Introduction to the Paper

Despite the increasing applications of prompt learning methods in various few-shot natural language processing tasks, designing templates and label mappings in prompt learning is quite challenging, requiring a deep understanding of the model and classification tasks, along with extensive trial and error. Existing methods for automating label mapping design, while saving labor, struggle to unify downstream few-shot text classification tasks with pre-training tasks, resulting in suboptimal performance. To address this issue, this paper proposes MetricPrompt, which transforms the few-shot text classification task into a text relevance estimation task, liberating human labor from label mapping design. MetricPrompt uses a prompt learning model as a relevance metric, aligning well with pre-training tasks and capturing the interaction information between input text pairs to achieve higher prediction accuracy. In four few-shot settings across three few-shot text classification tasks, MetricPrompt outperformed the previous best automated label mapping design methods and achieved better performance than manually designed methods without requiring human design of task-related label mappings.
Title:MetricPrompt: Prompting Model as a Relevance Metric for Few-shot Text Classification
Authors:Dong Hongyuan, Zhang Weinan, Che Wanxiang
Published In:KDD 2023, Long Paper
Paper:https://dl.acm.org/doi/10.1145/3580305.3599430
01
Introduction
Text classification is considered one of the most fundamental and important tasks in text mining, with related techniques applied in various text mining application scenarios such as information retrieval, sentiment analysis, recommendation systems, and knowledge management [1]. In recent years, pre-trained language models, which have garnered significant attention from researchers, can achieve satisfactory text classification performance on richly labeled text classification tasks, yet their few-shot learning capabilities still lag far behind human intelligence [2].
Prompt learning methods better leverage the general knowledge of pre-trained models by aligning downstream tasks with their pre-training objectives. Prompt learning models take prompt text as input and map the model’s output words to corresponding labels through label mapping to obtain text classification results. In this process, the design of label mappings largely determines the performance of the prompt learning model. However, designing an appropriate label mapping is quite difficult. To alleviate the pressure of manual label mapping design, researchers have proposed automated label mapping design methods.
These algorithms can be categorized into discrete label mapping design and soft label mapping design methods. Discrete label mapping design methods, such as AVS [3], LM-BFF [4], and AutoPrompt [5], search for answer words corresponding to each label within the vocabulary of the pre-trained model to construct label mappings. Soft label mapping design methods, such as WARP [6] and ProtoVerb [7], search for suitable label mapping parameters in an infinite continuous space to achieve better performance. However, as shown in Figure 1, both methods use the internal activation values of the pre-trained model as feature representations of samples, performing classification predictions by calculating the Euclidean distance between them and the feature representations of various labels. This forces the pre-trained model to adapt to a task organization format different from its pre-training objectives. Worse still, the feature representations of classification labels in these methods must be trained from scratch in downstream tasks, which may lead to severe overfitting issues.
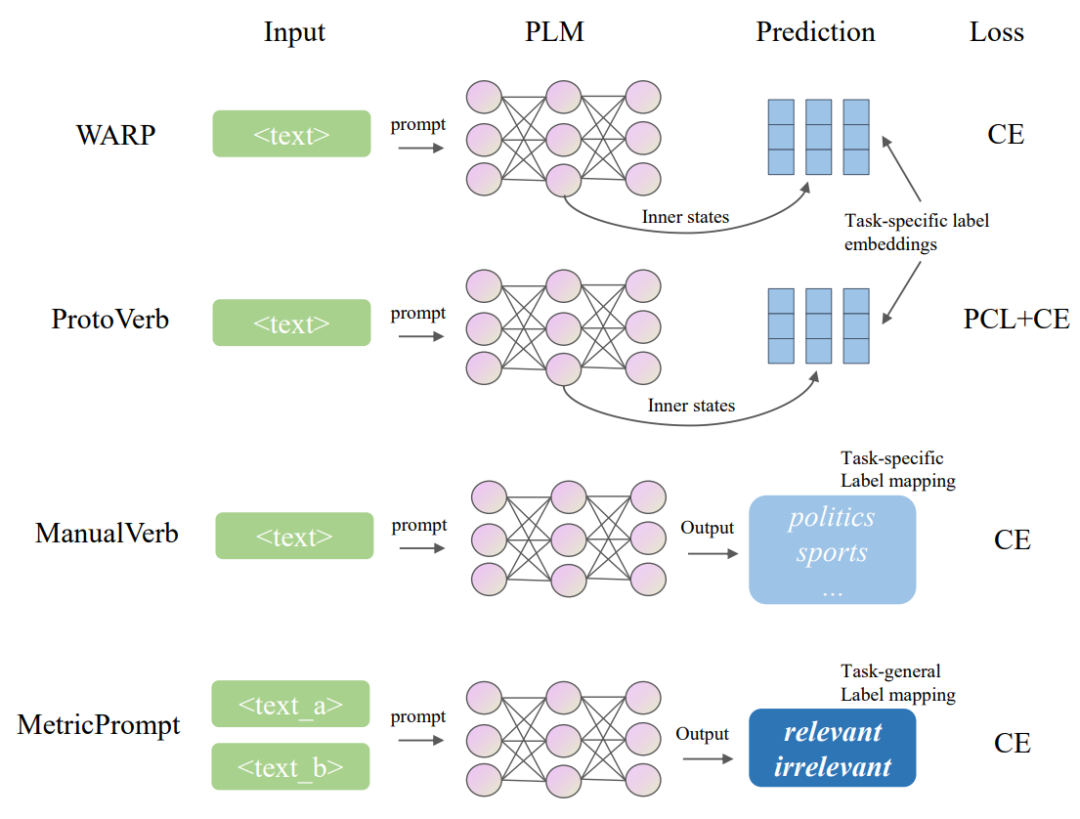
Figure 1 Comparison of various label mapping design methods. In the figure, “CE” represents the cross-entropy loss function, and “PCL” is the prototypical contrastive learning loss function [7]
To solve the aforementioned issues, this paper proposes MetricPrompt, which reconstructs the few-shot text classification task as a text pair relevance estimation task, alleviating the labor costs associated with task-related label mapping design. As shown in Figure 1, in this method, explicit task-related label mapping design is no longer required. Aligned with the pre-training objectives of the pre-trained model, MetricPrompt only processes the output word probability distribution of the pre-trained model, thereby smoothly adapting to downstream tasks. At the same time, MetricPrompt takes text pairs as input, allowing the use of cross-relevance information between sample texts to enhance estimation accuracy during its relevance modeling process.
This paper conducts experiments under four few-shot settings across three widely used few-shot text classification datasets, showing that MetricPrompt surpasses all automated label mapping design baseline methods and even outperforms manual design methods that require significant human effort for task-related label mapping design. Additionally, the scalability and robustness of MetricPrompt are analyzed through experimental studies, and the reasons for variations in model performance when using different relevance score pooling methods are explained.
02
Methodology
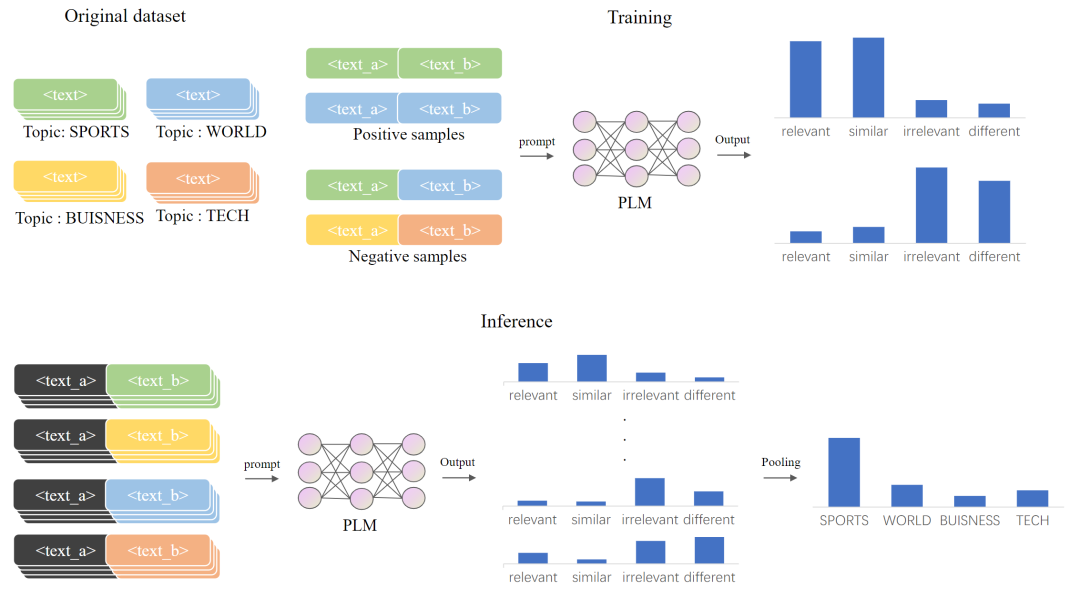
2.1 Data Construction
Given a few-shot text classification dataset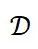 , this paper uses
, this paper uses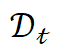 to denote the training data, and
to denote the training data, and  to represent the test sample set. A sample is represented as d=(xd, yd), where xd denotes the sample text, and yd denotes its label. Since MetricPrompt accepts a pair of sample texts as input, this paper constructs the training data as follows:
to represent the test sample set. A sample is represented as d=(xd, yd), where xd denotes the sample text, and yd denotes its label. Since MetricPrompt accepts a pair of sample texts as input, this paper constructs the training data as follows:

Where 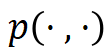 is the prompt learning template function of MetricPrompt. This function fills two segments of sample texts into the prompt learning template to generate the input for the prompt learning model. This paper uses “
is the prompt learning template function of MetricPrompt. This function fills two segments of sample texts into the prompt learning template to generate the input for the prompt learning model. This paper uses “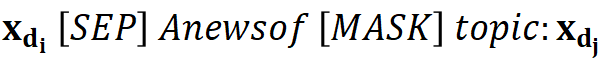 ” as the prompt learning template.
” as the prompt learning template.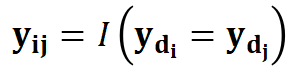 denotes whether the input sample text pair belongs to the same category. Similarly, this paper constructs the test data for MetricPrompt as follows:
denotes whether the input sample text pair belongs to the same category. Similarly, this paper constructs the test data for MetricPrompt as follows:

The entire data construction process is illustrated in Figure 2:
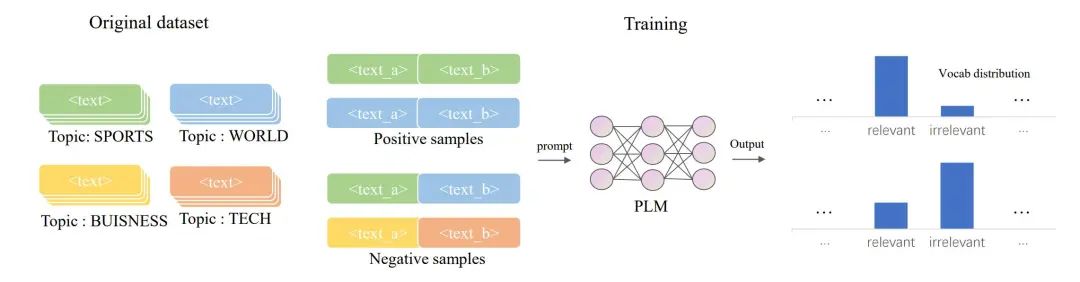
Figure 2 Data construction and training process of MetricPrompt
2.2 Optimization
Let P(· ; θ) be the MLM model parameterized by θ, and fvocab(· ; θ) be its output word probability distribution at the [MASK] position. This paper defines the optimization objective of MetricPrompt as follows:
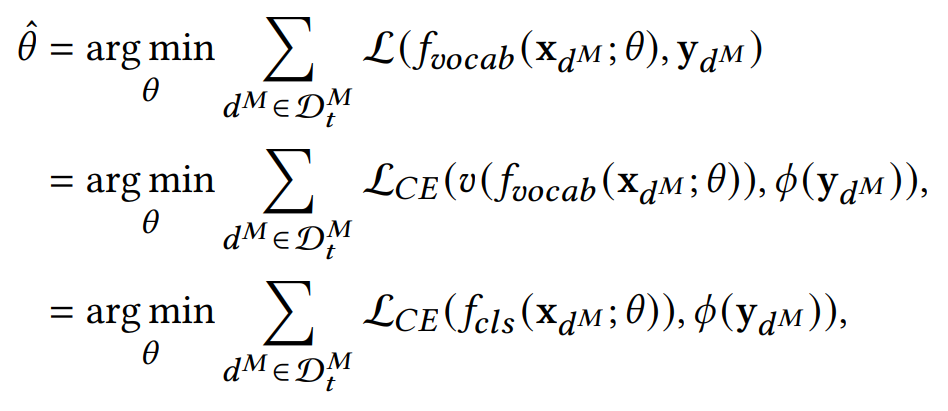
Where Φ(·) represents the probability distribution over label categories. The true label corresponding to the input sample is set to 1, while other positions are set to 0. v(·) represents a predefined task-general label mapping that maps the output word probability distribution fvocab(· ; θ) to a binary distribution fcls (· ; θ). This label mapping aggregates the logits of relevant, similar, consistent into the prediction logit for label 1, while aggregating the logits of irrelevant, inconsistent, different into the logit for label 0. This label mapping is applicable to all few-shot text classification tasks, thus MetricPrompt does not require any task-related label mapping design. is the loss function of MetricPrompt, which takes the form of the cross-entropy loss between the probability distribution generated by the label mapping v(·) and the true distribution.
is the loss function of MetricPrompt, which takes the form of the cross-entropy loss between the probability distribution generated by the label mapping v(·) and the true distribution.
2.3 Inference
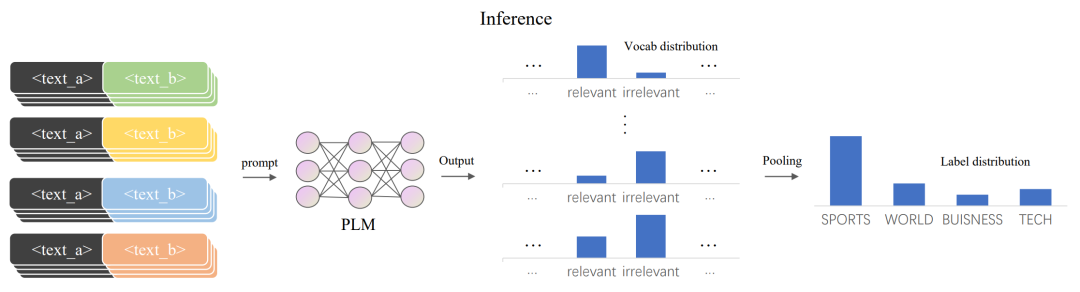
Figure 3 Inference process of MetricPrompt
After optimization, the prompt learning model acts as a relevance metric during the inference process. As shown in Figure 3, this paper pairs the original test sample dq (in black) with all training samples of different categories (in color) to form samples for the inference phase. Given an original training sample di, MetricPrompt calculates the relevance score of dq with respect to it as follows:
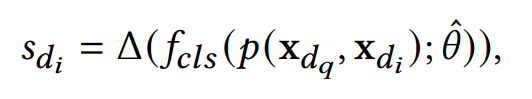
Here, 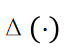 is used to calculate the difference between the probabilities of the binary distribution at positions 1 and 0. This paper uses
is used to calculate the difference between the probabilities of the binary distribution at positions 1 and 0. This paper uses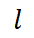 to denote the label for the few-shot text classification task. Let:
to denote the label for the few-shot text classification task. Let:
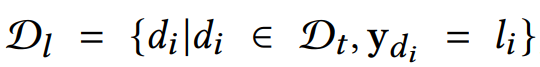
MetricPrompt calculates the classification score of the label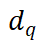 by aggregating the relevance of the corresponding samples with
by aggregating the relevance of the corresponding samples with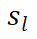 :
:
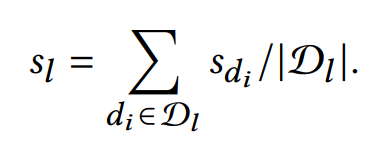
Finally, MetricPrompt selects the label with the highest relevance score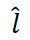 as the classification result:
as the classification result:
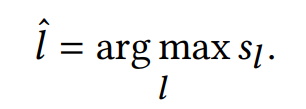
The above describes how MetricPrompt operates using sum pooling. This pooling function can also be replaced with max pooling and K-nearest neighbor (KNN) pooling. Max pooling classifies the test sample dq into the category corresponding to the most relevant training sample. Replacing the computation of with the following formula, MetricPrompt can utilize the max pooling method for text classification tasks:
with the following formula, MetricPrompt can utilize the max pooling method for text classification tasks:
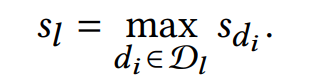
For KNN pooling, this paper uses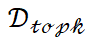 to denote the number of training samples most relevant to dq in
to denote the number of training samples most relevant to dq in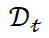 , and rewrites the computation of
, and rewrites the computation of

This paper sets 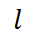 to half the size of the training set.
to half the size of the training set.
When multiple labels occur with the same frequency, this paper selects the sample with the highest relevance score among those corresponding to these labels and classifies dq into its category.
2.4 More Efficient Inference
To further enhance the efficiency of MetricPrompt, this paper proposes using representative samples to reduce the overhead during the inference phase of MetricPrompt. For a training sample labeled as 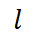 , using
, using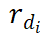 denotes the representativeness of this sample, calculated as follows:
denotes the representativeness of this sample, calculated as follows:
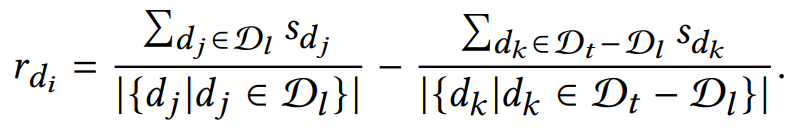
Where, denotes the relevance score between samples dj and di . Based on this representativeness metric, this paper selects the p samples with the highest representativeness score from the training samples corresponding to each label to participate in the inference process.
denotes the relevance score between samples dj and di . Based on this representativeness metric, this paper selects the p samples with the highest representativeness score from the training samples corresponding to each label to participate in the inference process.
Representative samples can significantly reduce the time complexity of the inference process of MetricPrompt. For a few-shot text classification task with n label categories, each corresponding to k samples, without introducing representative samples, each test sample needs to be paired with n*k training samples and perform relevance score calculations, resulting in a time complexity of O(n*k). In contrast, traditional prompt learning methods and other prompt learning methods that do not require manual label mapping design only need to compute the dot product similarity between the feature representations of the test samples extracted from the pre-trained model and the feature representations of each label, resulting in a time complexity of only O(n). After optimizing the inference process with representative samples, MetricPrompt only needs to calculate the relevance estimates between each test sample and the representative samples for each label, thus reducing the time complexity to O(p*n). Here, p is a constant set by humans. Therefore, after accelerating inference using representative samples, MetricPrompt has a time complexity of O(n), consistent with other commonly used prompt learning methods. In the experiments, this paper sets the number of representative samples per label to 2.
03
Experiments
3.1 Datasets
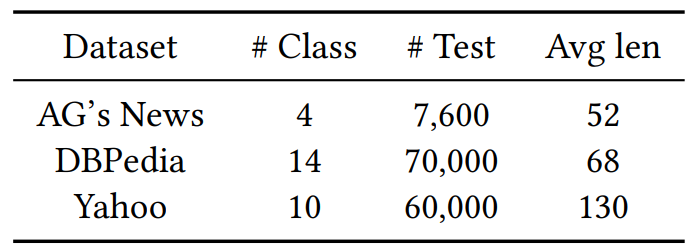
This paper conducts experiments using three text classification datasets: AG’s News, Yahoo Answers Topics, and DBPedia. The statistical data of the datasets are provided in Table 1:
Table 1 Dataset Statistics
3.2 Implementation Details
This paper conducts experiments under 2, 4, 8, and 16-shot settings, where the corresponding number of training samples is randomly sampled from the training set of each dataset. To mitigate the randomness in training set selection, this paper extracts 10 training sets for each dataset and each few-shot setting. All experimental results are presented as the average performance of the model across the 10 training sets.
For fair comparison, this paper uses BERT-base-uncased as the backbone model for MetricPrompt and all baseline models. The total number of training steps is set based on the size of the training set, and the number of training epochs is adjusted accordingly. The size of the training set varies due to the number of labels in the dataset and the few-shot settings; specific training epoch counts for each setting are shown in Table 2.
Table 2 Number of Training Epochs Under Different Experimental Settings

3.3 Main Experimental Results
This paper conducts experiments on three text classification datasets with different textual styles under four few-shot settings. The results of the 2-shot and 4-shot experiments are listed in Table 3, while the results of the 8-shot and 16-shot experiments are provided in Table 4.
Table 3 Experimental Results Under 2-shot and 4-shot Settings, with Accuracy as the Metric. Italic indicates that the method requires manual task-related label mapping design, and bold indicates the best result among methods that do not require manual task-related label mapping design.
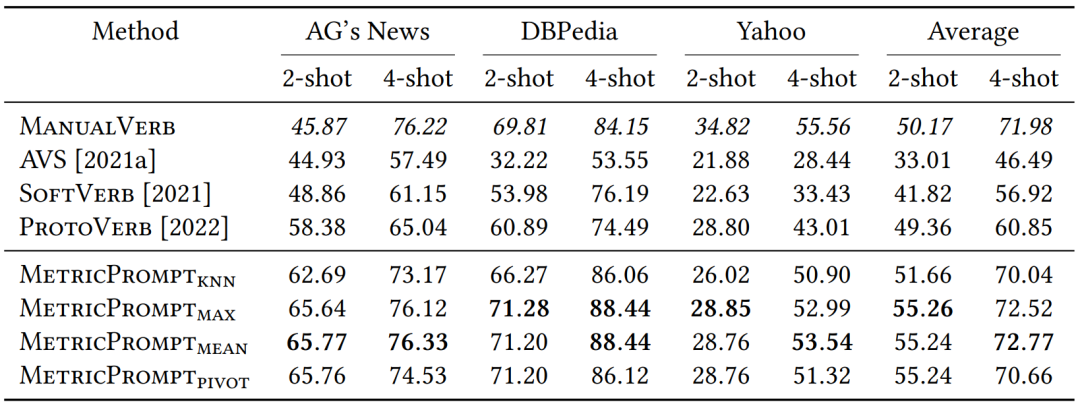
Table 4 Experimental Results Under 8-shot and 16-shot Settings, with Accuracy as the Metric. Italic indicates that the method requires manual task-related label mapping design, and bold indicates the best result among methods that do not require manual task-related label mapping design.

Compared to the SOTA prompt learning method ProtoVerb, which does not require manual label design, MetricPrompt improves the accuracy by 5.88 in the 2-shot setting, 11.92 in the 4-shot setting, 6.80 in the 8-shot setting, and 1.56 in the 16-shot setting. MetricPrompt even surpasses the performance of ManualVerb in all few-shot settings without requiring manual task-related label mapping design. In the experimental setting where only 2 representative samples are selected per label, MetricPrompt still achieves excellent performance. With the same time complexity, its performance significantly exceeds the previous SOTA baseline model ProtoVerb and achieves scores comparable to ManualVerb.
04
Analysis
4.1 Scalability Testing with Out-of-Domain Data
In practical applications, it is not always possible to obtain sufficient labeled data in real scenarios. Therefore, the scalability of few-shot text classification methods on out-of-domain (OOD) data is crucial for their practicality. To demonstrate the scalability of MetricPrompt, this paper utilizes the 16-shot training sets of various datasets to assist in the few-shot text classification tasks of other datasets.
Table 5 Model Performance of MetricPrompt and ProtoVerb with Additional OOD Data
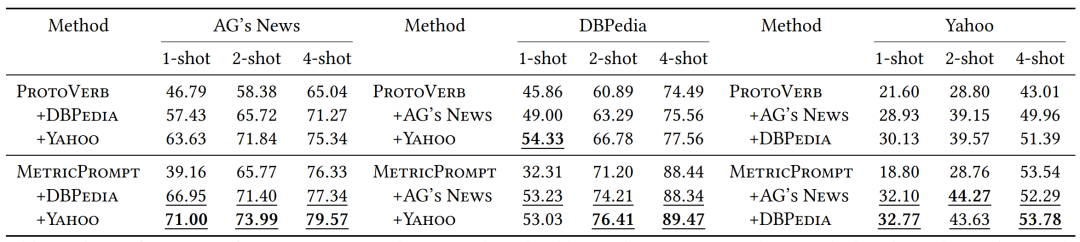
As shown in Table 5, MetricPrompt achieves higher accuracy with the support of OOD training data. Compared to the previous SOTA baseline ProtoVerb, MetricPrompt achieves higher prediction accuracy in 17 out of 18 few-shot and OOD data settings (the numbers in the table are underlined).
Notably, the performance improvement of MetricPrompt in the 1-shot setting is significantly higher than in other few-shot settings. This is because, in the 1-shot setting, MetricPrompt only uses two identical texts as positive samples, leading to severe overfitting issues. The introduction of diverse OOD data effectively mitigates the overfitting problem, thus significantly improving the performance of MetricPrompt in the 1-shot task.
4.2 Robustness Against Noise
Due to the lack of supervisory signals, noisy samples can severely affect the performance of few-shot text classification models. This section evaluates the robustness of MetricPrompt against noisy samples on the AG’s News dataset. This paper randomly replaces 1, 2, and 4 training samples’ labels to introduce noise and tests the performance of MetricPrompt when using average, max, and KNN pooling. The performance degradation caused by noisy samples is shown in Table 6:
Table 6 Performance Degradation of the Model on AG’s News Dataset Under 8-shot and 16-shot Settings with 1, 2, and 4 Noisy Samples Introduced. Bold indicates the least performance degradation among all methods.
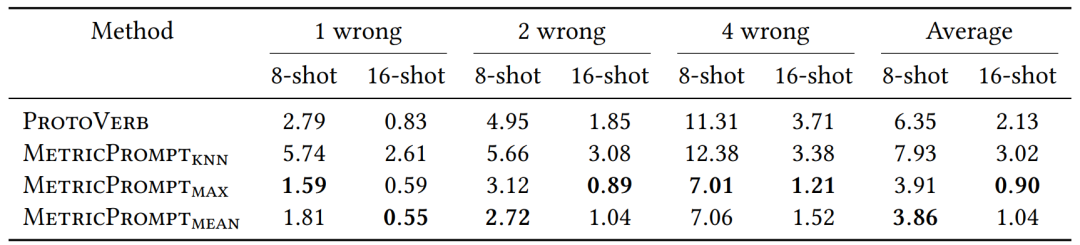
Compared to ProtoVerb, MetricPrompt exhibits less performance degradation when using average and max pooling, achieving higher classification accuracy.
4.3 Comparison of Different Pooling Methods
First, this paper analyzes the scenario without noisy samples. This paper collects statistics on the distribution of relevance scores computed by MetricPrompt. As shown in Figure 4, the distribution of relevance scores is highly uneven. Therefore, the maximum relevance score plays a decisive role in the MetricPrompt using average pooling, leading to behavior similar to max pooling. However, KNN pooling adopts a voting strategy, ignoring score value information, resulting in more classification errors.
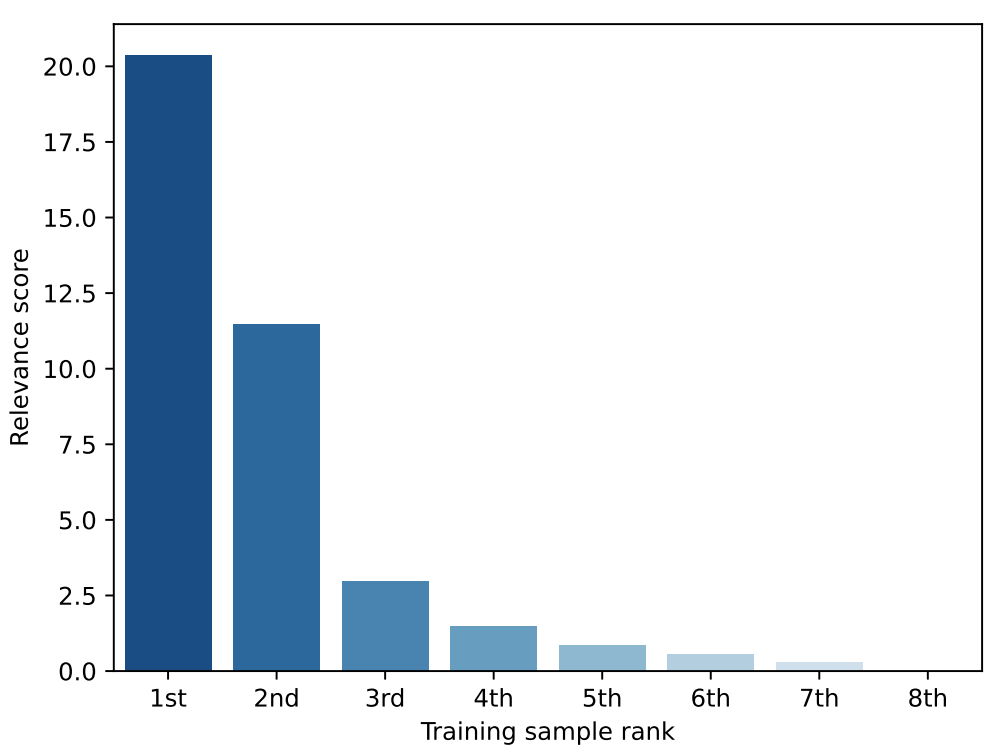
Figure 4 Average relevance scores between each test sample and training samples under the 2-shot setting of the AG’s News dataset
Next, the performance of MetricPrompt in the presence of noisy samples is analyzed. As shown in Figure 4, except for the few most relevant samples, the distribution of other relevance scores is relatively uniform. Assuming an extreme case where the distribution of relevance scores is uniform, the predictions made by KNN pooling will be significantly influenced by the variance in the number of training samples for each category. Based on this phenomenon, the poor performance of KNN pooling when introducing noisy samples is attributed to its voting mechanism, which makes it susceptible to the variance in the number of training samples for each category. To verify this, this paper collects statistics on the average number of predicted test samples for each type of category.
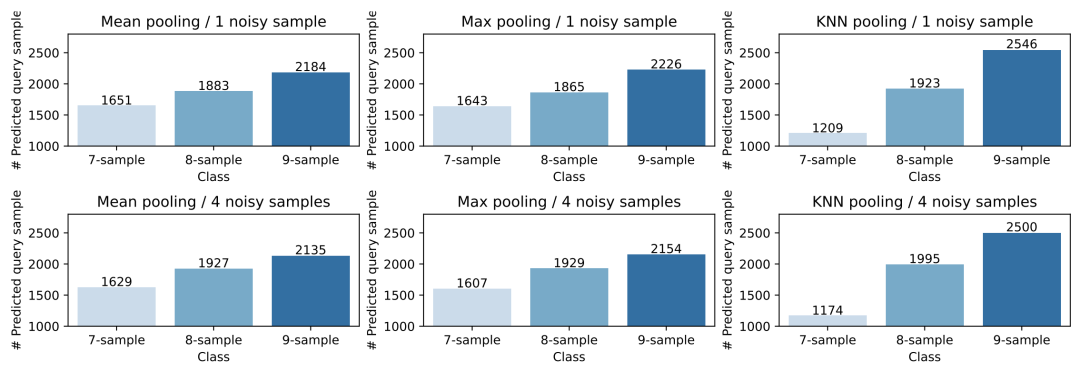
Figure 5 Average number of times each category, with 7, 8, and 9 training samples, is predicted during the testing phase under the 8-shot setting of the AG’s News dataset. “# Predicted query sample” indicates the average number of test samples predicted as that category during the testing phase.
As shown in Figure 5, KNN pooling exhibits a stronger preference for categories with more training samples, significantly higher than average pooling and max pooling, leading to an abnormally high number of predicted test samples for those corresponding categories. Therefore, when introducing noisy samples, the performance of KNN pooling declines significantly.
4.4 Impact Analysis of the Number of Representative Samples
This section studies the impact of the number of representative samples on the performance of MetricPrompt. This paper conducts experiments under four few-shot settings across three datasets and sets the number of representative samples to 1, 2, and 4 respectively.
Table 7 Experimental Results Using Representative Samples Under 2-shot and 4-shot Settings, with Accuracy as the Metric. Bold indicates the best result for that task.
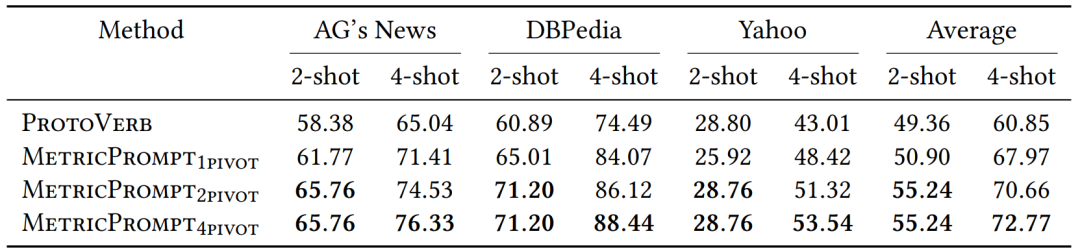
Table 8 Experimental Results Using Representative Samples Under 8-shot and 16-shot Settings, with Accuracy as the Metric. Bold indicates the best result for that task.
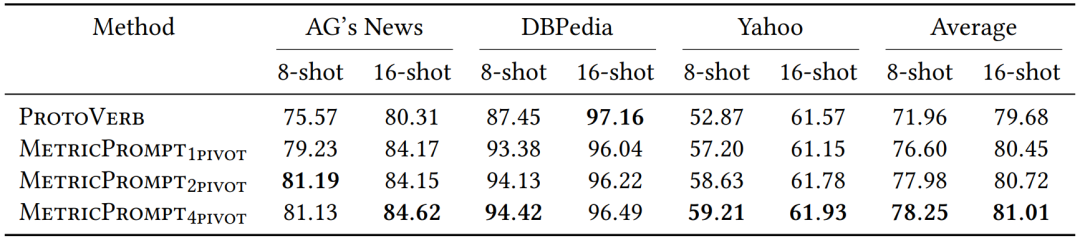
As shown in Tables 7 and 8, the performance of MetricPrompt is positively correlated with the number of representative samples. Notably, even when only one representative sample per category is retained for inference, MetricPrompt still outperforms previous SOTA methods ProtoVerb under all four few-shot settings. By adjusting the number of representative samples $p$, MetricPrompt can achieve a balance between classification accuracy and efficiency.
05
Conclusion
To address the issue where the performance of few-shot text classification methods based on prompt learning heavily relies on manual label mapping design, while automated label mapping design methods perform poorly, this paper proposes MetricPrompt, which transforms the few-shot text classification task into a text pair relevance estimation task to alleviate the burden of manual label mapping design. MetricPrompt pairs few-shot training data and trains a prompt learning model to estimate the relevance of text pairs. The optimized prompt learning model acts as a metric for estimating the relevance between the test sample and each training sample, thus completing classification predictions. Compared to other automated label mapping design methods, MetricPrompt does not require the introduction of task-specific label feature representations, avoiding overfitting problems caused by insufficient labeled data in downstream tasks. Simultaneously, the way MetricPrompt operates can be seen as a generalized masked language modeling task, allowing the pre-trained model to adapt more smoothly to downstream few-shot text classification tasks. Experimental results across three datasets under four few-shot settings show that MetricPrompt significantly outperforms previous SOTA models and achieves better text classification performance than manual design methods without introducing human knowledge for task-related label mapping design.
06
References
[1] Vandana Korde and C Namrata Mahender. 2012. TEXT CLASSIFICATION AND CLASSIFIERS: A SURVEY. International Journal of Artificial Intelligence & Applications 3, 2 (2012), 85.
[2] Tom B. Brown, Benjamin Mann, et al. 2020. Language Models are Few-Shot Learners. NeurIPS 2020.
[3] Timo Schick and Hinrich Schütze. 2021. Exploiting Cloze-Questions for FewShot Text Classification and Natural Language Inference. EACL 2021
[4] Tianyu Gao, Adam Fisch, and Danqi Chen. 2021. Making Pre-trained Language Models Better Few-shot Learners. ACL 2021.
[5] Taylor Shin, Yasaman Razeghi, Robert L. Logan IV, Eric Wallace, and Sameer Singh. 2020. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. EMNLP 2020.
[6] Karen Hambardzumyan, Hrant Khachatrian, and Jonathan May. 2021. WARP: Word-level Adversarial ReProgramming. ACL 2021.
[7] Ganqu Cui, Shengding Hu, Ning Ding, Longtao Huang, and Zhiyuan Liu. 2022. Prototypical Verbalizer for Prompt-based Few-shot Tuning. ACL 2022.