
Click on the above“Beginner Learning Vision” to select “Add to Favorites” or “Pin”
Heavyweight content delivered first hand
Heavyweight content delivered first hand1 Background Introduction
Object detection, or object detection, is to accurately find the location of objects in a given image and label the categories of those objects.
The object detection problem has two main issues: where the object is and what the object is.
The challenges of object detection include: the size of the objects can vary greatly; the angles and poses of the objects can be unpredictable; they can appear anywhere in the image; and the objects can belong to multiple categories.
Currently, the main algorithms are divided into two categories: 1) Region Proposal/Box + Deep Learning Classification; 2) Regression methods based on Deep Learning.
A significant part of the work in object detection is image classification. When it comes to image classification, one cannot overlook the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC), where the machine learning guru Professor Geoffrey Hinton and his student Krizhevsky used convolutional neural networks to reduce the Top-5 error rate of the ILSVRC classification task to 15.3%, while the second place using traditional methods had a Top-5 error rate of 26.2%.
Since then, Convolutional Neural Networks (CNN) have dominated the image classification task.
2 Region Proposal + Deep Learning
By extracting candidate regions and classifying the corresponding areas primarily using deep learning methods, such as:
2.1 R-CNN (Selective Search + CNN + SVM)
First, identify the possible locations of objects in the image, which are the candidate regions (Region Proposals).
By utilizing information such as texture, edges, and colors in the image, it is possible to maintain a high recall rate with a limited number of windows (thousands or even hundreds).
With candidate regions identified, the remaining work is essentially image classification of these regions (feature extraction + classification).
In 2014, RBG (Ross B. Girshick) replaced the traditional sliding window + hand-crafted features used in object detection with Region Proposal + CNN, designing the R-CNN framework, which led to a significant breakthrough in object detection and initiated a wave of deep learning-based object detection.
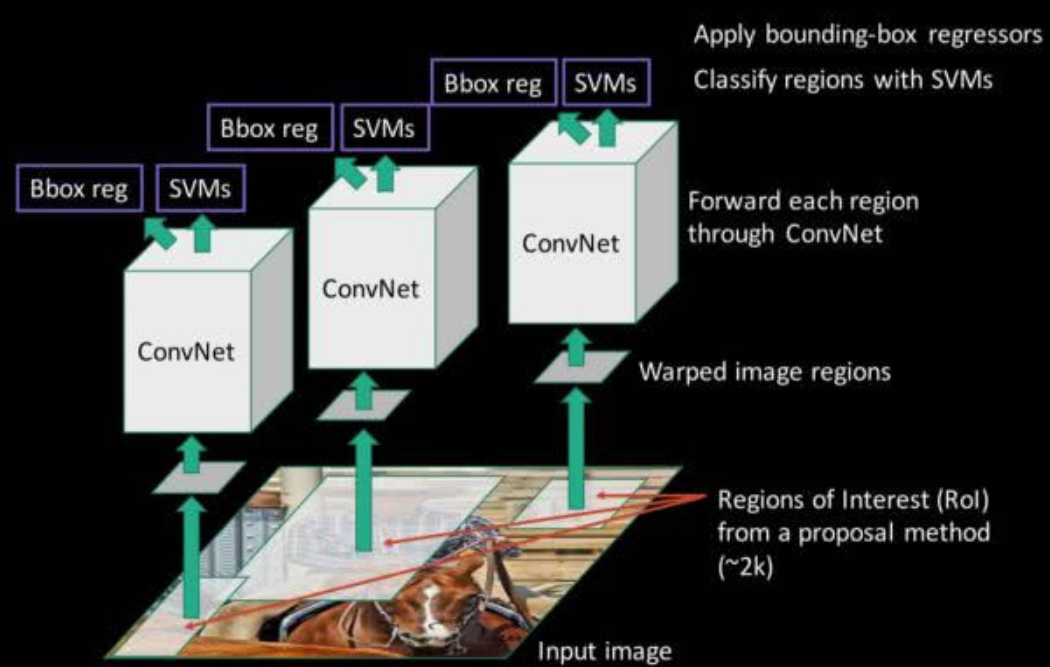
The brief steps of R-CNN are as follows:
-
Input the test image
-
Use the Selective Search algorithm to extract about 2000 candidate regions (Region Proposals) from the image
-
Since the extracted regions vary in size, each Region Proposal needs to be warped to a uniform size of 227×227 and input into the CNN, using the output of the CNN’s fc7 layer as features
-
Input the CNN features extracted from each Region Proposal into the SVM for classification
R-CNN has a significant issue: although it no longer exhaustively searches like traditional methods, the first step of the R-CNN process involves extracting about 2000 candidate boxes through Selective Search from the original image, and each of these 2000 candidate boxes requires CNN feature extraction + SVM classification, resulting in a large computational load and making R-CNN very slow, taking 47 seconds for one image.
2.2 SPP-net (ROI Pooling)
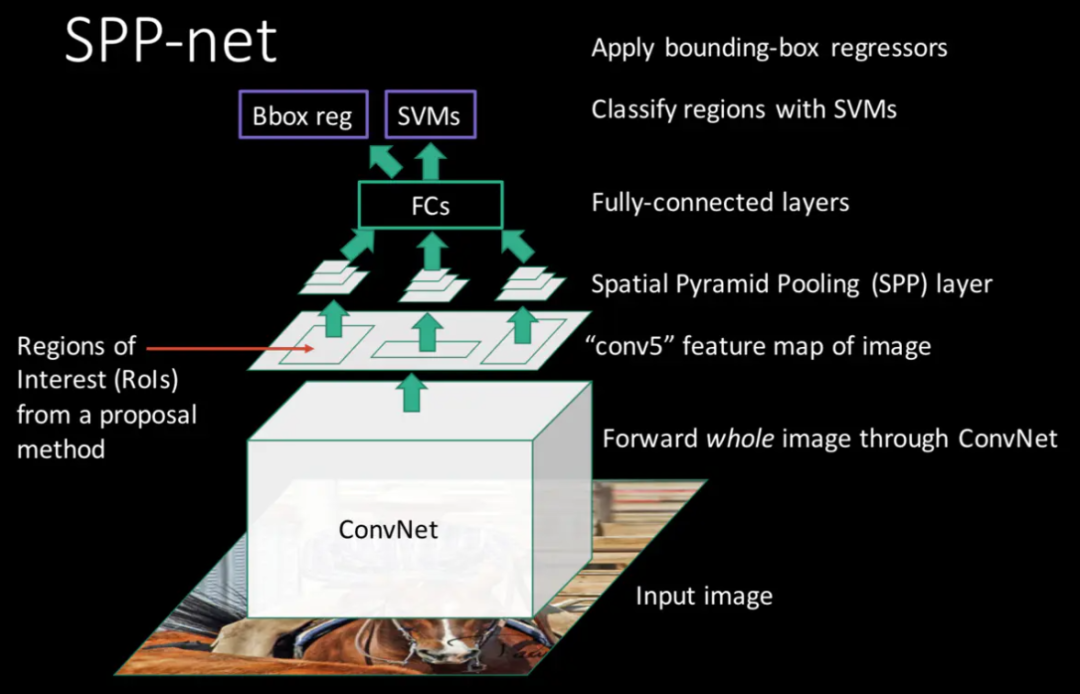
SPP: Spatial Pyramid Pooling
SPP-Net is derived from a paper published in IEEE in 2015 titled “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition”
2.3 Fast R-CNN (Selective Search + CNN + ROI)
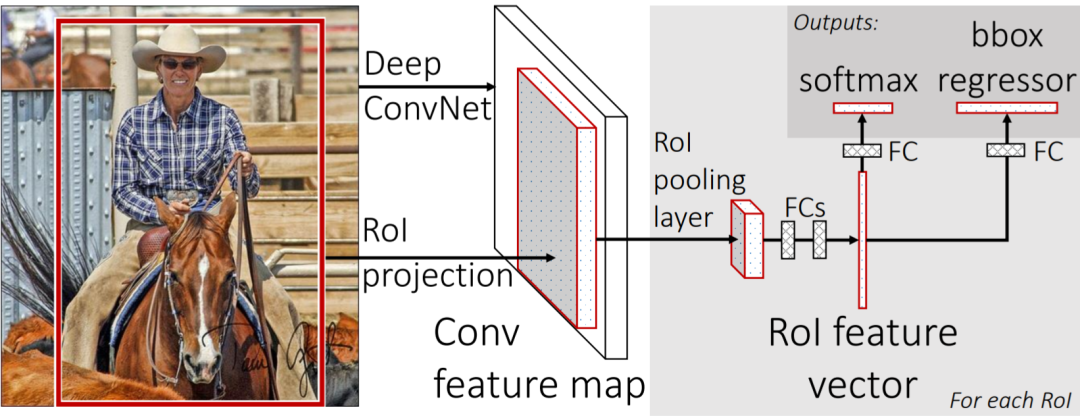
Fast R-CNN is an improvement on the R-CNN framework that adopts the SPP Net method, further enhancing performance.
Comparing with the R-CNN framework diagram, there are two main differences: one is the addition of a ROI pooling layer after the last convolutional layer, and the other is the use of a multi-task loss function that directly incorporates Bounding Box Regression into the training of the CNN network.
A significant contribution of Fast R-CNN is that it successfully demonstrated the potential for real-time detection using the Region Proposal + CNN framework, showing that multi-class detection can indeed improve processing speed while maintaining accuracy, paving the way for Faster R-CNN.
2.4 Faster R-CNN (RPN + CNN + ROI)
https://arxiv.org/pdf/1506.01497.pdf
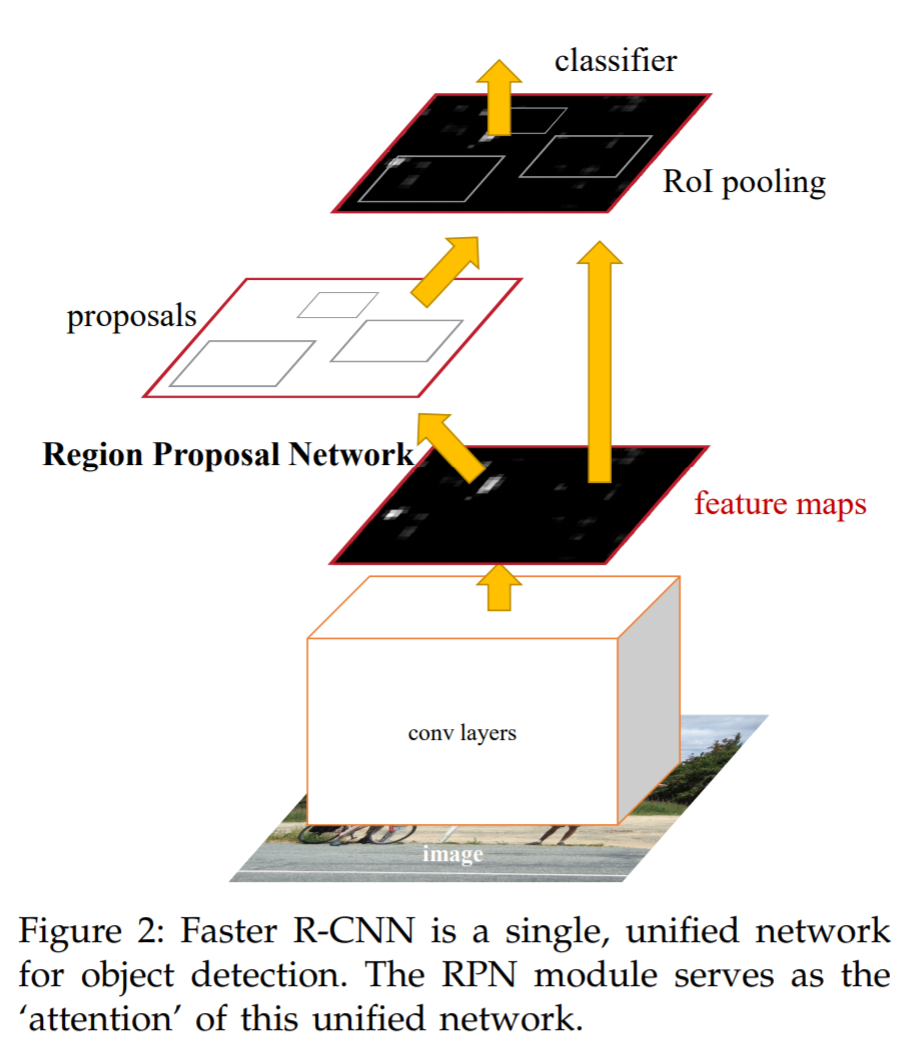
Fast R-CNN has performance bottlenecks: Selective Search to find all candidate boxes is also very time-consuming. Is there a more efficient way to find these candidate boxes?
The solution: introduce a neural network to extract edges, meaning that the task of finding candidate boxes is also handed over to the neural network.
All four algorithms are based on the region proposal R-CNN series, which is a major branch in the field of object detection technology.
3 Regression Methods Based on Deep Learning
3.1 YOLO1
YOLO, which stands for: You Only Look Once

The R-CNN series introduced above is difficult to meet real-time requirements. Methods like YOLO have gradually shown their importance, using a regression approach, taking the entire image as input to the network and directly regressing the target bounding box and the category of the target at multiple positions in the image.
YOLO transforms the object detection task into a regression problem, greatly speeding up detection, allowing YOLO to process 45 images per second. Moreover, since each network predicts target windows using full image information, the false positive rate is significantly reduced (due to sufficient contextual information).
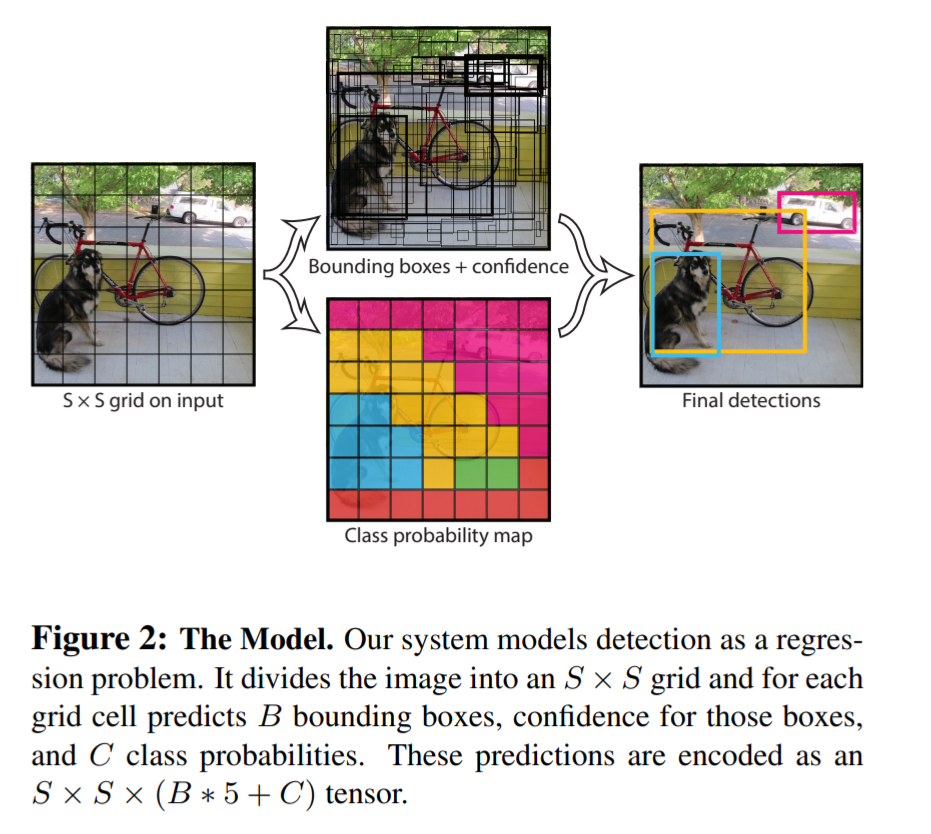

However, YOLO also has issues: without the Region Proposal mechanism, using only 7*7 grid regression can make it difficult to accurately locate targets, resulting in lower detection accuracy for YOLO.
3.2 YOLO2
https://arxiv.org/pdf/1612.08242.pdf

YOLOv2, compared to version v1, improves in three aspects while maintaining processing speed: Better (more accurate predictions), Faster (speed improvements), and Stronger (can recognize more objects), extending its detection capabilities to 9000 different objects, known as YOLO9000.
YOLO v2 represents a relatively advanced level of object detection, outperforming other detection systems across various monitoring datasets, allowing for a trade-off between speed and accuracy.
3.3 YOLO3
https://pjreddie.com/media/files/papers/YOLOv3.pdf

The YOLO v3 model is significantly more complex than previous models, allowing for a trade-off between speed and accuracy by altering the model structure size.
In terms of speed, YOLOv3 is significantly faster than other detection methods while achieving the same accuracy.
Improvements include:
1). Multi-scale predictions (similar to FPN)
2). A better base classification network (similar to ResNet) and classifier darknet-53, as shown below.
3). Classifier-category predictions:
YOLOv3 does not use Softmax for classification for each box, mainly for two reasons:
a. Softmax assigns one category (the one with the highest score) to each box, while datasets like Open Images may have overlapping category labels, making Softmax unsuitable for multi-label classification.
b. Softmax can be replaced by multiple independent logistic classifiers without a decrease in accuracy.
The classification loss uses binary cross-entropy loss.
Multi-scale predictions

Each scale predicts 3 boxes, and the anchor design still uses clustering to obtain 9 cluster centers, which are evenly distributed among 3 scales.
-
Scale 1: Adds several convolutional layers after the base network to output box information.
-
Scale 2: Upsamples (x2) from the second-to-last convolutional layer of Scale 1 and adds it to the last feature map of size 16×16, followed by several convolutions to output box information, effectively doubling the size compared to Scale 1.
-
Scale 3: Similar to Scale 2, using a feature map of size 32×32.
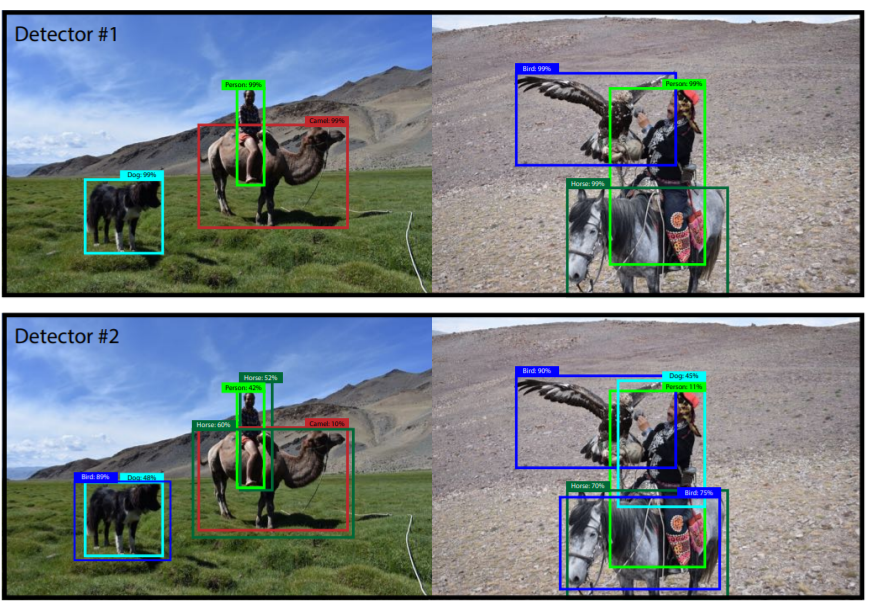
4 Conclusion
Finally, summarizing the differences between the two types of algorithms:
-
RCNN, Fast-RCNN, and Faster-RCNN are classification methods based on deep learning. -
The YOLO series is a regression method based on deep learning.
This article is a summary of my learning on object detection during my spare time, and I hope it helps beginners in object detection. (Source: Programmer Guo Zhenzhenguo)
Disclaimer: Some content comes from the internet and is for educational and communication purposes only. The copyright of the article belongs to the original author. If there are any issues, please contact for removal.
Group Chat
Welcome to join the reader group of the public account for communication with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions and more (which will gradually be subdivided), please scan the WeChat ID below to join the group, and note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format for remarks, otherwise, you will not be approved. After successfully adding, you will be invited to enter relevant WeChat groups based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group. Thank you for your understanding~

