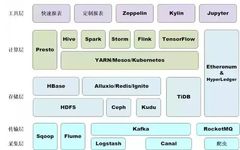
Review: Big Data Platform Technology Stack (ps: Click to view), today we will talk about TensorFlow!
Source: Zhihu, Author: He Zhiyuan
During the learning process of TensorFlow, many friends have reflected that reading data is quite difficult to understand. Indeed, the official tutorial on this is relatively brief, and there aren’t many suitable learning materials online. This article will explain TensorFlow’s data reading mechanism in detail with images and simple language, and at the end of the article, practical code will be provided for reference.
1. TensorFlow Data Reading Mechanism Illustrated
The first question to consider is, what is data reading? Taking image data as an example, the process of reading data can be represented as follows:
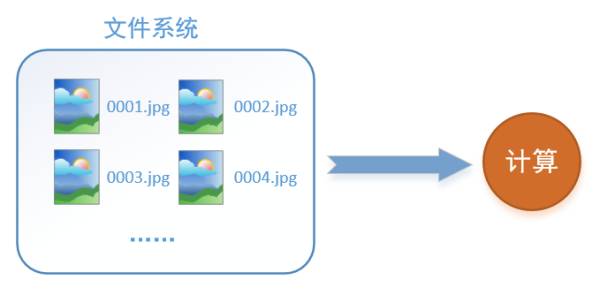
Assuming we have an image dataset on our hard drive: 0001.jpg, 0002.jpg, 0003.jpg… We just need to read them into memory and provide them to the GPU or CPU for computation. This sounds easy, but the reality is far from simple.In fact, we must read the data first before we can compute. Suppose the reading takes 0.1s and the computation takes 0.9s, it means that every second, the GPU will have 0.1s of idle time, which greatly reduces computational efficiency.
How can we solve this problem? The method is to place the reading of data and computation in two separate threads, putting the data read into a memory queue, as shown in the following diagram:
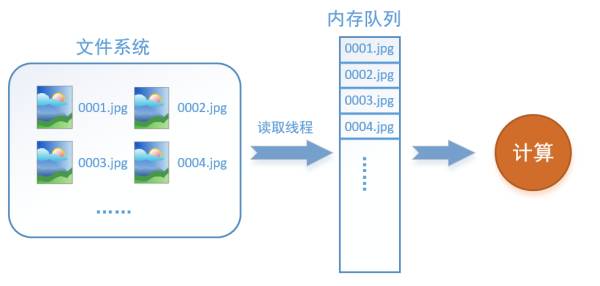
The reading thread continuously reads images from the file system into a memory queue, while another thread is responsible for computation. When the computation needs data, it can directly take it from the memory queue. This solves the problem of the GPU being idle due to I/O!
In TensorFlow, to facilitate management, an additional layer known as the “filename queue” is added in front of the memory queue.
Why add this layer of filename queue? We must first understand a concept in machine learning: epoch. For a dataset, running one epoch means computing all images in that dataset once. For example, if a dataset contains three images A.jpg, B.jpg, C.jpg, then running one epoch means computing A, B, and C once. Two epochs mean computing A, B, and C once each, then computing them all again, which means each image is computed twice.
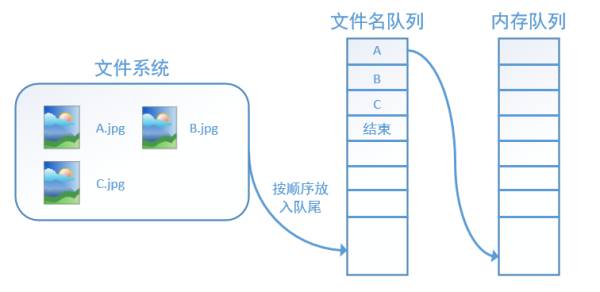
TensorFlow uses a dual-queue mechanism of filename queue + memory queue to read files, which can effectively manage epochs. Below we will illustrate the operation of this mechanism with images. As shown in the figure, still taking the dataset A.jpg, B.jpg, C.jpg as an example, if we want to run one epoch, we will place A, B, C in the filename queue once and then mark the end of the queue.
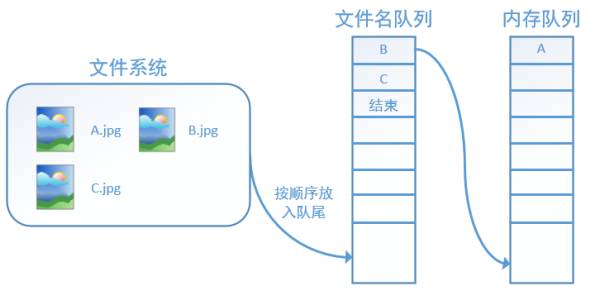
After the program runs, the memory queue first reads A (at this point A is dequeued from the filename queue):
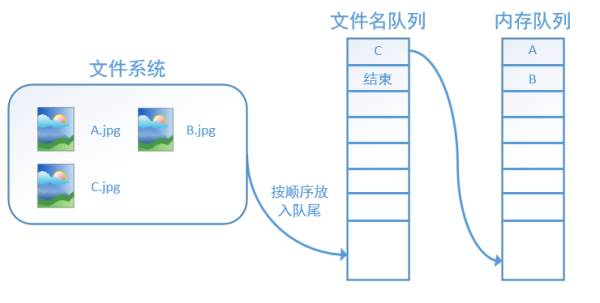
Then read B and C in turn:
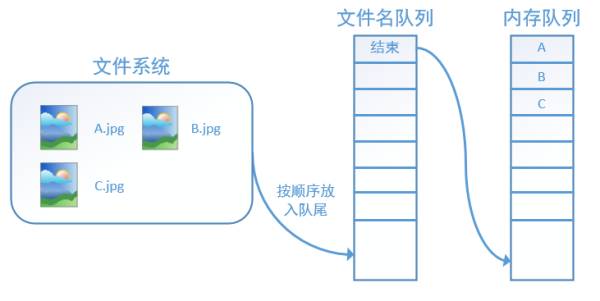
At this point, if we try to read again, the system will automatically throw an exception (OutOfRange) due to detecting “end”. After this exception is caught externally, the program can be terminated. This is the basic mechanism of data reading in TensorFlow. If we want to run 2 epochs instead of 1, we just need to place A, B, C in the filename queue twice and mark the end.
2. Corresponding Functions for TensorFlow Data Reading Mechanism
How do we create the two queues mentioned above in TensorFlow?
For the filename queue, we use the tf.train.string_input_producer function. This function requires a list of filenames as input, and the system will automatically convert it into a filename queue.
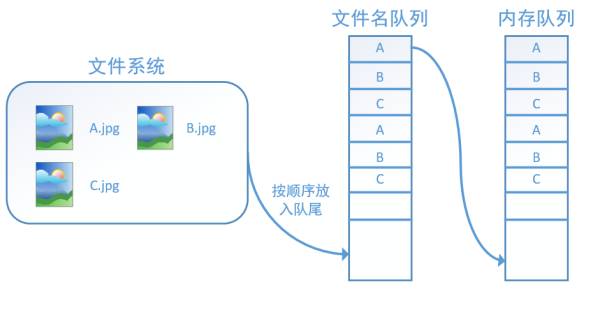
Additionally, tf.train.string_input_producer has two important parameters, one is num_epochs, which refers to the number of epochs mentioned earlier. The other is shuffle, which indicates whether the order of files within an epoch is randomized. If shuffle=False, as shown in the diagram below, within each epoch, the data will still enter the filename queue in the order of A, B, C, and this order will not change:
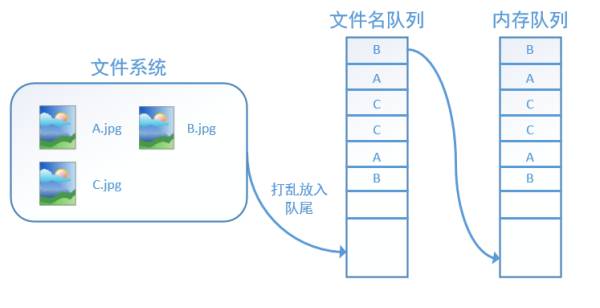
If shuffle=True is set, then within an epoch, the order of the data will be randomized, as shown in the diagram below:
In TensorFlow, we do not need to create the memory queue ourselves; we only need to use the reader object to read data from the filename queue. The specific implementation can refer to the practical code below.
In addition to tf.train.string_input_producer, we also need to introduce an additional function:
tf.train.start_queue_runners. Beginners often see this function in code but find it difficult to understand its purpose. Here, with the above background, we can explain the function’s role.
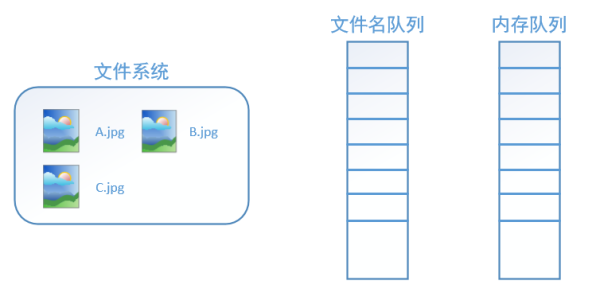
After we create the filename queue using tf.train.string_input_producer, the entire system is actually still in a “stagnation state”; in other words, our filenames have not really been added to the queue (as shown in the diagram below). If we start computing at this point, since the memory queue is empty, the computing unit will keep waiting, causing the entire system to be blocked.
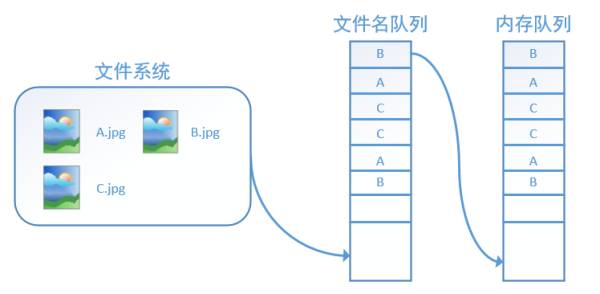
Only after using tf.train.start_queue_runners will the thread that fills the queue be started, and the system will no longer be “stagnant.” Thereafter, the computing unit can access the data and perform calculations, and the entire program will run; this is the purpose of the function tf.train.start_queue_runners.
3. Practical Code
We will feel the data reading in TensorFlow with a specific example. As shown, suppose we already have three images A.jpg, B.jpg, C.jpg in the current folder, and we want to read these three images for 5 epochs and save the results to the read folder.

The corresponding code is as follows:
# Import TensorFlow
import tensorflow as tf
# Create a new Session
with tf.Session() as sess:
# We want to read three images A.jpg, B.jpg, C.jpg
filename = [‘A.jpg’, ‘B.jpg’, ‘C.jpg’]
# string_input_producer will produce a filename queue
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader reads data from the filename queue. The corresponding method is reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer defines an epoch variable, which needs to be initialized
tf.local_variables_initializer().run()
# After using start_queue_runners, the queue filling will begin
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# Get image data and save
image_data = sess.run(value)
with open(‘read/test_%d.jpg’ % i, ‘wb’) as f:
f.write(image_data)
Here we used filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5) to create a filename queue that runs for 5 epochs. The reader reads each image and saves it.
After running the code, we can see the images in the read folder, which are exactly the 5 epochs in order:
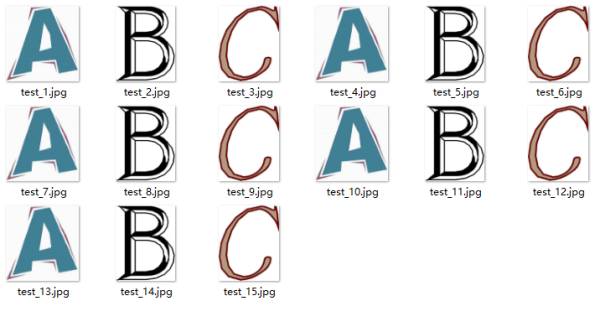
If we set filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5) with shuffle=True, then the images will be shuffled within each epoch, as shown:

We only used three images as an example; in actual applications, a dataset will certainly contain more than three images, but the principles involved are common.
4. Conclusion
This article mainly uses illustrations to detail the mechanism of TensorFlow reading data, and finally provides corresponding practical code, hoping to bring some substantial help to everyone learning TensorFlow. If any friends have questions, feel free to leave a message in the comments section, thank you~
Long press to subscribe for more exciting content ▼

If you have gained something, please give a thumbs up, sincerely thank you