This article introduces a practical project that uses LangGraph to develop a RAG research multi-agent tool. This tool is designed to solve complex problems that require multiple sources and iterative steps to arrive at a final answer. It employs hybrid search and Cohere reordering steps to retrieve documents, and also includes a self-correction mechanism, including a hallucination check process to enhance the reliability of responses, making it very suitable for enterprise applications.
Github Repo is here..
1. Introduction — Naive vs. Agentic RAG
For the purpose of the project, the naive RAG method is insufficient for the following reasons:
-
• Inability to Understand Complex Queries: It cannot decompose complex queries into manageable sub-steps, handling the query at a single level rather than analyzing each step and drawing a unified conclusion. -
• Lack of Hallucination or Error Handling: The naive RAG pipeline lacks response validation steps and mechanisms to handle hallucinations, failing to correct errors by generating new responses. -
• Lack of Dynamic Tool Usage: The naive RAG system does not allow for the use of tools, calling external APIs, or interacting with databases based on workflow conditions.
Therefore, a multi-agent RAG research system was implemented to address all these issues. The agent-based framework effectively allows:
-
• Routing and Using Tools: Routing agents can classify user queries and guide the flow to the appropriate nodes or tools. This enables context-based decision-making, such as determining whether a document needs a complete summary, whether more detailed information is needed, or if the question is out of scope. -
• Planning Sub-Steps: Complex queries often need to be broken down into smaller, manageable steps. Starting from the query, a series of steps can be generated to reach conclusions while exploring different aspects of the query. For instance, if the query requires comparing two different parts of a document, the agent-based approach will allow for the identification of this comparison need, separately retrieve the two sources, and merge them into a comparative analysis in the final response. -
• Reflection and Error Correction: In addition to simple response generation, the agent-based approach can add validation steps to address potential hallucinations, errors, or responses that fail to accurately answer user queries. This also enables the integration of self-correction mechanisms with human collaboration, incorporating human input into the automation process. Such functionality makes the agent-based RAG system a more powerful and reliable solution for enterprise applications, where reliability is paramount. -
• Shared Global State: Agent workflows share a global state, simplifying the management of states between multiple steps. This shared state is crucial for maintaining consistency across the various stages of the multi-agent process.
2. Project Overview
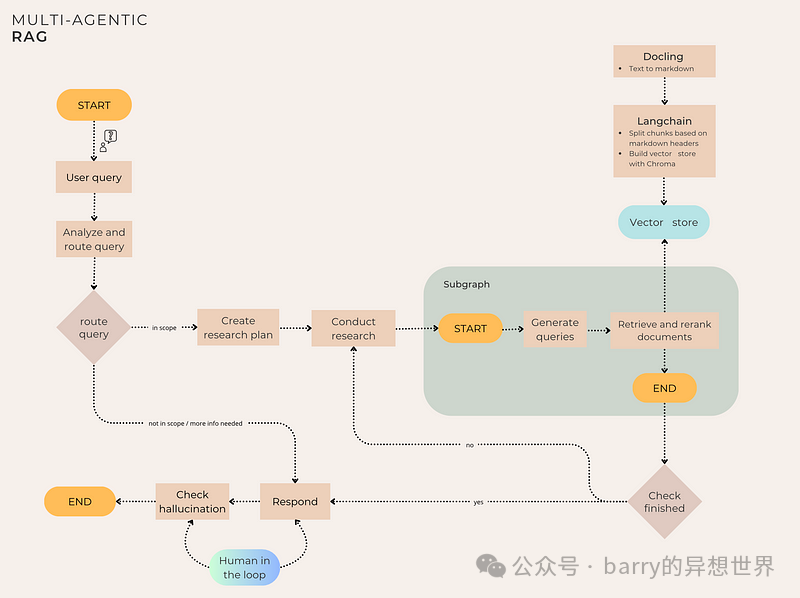
Graph Steps:
-
1. Analyze and Route Query (Adaptive RAG): The user’s query is classified and routed to the appropriate node. From there, the system can choose to continue to the next step (“Research Plan Generation”), request more information or if the query is out of scope, then respond immediately. -
2. Research Plan Generation: The system generates a step-by-step research plan, producing one or more steps based on the complexity of the request. It then returns a list of specific steps to address the user’s question. -
3. Research Subgraph: For each step defined in the research plan generation, a subgraph is called. Specifically, the subgraph begins by generating two queries through LLM. Next, the system uses integrated retrievers (using similarity search, BM25, and MMR) to retrieve documents related to these generated queries. Then, the reordering step applies Cohere-based contextual compression, ultimately generating * k * relevant documents and their associated scores for all steps. -
4. Generation Step: Based on the relevant documents, the tool generates answers through LLM. -
5. Hallucination Check (Self-Correcting RAG with Human in the Loop): There is a reflection step where the system analyzes the generated answer to determine if it is supported by the provided context and addresses all aspects. If the check fails, the graph workflow will be interrupted, and the user will be prompted to generate a revised answer or terminate the process.
To create a vector store, a paragraph-based segmentation method was implemented using Docling and LangChain, with the vector database built using ChromaDB.
Building the Vector Database
Document Parsing
For PDFs with complex structures, including tables with intricate layouts, careful selection of tools for parsing is crucial. Many libraries lack precision when handling PDFs with complex page layouts or table structures.
To address this issue, Docling, an open-source library, was used. It simplifies and efficiently handles document parsing, allowing export to the desired format. It can read and export Markdown and JSON from various common document formats (including PDF, DOCX, PPTX, XLSX, images, HTML, AsciiDoc, and Markdown). Docling provides a comprehensive understanding of PDF documents, including table structure, reading order, and page layout. Additionally, it supports OCR for scanned PDFs.
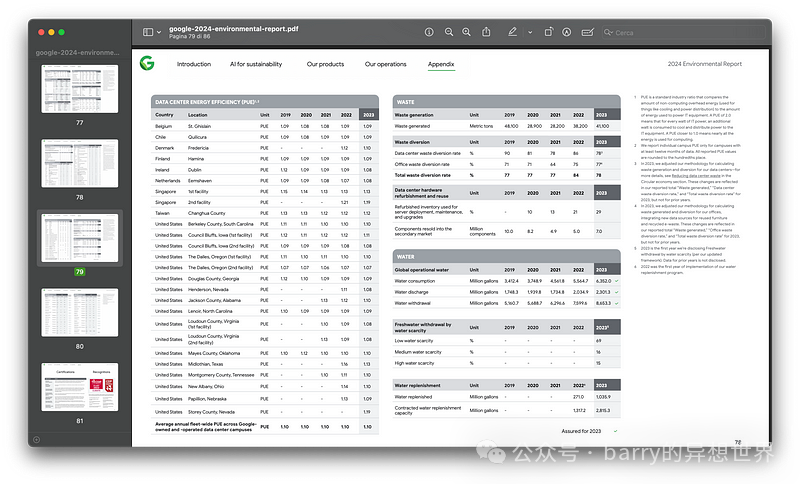
The text contained in the PDF is then converted to Markdown format, which is necessary for following the paragraph-based structure of the chunks.
from docling.document_converter import DocumentConverter
logger.info("Starting document processing.")
converter = DocumentConverter()
markdown_document = converter.convert(source).document.export_to_markdown()The extracted text will have a structure similar to the image below. As shown, the text extracted from the PDF and table parsing retains the original format.
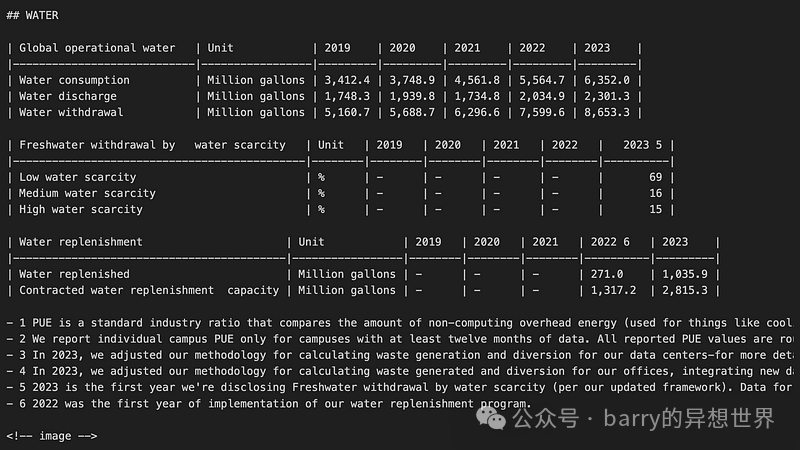
Based on the headers and using<span> MarkdownHeaderTextSplitter</span>, the output text is then split into chunks, resulting in a list of 332 <span>Document</span> objects (LangChain Document).
from langchain_text_splitters import MarkdownHeaderTextSplitter
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2")
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
docs_list = markdown_splitter.split_text(markdown_document)
docs_list### Output Example
[Document(metadata={'Header 2': 'A letter from our Chief Sustainability Officer and our Senior Vice President of Learning and Sustainability'}, page_content="...."),
...]
### len(docs_list):
332Vector Store Construction
We build a vector database to store sentences as vector embeddings and search within that database. In this case, we use Chroma and store a persistent database in the local directory ‘<span>db_vector</span>‘ .
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
embd = OpenAIEmbeddings()
vectorstore_from_documents = Chroma.from_documents(
documents=docs_list,
collection_name="rag-chroma-google-v1",
embedding=embd,
persist_directory='db_vector'
)Main Graph Construction
The implemented system includes two graphs:
-
• Researcher Graph as a subgraph responsible for generating different queries to retrieve and reorder the top k documents from the vector database. -
• Main Graph, which contains the primary workflow, such as analyzing user queries, generating steps needed to complete tasks, generating responses, and checking for hallucinations through a human-machine collaboration mechanism.
Main Graph Structure
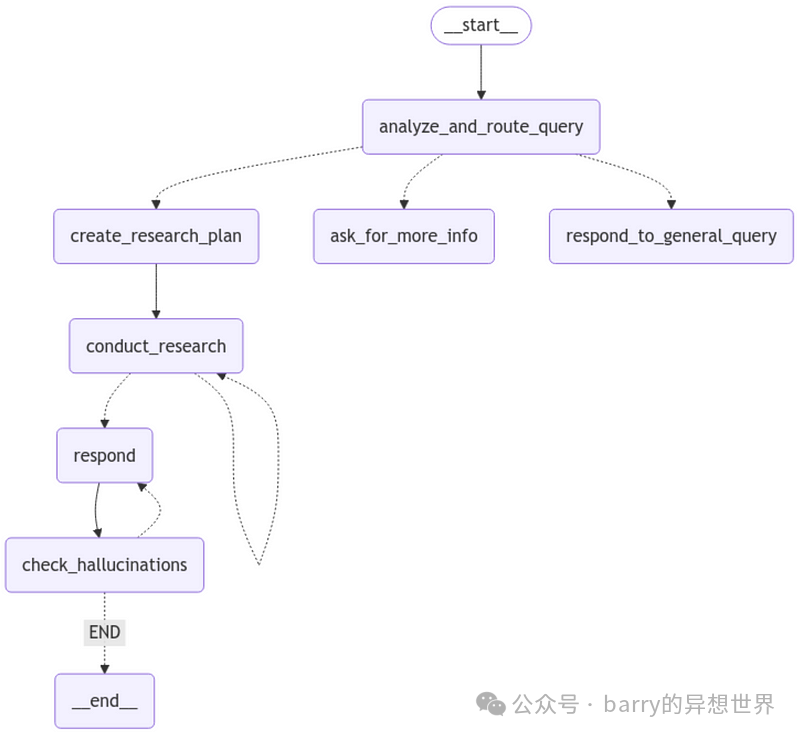
One core concept of LangGraph is state. Each time the graph executes, a state is created that is passed between the executing nodes, with each node updating this internal state with its return value after execution.
Let’s start building the project for the graph state. To do this, we define two classes:
-
• Router: Contains the results of classifying user queries as one of “more-info”, “environmental”, or “general”. -
• GradeHallucination: Contains a binary score indicating the presence of hallucinations in the response.
from pydantic import BaseModel, Field
class Router(TypedDict):
"""Classify user query."""
logic: str
type: Literal["more-info", "environmental", "general"]
from pydantic import BaseModel, Field
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, '1' or '0'"
)The defined graph states are:
-
• InputState: Contains a list of messages exchanged between the user and the agent. -
• AgentState: Contains the classification of the user query by <span>Router</span>, a list of steps to execute in the research plan, a list of retrieved documents that the agent can reference, and a binary score of<span>Gradehallucination</span>.
from dataclasses import dataclass, field
from typing import Annotated, Literal, TypedDict
from langchain_core.documents import Document
from langchain_core.messages import AnyMessage
from langgraph.graph import add_messages
from utils.utils import reduce_docs
dataclass(kw_only=True)
class InputState:
"""Represents the input state for the agent.
This class defines the structure of the input state, which includes
the messages exchanged between the user and the agent. It serves as
a restricted version of the full State, providing a narrower interface
to the outside world compared to what is maintained internally.
"""
messages: Annotated[list[AnyMessage], add_messages]
"""Messages track the primary execution state of the agent.
Typically accumulates a pattern of Human/AI/Human/AI messages.
Returns:
A new list of messages with the messages from `right` merged into `left`.
If a message in `right` has the same ID as a message in `left`, the
message from `right` will replace the message from `left`."""
### Primary agent state
dataclass(kw_only=True)
class AgentState(InputState):
"""State of the retrieval graph / agent."""
router: Router = field(default_factory=lambda: Router(type="general", logic=""))
"""The router's classification of the user's query."""
steps: list[str] = field(default_factory=list)
"""A list of steps in the research plan."""
documents: Annotated[list[Document], reduce_docs] = field(default_factory=list)
"""Populated by the retriever. This is a list of documents that the agent can reference."""
hallucination: GradeHallucinations = field(default_factory=lambda: GradeHallucinations(binary_score="0"))Step 1: Analyze and Route Query
The function <span>analyze_and_route_query</span> returns and updates the state variable <span>AgentState</span> of the <span>router</span>. The function <span>route_query</span> determines the next step based on the previous query classification.
Specifically, this step updates the state through the <span>Router</span> object, whose <span>type</span> variable contains one of the following values:<span>"more-info"</span>, <span>"environmental"</span> or <span>"general"</span>. Based on this information, the workflow will be routed to the appropriate nodes (<span>"create_research_plan"</span>, <span>"ask_for_more_info"</span> or <span>"respond_to_general_query"</span>).
async def analyze_and_route_query(
state: AgentState, *, config: RunnableConfig
) -> dict[str, Router]:
"""Analyze the user's query and determine the appropriate routing.
This function uses a language model to classify the user's query and decides how to route in the conversation flow.
Args:
state (AgentState): The current state of the agent, including conversation history.
config (RunnableConfig): Configuration for query analysis.
Returns:
dict[str, Router]: A dictionary containing the 'router' key and classification results (classification type and logic).
"""
model = ChatOpenAI(model=GPT_4o, temperature=TEMPERATURE, streaming=True)
messages = [
{"role": "system", "content": ROUTER_SYSTEM_PROMPT}
] + state.messages
logging.info("---Analyzing and Routing Query---")
response = cast(
Router, await model.with_structured_output(Router).ainvoke(messages)
)
return {"router": response}
def route_query(
state: AgentState,
) -> Literal["create_research_plan", "ask_for_more_info", "respond_to_general_query"]:
"""Determine the next step based on query classification.
Args:
state (AgentState): The current state of the agent, including the routing classification.
Returns:
Literal["create_research_plan", "ask_for_more_info", "respond_to_general_query"]: The next step to take.
Raises:
ValueError: If an unknown routing type is encountered.
"""
_type = state.router["type"]
if _type == "environmental":
return "create_research_plan"
elif _type == "more-info":
return "ask_for_more_info"
elif _type == "general":
return "respond_to_general_query"
else:
raise ValueError(f"Unknown routing type {_type}")Output example for the query “Retrieve the PUE efficiency values of the Dublin data center in 2019”:
{
"logic":"This is a specific question about the environmental efficiency of the Dublin data center in 2019, related to the environmental report.",
"type":"environmental"
}Step 1.1 Out of Scope / Need More Information
We define the functions <span>ask_for_more_info</span> and <span>respond_to_general_query</span>, which generate responses for the user directly by calling LLM: if the router determines that the user needs more information, the first function is executed, while the second function generates a general query response unrelated to our topic. In this case, it is necessary to connect the generated response to the message list and update the <span>messages</span> variable in the state.
async def ask_for_more_info(
state: AgentState, *, config: RunnableConfig
) -> dict[str, list[BaseMessage]]:
"""Generate a response requesting the user to provide more information.
Called when the router determines that the user needs more information.
Args:
state (AgentState): The current state of the agent, including conversation history and routing logic.
config (RunnableConfig): Configuration for response generation.
Returns:
dict[str, list[str]]: A dictionary containing a 'messages' key with the generated response.
"""
model = ChatOpenAI(model=GPT_4o_MINI, temperature=TEMPERATURE, streaming=True)
system_prompt = MORE_INFO_SYSTEM_PROMPT.format(
logic=state.router["logic"]
)
messages = [{"role": "system", "content": system_prompt}] + state.messages
response = await model.ainvoke(messages)
return {"messages": [response]}
async def respond_to_general_query(
state: AgentState, *, config: RunnableConfig
) -> dict[str, list[BaseMessage]]:
"""Generate a response to a general query unrelated to the environment.
Called when the router classifies the query as a general question.
Args:
state (AgentState): The current state of the agent, including conversation history and routing logic.
config (RunnableConfig): Configuration for response generation.
Returns:
dict[str, list[str]]: A dictionary containing a 'messages' key with the generated response.
"""
model = ChatOpenAI(model=GPT_4o_MINI, temperature=TEMPERATURE, streaming=True)
system_prompt = GENERAL_SYSTEM_PROMPT.format(
logic=state.router["logic"]
)
logging.info("---Response Generation---")
messages = [{"role": "system", "content": system_prompt}] + state.messages
response = await model.ainvoke(messages)
return {"messages": [response]}
Output example for the query “What’s the weather like in Altamura?”:
{
"logic":"What's the weather like in Altamura?",
"type":"general"
}{
"logic":"I appreciate your question, but I'm unable to provide information about the weather. My focus is on Environmental Reports. If you have any questions related to that topic, please let me know, and I'll be happy to help!"
}Step 2: Create Research Plan
If the query classification returns the value <span>"environmental"</span>, the user’s request is document-related, and the workflow will reach the <span>create_research_plan</span> node, whose function is to create a step-by-step research plan for answering environmental-related queries.
async def create_research_plan(
state: AgentState, *, config: RunnableConfig
) -> dict[str, list[str] | str]:
"""Create a step-by-step research plan for answering an environmental-related query.
Args:
state (AgentState): The current state of the agent, including conversation history.
config (RunnableConfig): Configuration with the model used to generate the plan.
Returns:
dict[str, list[str]]: A dictionary with a 'steps' key containing the list of research steps.
"""
class Plan(TypedDict):
"""Generate research plan."""
steps: list[str]
model = ChatOpenAI(model=GPT_4o_MINI, temperature=TEMPERATURE, streaming=True)
messages = [
{"role": "system", "content": RESEARCH_PLAN_SYSTEM_PROMPT}
] + state.messages
logging.info("---PLAN GENERATION---")
response = cast(Plan, await model.with_structured_output(Plan).ainvoke(messages))
return {"steps": response["steps"], "documents": "delete"}Output example for the query “Retrieve the PUE (Power Usage Effectiveness) efficiency value for data centers specifically in Dublin for the year 2019 using statistical data sources.”:
{
"steps":
["Look up the PUE (Power Usage Effectiveness) efficiency value for data centers specifically in Dublin for the year 2019 using statistical data sources."]
}In this case, the user’s request only requires one step to retrieve information.
Step 3: Conduct Research
This function takes the first step from the research plan and uses it to conduct research. For the research, this function calls the subgraph <span>researcher_graph</span>, returning a list of chunks that we will explore in the next section. Finally, we update the <span>steps</span> variable in the state by removing the step that was just executed.
async def conduct_research(state: AgentState) -> dict[str, Any]:
"""Execute the first step of the research plan.
This function takes the first step from the research plan and uses it to conduct research.
Args:
state (AgentState): The current state of the agent, including the research plan steps.
Returns:
dict[str, list[str]]: A dictionary with 'documents' containing the research results and
'steps' containing the remaining research steps.
Behavior:
- Invokes the researcher_graph with the first step of the research plan.
- Updates the state with the retrieved documents and removes the completed step.
"""
result = await researcher_graph.ainvoke({"question": state.steps[0]}) #graph call directly
docs = result["documents"]
step = state.steps[0]
logging.info(f"\n{len(docs)} documents retrieved in total for the step: {step}.")
return {"documents": result["documents"], "steps": state.steps[1:]}Step 4: Researcher Subgraph Construction
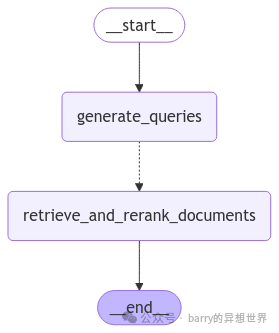
As shown in the figure above, the graph consists of a query generation step, starting from the steps passed from the main graph, and a step for retrieving relevant chunks. Similar to the main graph, we continue to define the state <span>QueryState</span> (the private state of the <span>retrieve_documents</span> node in the researcher graph) and <span>ResearcherState</span> (the state of the researcher graph).
"""States for the researcher subgraph.
This module defines the state structures used in the researcher subgraph.
"""
from dataclasses import dataclass, field
from typing import Annotated
from langchain_core.documents import Document
from utils.utils import reduce_docs
dataclass(kw_only=True)
class QueryState:
"""Private state for the retrieve_documents node in the researcher graph."""
query: str
dataclass(kw_only=True)
class ResearcherState:
"""State of the researcher graph / agent."""
question: str
"""A step in the research plan generated by the retriever agent."""
queries: list[str] = field(default_factory=list)
"""A list of search queries based on the question that the researcher generates."""
documents: Annotated[list[Document], reduce_docs] = field(default_factory=list)
"""Populated by the retriever. This is a list of documents that the agent can reference."""Step 4.1: Generate Queries
This step generates search queries based on the question (a step in the research plan). This function uses LLM to generate diverse search queries to help answer the question.
async def generate_queries(
state: ResearcherState, *, config: RunnableConfig
) -> dict[str, list[str]]:
"""Generate search queries based on the question (a step in the research plan).
This function uses a language model to generate diverse search queries to help answer the question.
Args:
state (ResearcherState): The current state of the researcher, including the user's question.
config (RunnableConfig): Configuration for generating queries.
Returns:
dict[str, list[str]]: A dictionary containing a 'queries' key with the list of generated search queries.
"""
class Response(TypedDict):
queries: list[str]
logger.info("---Generating Queries---")
model = ChatOpenAI(model="gpt-4o-mini-2024-07-18", temperature=0)
messages = [
{"role": "system", "content": GENERATE_QUERIES_SYSTEM_PROMPT},
{"role": "human", "content": state.question},
]
response = cast(Response, await model.with_structured_output(Response).ainvoke(messages))
queries = response["queries"]
queries.append(state.question)
logger.info(f"Queries: {queries}")
return {"queries": response["queries"]}Output example for the query “Retrieve the PUE efficiency values of the Singapore second facility in 2019 and 2022. At the same time, retrieve the regional average CFE in Asia Pacific for 2023.”:
{
"queries":[
"Find the PUE (Power Usage Effectiveness) efficiency values for the Singapore second facility in 2019 and 2022 using statistical data sources.",
"PUE efficiency values Data center Singapore 2019",
"Power Usage Effectiveness statistics Data center Singapore 2019"
]
}Once the queries are generated, we can define the vector store using the previously defined persistent database.
def _setup_vectorstore() -> Chroma:
"""Set up and return an instance of Chroma vector store."""
embeddings = OpenAIEmbeddings()
return Chroma(
collection_name=VECTORSTORE_COLLECTION,
embedding_function=embeddings,
persist_directory=VECTORSTORE_DIRECTORY
)In the RAG system, the most critical part is the document retrieval process. Therefore, special attention is paid to the techniques used: specifically, the hybrid retriever was chosen as Hybrid Search and Cohere for reordering.
Hybrid Search is a combination of “keyword-style” search and “vector-style” search. It has the advantages of conducting keyword searches and utilizing embeddings and vector searches for semantic searching. The integrated retriever is a retrieval algorithm designed to enhance the performance of information retrieval by combining the strengths of multiple individual retrievers. This approach is known as “ensemble retrieval”, which reorders and merges results from different retrievers using a method called reciprocal ranking fusion, providing more accurate and relevant results than any single retriever.
### Create base retrievers
retriever_bm25 = BM25Retriever.from_documents(documents, search_kwargs={"k": TOP_K})
retriever_vanilla = vectorstore.as_retriever(search_type="similarity", search_kwargs={"k": TOP_K})
retriever_mmr = vectorstore.as_retriever(search_type="mmr", search_kwargs={"k": TOP_K})
ensemble_retriever = EnsembleRetriever(
retrievers=[retriever_vanilla, retriever_mmr, retriever_bm25],
weights=ENSEMBLE_WEIGHTS,
)Reordering is a technique that can be used to improve the performance of the RAG pipeline. It is a very powerful method that can significantly enhance the effectiveness of search systems. In short, reordering takes a query and a response and outputs a relevance score. In this way, any search system can display multiple documents that may contain the answer to the query, and then reorder them using the reordering endpoint.
But: Why do we need a reordering step?
To address accuracy issues, a two-stage retrieval was adopted as a means to improve search quality. In these two-stage systems, the first-stage model (the integrated retriever) retrieves a set of candidate documents from a larger dataset. Then, the second-stage model (the reordering model) reorders the documents retrieved by the first-stage model. Additionally, reordering models, such as Cohere Rerank, are models that output similarity scores when given a query and document pair. This score can be used to reorder documents most relevant to the search query. In the reordering approach, the Cohere Rerank model stands out for its ability to significantly enhance search accuracy. The model deviates from traditional embedding models by directly assessing the alignment between each document and the query using deep learning. Cohere Rerank achieves a more nuanced document selection process by simultaneously processing the query and document outputs for relevance scores.(For complete reference see)
In this case, the retrieved documents are reordered to return the top two most relevant documents.
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
### Set up Cohere reordering
compressor = CohereRerank(top_n=2, model="rerank-english-v3.0")
### Build compression retriever
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=ensemble_retriever,
)
compression_retriever.invoke(
"Retrieve the PUE efficiency values of the Dublin data center in 2019"
)Output example for the query “Retrieve the PUE efficiency values of the Dublin data center in 2019”::
[Document(metadata={'Header 2': 'Endnotes', 'relevance_score': 0.27009502}, page_content="- 1 This calculation is based on..."),
Document(metadata={'Header 2': 'Data Center Grid Region CFE', 'relevance_score': 0.20593424}, page_content="2023
| Country..." )]Step 4.2: Retrieve and Rerank Documents Function
async def retrieve_and_rerank_documents(
state: QueryState, *, config: RunnableConfig
) -> dict[str, list[Document]]:
"""Retrieve documents based on a given query.
This function uses a retriever to fetch relevant documents for a given query.
Args:
state (QueryState): The current state containing the query string.
config (RunnableConfig): Configuration with the retriever used to fetch documents.
Returns:
dict[str, list[Document]]: A dictionary with a 'documents' key containing the list of retrieved documents.
"""
logger.info("---RETRIEVING DOCUMENTS---")
logger.info(f"Query for the retrieval process: {state.query}")
response = compression_retriever.invoke(state.query)
return {"documents": response}Step 4.3: Build Subgraph
builder = StateGraph(ResearcherState)
builder.add_node(generate_queries)
builder.add_node(retrieve_and_rerank_documents)
builder.add_edge(START, "generate_queries")
builder.add_conditional_edges(
"generate_queries",
retrieve_in_parallel, # type: ignore
path_map=["retrieve_and_rerank_documents"],
)
builder.add_edge("retrieve_and_rerank_documents", END)
researcher_graph = builder.compile()Step 5: Check Completion
Using <span>conditional_edge</span>, we build a loop whose end condition is determined by the value returned by <span>check_finished</span>. This function checks whether there are any remaining steps in the list of steps created by the <span>create_research_plan</span> node that need to be processed. Once all steps are completed, the flow will continue to the <span>respond</span> node.
def check_finished(state: AgentState) -> Literal["respond", "conduct_research"]:
"""Determine if the research process is complete or if more research is needed.
This function checks if there are any remaining steps in the research plan:
- If there are, route back to the `conduct_research` node
- Otherwise, route to the `respond` node
Args:
state (AgentState): The current state of the agent, including the remaining research steps.
Returns:
Literal["respond", "conduct_research"]: The next step to take based on whether research is complete.
"""
if len(state.steps or []) > 0:
return "conduct_research"
else:
return "respond"Step 6: Respond
Generate the final response to the user’s query based on the conducted research. This function utilizes the conversation history and the documents retrieved by the researcher to formulate a comprehensive answer.
async def respond(
state: AgentState, *, config: RunnableConfig
) -> dict[str, list[BaseMessage]]:
"""Generate a final response to the user's query based on the conducted research.
This function formulates a comprehensive answer using the conversation history and the documents retrieved by the researcher.
Args:
state (AgentState): The current state of the agent, including retrieved documents and conversation history.
config (RunnableConfig): Configuration with the model used to respond.
Returns:
dict[str, list[str]]: A dictionary with a 'messages' key containing the generated response.
"""
print("--- RESPONSE GENERATION STEP ---")
model = ChatOpenAI(model="gpt-4o-2024-08-06", temperature=0)
context = format_docs(state.documents)
prompt = RESPONSE_SYSTEM_PROMPT.format(context=context)
messages = [{"role": "system", "content": prompt}] + state.messages
response = await model.ainvoke(messages)
return {"messages": [response]} Step 7: Check for Hallucinations
This step checks whether the LLM response generated in the previous step is supported by the set of facts in the retrieved documents, providing a binary scoring.
async def check_hallucinations(
state: AgentState, *, config: RunnableConfig
) -> dict[str, Any]:
"""Analyze the user's query and check if the response is supported by the set of facts in the retrieved documents,
providing binary scoring results.
This function uses a language model to analyze the user's query and provides binary scoring results.
Args:
state (AgentState): The current state of the agent, including conversation history.
config (RunnableConfig): Configuration for query analysis.
Returns:
dict[str, Router]: A dictionary containing the 'router' key and classification results (classification type and logic).
"""
model = ChatOpenAI(model=GPT_4o_MINI, temperature=TEMPERATURE, streaming=True)
system_prompt = CHECK_HALLUCINATIONS.format(
documents=state.documents,
generation=state.messages[-1]
)
messages = [
{"role": "system", "content": system_prompt}
] + state.messages
logging.info("---Checking Hallucinations---")
response = cast(GradeHallucinations, await model.with_structured_output(GradeHallucinations).ainvoke(messages))
return {"hallucination": response}Step 8: Human Approval (Human-Machine Collaboration)
If the LLM’s response does not align with the set of facts, it may contain hallucinations. In this case, the graph will interrupt, allowing the user to control the next step: either retry the last generation step without restarting the entire workflow or terminate the process. This human-machine collaboration step ensures user control while avoiding unintended loops or undesirable actions.
The interrupt function in LangGraph enables human-machine collaboration workflows by pausing the graph at specific nodes, presenting information to humans, and resuming the graph based on their input. This function is suitable for tasks such as approval, editing, or gathering additional input. The interrupt function works in conjunction with the Comm object to resume the graph based on values provided by humans.
def human_approval(
state: AgentState,
):
_binary_score = state.hallucination.binary_score
if _binary_score == "1":
return "END"
else:
retry_generation = interrupt(
{
"question": "Is this correct?",
"llm_output": state.messages[-1]
})
if retry_generation == "y":
print("I want to continue")
return "respond"
else:
return "END"
4.3 Build Main Graph
from langgraph.graph import END, START, StateGraph
from langgraph.checkpoint.memory import MemorySaver
checkpointer = MemorySaver()
builder = StateGraph(AgentState, input=InputState)
builder.add_node(analyze_and_route_query)
builder.add_edge(START, "analyze_and_route_query")
builder.add_conditional_edges("analyze_and_route_query", route_query)
builder.add_node(create_research_plan)
builder.add_node(ask_for_more_info)
builder.add_node(respond_to_general_query)
builder.add_node(conduct_research)
builder.add_node("respond", respond)
builder.add_node(check_hallucinations)
builder.add_conditional_edges("check_hallucinations", human_approval, {"END": END, "respond": "respond"})
builder.add_edge("create_research_plan", "conduct_research")
builder.add_conditional_edges("conduct_research", check_finished)
builder.add_edge("respond", "check_hallucinations")
graph = builder.compile(checkpointer=checkpointer)Build Main Function (app.py)
“Each function is defined as <span>async</span> to enable streaming behavior during generation steps.”
from subgraph.graph_states import ResearcherState
from main_graph.graph_states import AgentState
from utils.utils import config, new_uuid
from subgraph.graph_builder import researcher_graph
from main_graph.graph_builder import InputState, graph
from langgraph.types import Command
import asyncio
import uuid
import asyncio
import time
import builtins
thread = {"configurable": {"thread_id": new_uuid()}}
async def process_query(query):
inputState = InputState(messages=query)
async for c, metadata in graph.astream(input=inputState, stream_mode="messages", config=thread):
if c.additional_kwargs.get("tool_calls"):
print(c.additional_kwargs.get("tool_calls")[0]["function"].get("arguments"), end="", flush=True)
if c.content:
time.sleep(0.05)
print(c.content, end="", flush=True)
if len(graph.get_state(thread)[-1]) > 0:
if len(graph.get_state(thread)[-1][0].interrupts) > 0:
response = input("\nThe response may contain uncertain information. Would you like to retry generation? If so, press 'y': ")
if response.lower() == 'y':
async for c, metadata in graph.astream(Command(resume=response), stream_mode="messages", config=thread):
if c.additional_kwargs.get("tool_calls"):
print(c.additional_kwargs.get("tool_calls")[0]["function"].get("arguments"), end="")
if c.content:
time.sleep(0.05)
print(c.content, end="", flush=True)
async def main():
input = builtins.input
print("Please enter your query (type '-q' to exit):")
while True:
query = input("> ")
if query.strip().lower() == "-q":
print("Exiting...")
break
await process_query(query)
if __name__ == "__main__":
asyncio.run(main())After the first call, the graph state checks for interruptions. If any interruptions are found, the graph can be called again using the following command:
graph.astream(Command(resume=response), stream_mode="messages", config=thread)In this way, the workflow will resume from the interrupted step without re-executing the previous steps, using the same <span>thread_id</span>.
3. Results
For the following test, the annual report on Google’s environmental sustainability strategy was used, which is available for free here.
Live Testing
As the first test, the following query was executed to extract different values from different tables, combining the multi-step approach capabilities and leveraging the parsing capabilities of the Docling library.
Complex question: “Retrieve the PUE efficiency values of the second facility in Singapore for 2019 and 2022. At the same time, retrieve the regional average CFE for the Asia Pacific region in 2023.”
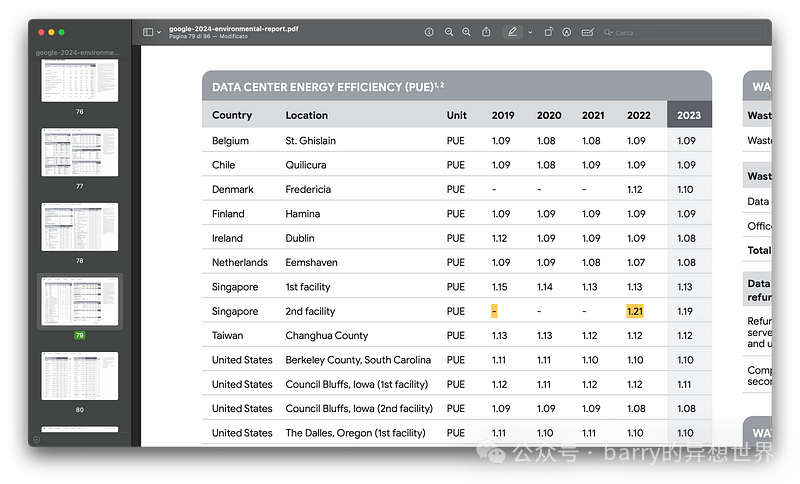
The complete result is correct, and the hallucination check has been successfully passed.
The steps generated by the chatbot:
-
• “Look up the PUE efficiency values for the second facility in Singapore for 2019 and 2022.”, -
• “Look up the regional average CFE for the Asia Pacific in 2023.”
The generated text: *“- The PUE (Power Usage Effectiveness) for the second facility in Singapore in 2019 is unavailable as data for that year was not provided. However, the PUE for 2022 is 1.21.”
“The regional average CFE for the Asia Pacific in 2023 is 12%.”
Complete Output:
请输入您的查询(输入 '-q' 以退出):
> Retrieve the PUE efficiency values of the second facility in Singapore for 2019 and 2022. At the same time, retrieve the regional average CFE in Asia Pacific for 2023
2025-01-10 20:39:53,381 - INFO - ---Analyzing and Routing Query---
2025-01-10 20:39:53,381 - INFO - Messages: [HumanMessage(content='Retrieve the data center PUE efficiency values in Singapore 2nd facility in 2019 and 2022. Also retrieve regional average CFE in Asia pacific in 2023 ', additional_kwargs={}, response_metadata={}, id='351a00e9-ecda-49e2-b069-19196348a82a')]
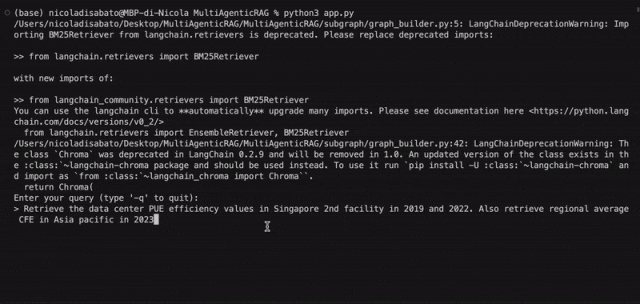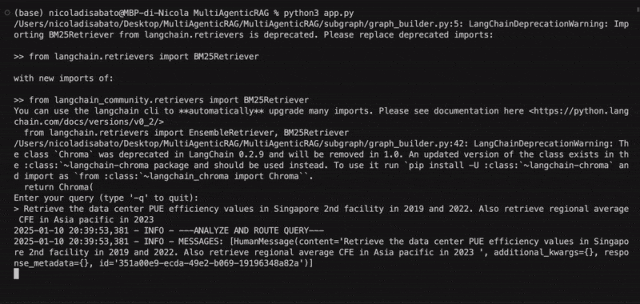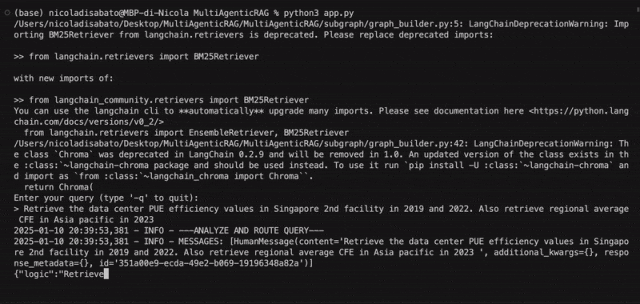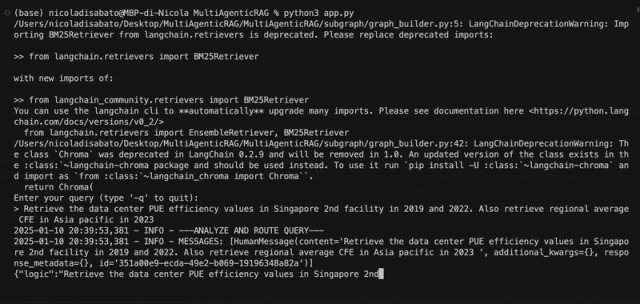
{"logic":"Retrieve the data center PUE efficiency values in Singapore 2nd facility in 2019 and 2022. Also retrieve regional average CFE in Asia pacific in 2023","type":"environmental"}2025-01-10 20:39:55,586 - INFO - ---Plan Generation---
{"steps":["Look up the PUE (Power Usage Effectiveness) efficiency value for data centers specifically in Singapore for the year 2019 using statistical data sources.","Look up the regional average CFE in Asia pacific for the year 2023."]}
2025-01-10 20:39:57,323 - INFO - ---Generating Queries---
{"queries":["Retrieve the PUE efficiency values in Singapore 2nd facility in 2019 and 2022 using statistical data sources.","PUE efficiency values Data center Singapore 2019","PUE efficiency values Data center Singapore 2022"]}
2025-01-10 20:39:58,285 - INFO - Queries: ['PUE efficiency values Singapore 2nd facility 2019', 'PUE efficiency values Singapore 2nd facility 2022', 'Retrieve the PUE efficiency values in Singapore 2nd facility in 2019 and 2022.']
2025-01-10 20:39:58,288 - INFO - ---Retrieving Documents---
2025-01-10 20:39:58,288 - INFO - Retrieval process query: Retrieve the PUE efficiency values in Singapore 2nd facility 2019
2025-01-10 20:39:59,568 - INFO - ---Retrieving Documents---
2025-01-10 20:39:59,568 - INFO - Retrieval process query: Retrieve the PUE efficiency values in Singapore 2nd facility 2022
2025-01-10 20:40:00,891 - INFO - ---Retrieving Documents---
2025-01-10 20:40:00,891 - INFO - Retrieval process query: Retrieve the PUE efficiency values in Singapore 2nd facility in 2019 and 2022.
2025-01-10 20:40:01,820 - INFO -
Total of 4 documents retrieved in total for the step: Look up the PUE efficiency values for the second facility in Singapore for 2019 and 2022.
2025-01-10 20:40:01,825 - INFO - ---Generating Queries---
{"queries":["Retrieve the regional average CFE for the Asia Pacific in 2023.","Retrieve the CFE statistics for the Asia Pacific in 2023."]}
2025-01-10 20:40:02,778 - INFO - Queries: ['Retrieve the regional average CFE for the Asia Pacific in 2023.', 'Retrieve the CFE statistics for the Asia Pacific in 2023.', 'Look up the regional average CFE for the Asia Pacific in 2023.']
2025-01-10 20:40:02,780 - INFO - ---Retrieving Documents---
2025-01-10 20:40:02,780 - INFO - Retrieval process query: Retrieve the regional average CFE for the Asia Pacific in 2023.
2025-01-10 20:40:03,757 - INFO - ---Retrieving Documents---
2025-01-10 20:40:03,757 - INFO - Retrieval process query: Retrieve the CFE statistics for the Asia Pacific in 2023.
2025-01-10 20:40:04,885 - INFO - ---Retrieving Documents---
2025-01-10 20:40:04,885 - INFO - Retrieval process query: Look up the regional average CFE for the Asia Pacific in 2023.
2025-01-10 20:40:06,526 - INFO -
Total of 4 documents retrieved in total for the step: Look up the regional average CFE for the Asia Pacific in 2023.
2025-01-10 20:40:06,530 - INFO - ---Response Generation Step---
- The PUE (Power Usage Effectiveness) for the second facility in Singapore in 2019 is unavailable as data for that year was not provided. However, the PUE for 2022 is 1.21.
- The regional average CFE for the Asia Pacific in 2023 is 12%.
2025-01-10 20:40:14,918 - INFO - ---Checking Hallucinations---
{"binary_score":"1"} > 4. Conclusion
Agentic RAG: Technical Challenges and Considerations
Despite performance improvements, implementing Agentic RAG is not without challenges:
-
• Latency: The complexity of agent interactions often leads to longer response times. Achieving a balance between speed and accuracy is a key challenge. -
• Evaluation and Observability: As Agentic RAG systems become more complex, continuous evaluation and observability become necessary.
In summary, Agentic RAG marks a significant breakthrough in the field of artificial intelligence. By combining the capabilities of large language models with autonomous reasoning and information retrieval, Agentic RAG introduces a new standard of intelligence and flexibility. As AI continues to evolve, Agentic RAG will play a foundational role across industries, transforming the way we use technology.
Github Repo is here!!
References:
https://github.com/DS4SD/docling
