How to Handle a Large Number of Tools
The subset of tools available for invocation is typically determined by the model (although many providers also allow users to specify or limit the selection of tools). As the number of available tools increases, you may want to limit the LLM’s selection to reduce token consumption and help manage sources of errors in LLM inference.
Here, we will demonstrate how to dynamically adjust the tools available to the model. First, it should be noted that, similar to RAG and similar methods, we add a prefix to the model call by retrieving the available tools. While we demonstrate an implementation of searching tool descriptions, the details of tool selection can be customized as needed.
Let’s consider a small example where we provide a tool for each publicly traded company in the S&P 500 index. Each tool retrieves company-specific information based on the year provided as a parameter.
We first build a registry that associates a unique identifier for each tool with its schema. We will use a JSON schema to represent the tool, which can be directly bound to the chat model that supports tool invocation.
import re
import uuid
from langchain_core.tools import StructuredTool
def create_tool(company: str) -> dict:
"""Create a pattern for a placeholder tool."""
# Remove non-alphanumeric characters and replace spaces with underscores to generate tool name
formatted_company = re.sub(r"[^\\w\s]", "", company).replace(" ", "_")
def company_tool(year: int) -> str:
# Placeholder function that returns static revenue information for the company and year
return f"{company} had revenues of $100 in {year}."
return StructuredTool.from_function(
company_tool,
name=formatted_company,
description=f"Information about {company}",
)
# Simplified list of S&P 500 companies for demonstration
s_and_p_500_companies = [
"3M",
"A.O. Smith",
"Abbott",
"Accenture",
"Advanced Micro Devices",
"Yum! Brands",
"Zebra Technologies",
"Zimmer Biomet",
"Zoetis",
]
# Create a tool for each company and store it in a dict using a unique UUID as the key
tool_registry = {
str(uuid.uuid4()): create_tool(company) for company in s_and_p_500_companies
}
We will build a node that retrieves a subset of available tools based on information in the state (e.g., the most recent user message). Generally, this step can be implemented using all retrieval solutions.
As a simple solution, we index the embeddings of tool descriptions in a vector store and associate user queries with tools through semantic search.
from langchain_core.documents import Document
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_ollama import OllamaEmbeddings
import base_conf
tool_documents = [
Document(
page_content=tool.description,
id=id,
metadata={"tool_name": tool.name},
)
for id, tool in tool_registry.items()
]
vector_store = InMemoryVectorStore(
embedding=OllamaEmbeddings(base_url=base_conf.base_url,
model=base_conf.embedding_model_name_en)
)
# We can see that we have stored the descriptions and names of the tools in the store
document_ids = vector_store.add_documents(tool_documents)
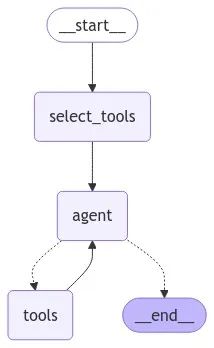
We will use a typical React agent graph and make some modifications:
-
We add a key to the state for selected_tools to store the subset of tools we choose;
-
We set the entry point of the graph to a select_tools node that populates the select_tools key in the state;
-
We bind the selected subset of tools to the chat model agent within the node.
from typing import Annotated
from langchain_ollama import ChatOllama
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
# Define the state structure using TypedDict.
# It includes a list of messages (handled by add_messages)
# and a list of selected tool IDs.
class State(TypedDict):
messages: Annotated[list, add_messages]
# List of selected tool IDs
selected_tools: list[str]
builder = StateGraph(State)
# Retrieve all available tools from the tool dictionary.
tools = list(tool_registry.values())
llm = ChatOllama(base_url=base_conf.base_url, model=base_conf.model_name)
# The agent function handles the current state by binding the selected tools to the LLM.
def agent(state: State):
# Map tool IDs from the selected_tools list in the state to actual tools.
selected_tools = [tool_registry[id] for id in state["selected_tools"]]
# Bind the selected tools to the LLM for the current interaction.
llm_with_tools = llm.bind_tools(selected_tools)
# Call the LLM with the current messages and return the updated message list.
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# The select_tools function selects tools based on the content of the user's last message.
def select_tools(state: State):
last_user_message = state["messages"][-1]
query = last_user_message.content
tool_documents = vector_store.similarity_search(query)
return {"selected_tools": [document.id for document in tool_documents]}
builder.add_node("agent", agent)
builder.add_node("select_tools", select_tools)
tool_node = ToolNode(tools=tools)
builder.add_node("tools", tool_node)
builder.add_conditional_edges("agent", tools_condition, path_map=["tools", "__end__"])
builder.add_edge("tools", "agent")
builder.add_edge("select_tools", "agent")
# First, find similar tools from the store using the query and add these tools to the selected_tools in the state.
builder.add_edge(START, "select_tools")
graph = builder.compile()
user_input = "Can you give me some information about AMD in 2022?"
result = graph.invoke({"messages": [("user", user_input)]})
print(result["selected_tools"])
for message in result["messages"]:
message.pretty_print()
['abd4721b-80b3-4e76-82b1-f59efbde9d9a', '26ef59cd-8e93-4915-88dc-b0e5e5c11471', 'a1bd1bae-dbfa-4894-b4a4-aa21985ac8a4', '48d1ccdf-c17c-405f-a127-b56f590c0fcb']
================================ Human Message =================================
Can you give me some information about AMD in 2022?
================================== Ai Message ==================================
Tool Calls: Advanced_Micro_Devices (cbf17b76-4393-47db-b95a-70965dd25322) Call ID: cbf17b76-4393-47db-b95a-70965dd25322 Args:
year: 2022
================================= Tool Message =================================
Name: Advanced_Micro_Devices
Advanced Micro Devices had revenues of $100 in 2022.
================================== Ai Message ==================================
In 2022, Advanced Micro Devices (AMD) reported revenues of $100 billion.
The flowchart for the agent is as follows:
To manage errors caused by incorrect tool selection, we can revisit the select_tools node.
One option to implement this is to modify select_tools to use all messages in the state (for example, using the chat model) to generate a vector store query and add routing edges from tools to select_tools in the graph.
The core point is that we need to understand that a node can be run repeatedly, because it is connected to the LLM, and through multiple attempts, it is possible to recover from errors. This is a different way of thinking compared to traditional development.