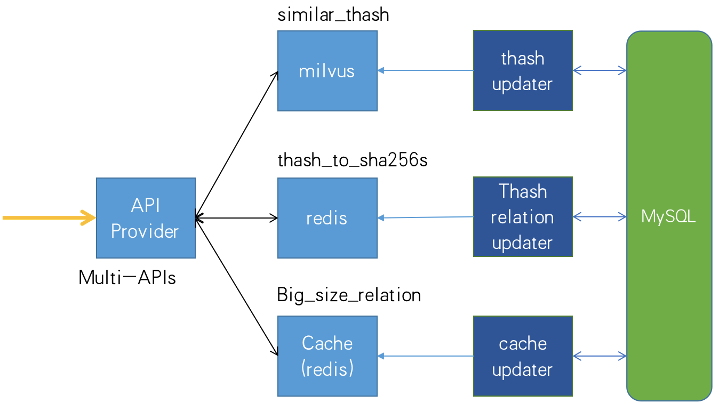
After retrieving similar vectors, the team also needs to query the multiple Sha256 hash values corresponding to the Thash feature values in MySQL. Trend Micro has added a Redis cache in the architecture design to store the mapping of Thash feature values and Sha256 hash values to reduce query time. The architecture is shown in the figure below:
Milvus supports various distance calculation methods and index types for vectors, as shown in the figure below:
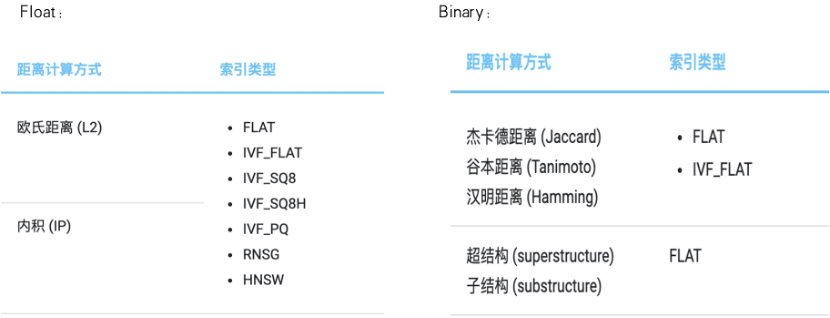
Trend Micro converts Thash into binary vectors stored in Milvus. To align with the business side, Trend Micro uses Hamming distance to calculate the ANN distance between different vectors.
It is understood that future versions of Milvus will add string-type IDs. The release of this feature can eliminate the need for Redis cache and simplify the current architecture.
Currently, Trend Micro adopts a cloud solution, with many tasks deployed on Kubernetes. To achieve high availability for vector retrieval, we chose Mishards—a Milvus cluster sharding middleware developed in Python, as shown in the figure below:
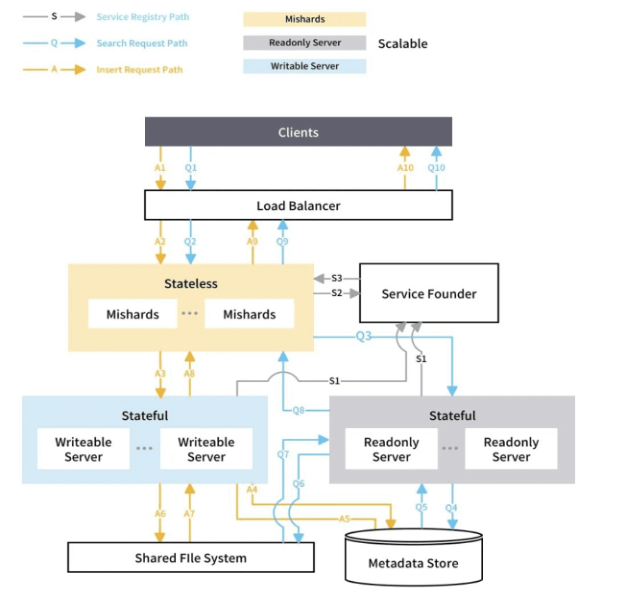
Trend Micro uses AWS’s EFS (Elastic File System) to store the actual vector data. This storage and computation separation approach will become a trend. Additionally, Trend Micro can leverage Kubernetes to start multiple read nodes and create LoadBalancer-type services based on these read nodes to ensure the entire cluster remains available even when one or more nodes are unavailable.
Initially, Milvus’s architecture was single-node and not a fully distributed system. Due to considerations of consistency, Milvus currently only supports one write node. However, in the future, distributed Milvus will address this issue.
Monitoring and Alerts
Milvus builds a monitoring system based on Prometheus, using the open-source time-series data analysis and visualization platform Grafana to display various performance metrics.
Using Prometheus to monitor and store performance metrics:
-
Prometheus Server: Collects and stores time-series data
-
Client Code Library: Customizes monitoring metrics
-
Pushgateway: Pushes metric data to ensure Prometheus can retrieve monitoring metrics that have short lifecycles and are difficult to extract in time
-
Alertmanager: Implements the alert mechanism
The monitoring metrics are comprehensive and include:
-
Milvus performance metrics
-
System operation metrics: CPU/GPU usage
-
Network, disk reading, and other metrics
-
Hardware storage metrics: data size, data file, and storage conditions, etc.
System Operation Effects
Currently, the ThashSearch service built by Trend Micro based on Milvus has been online for several months. The average latency for complete link queries is within 95 milliseconds, as shown in the figure below:
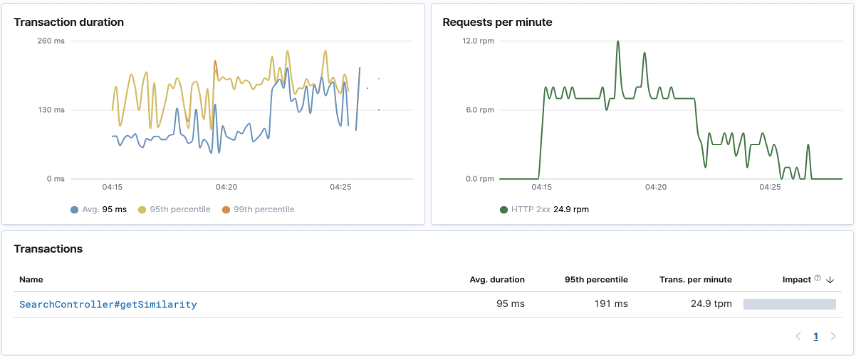
The overall results meet the goals set during the initial design. The data import speed is also very fast, with the import of 3 million 192-dimensional vector data taking only about 10 seconds.
More Milvus User Cases
· Similarity Search for Graphic Trademarks – Milvus Practice by ZhiQingZhe
· Error Retrieval for Content Recall and Short Text Classification Based on Semantic Vectors – Milvus Practice by Sohu
· Vector Search Practice Based on Milvus by Beike
· My New Robot Colleague
Welcome to Join the Milvus Community
