

On November 29, Zhipu officially proposed the concept of GLM-OS and released two agent products: AutoGLM and GLM-PC. To promote the development of the large model agent ecosystem, Zhipu decided to open source the base model of GLM-PC—— CogAgent-9B, for further community development. CogAgent-9B has been launched on the MoLe community for immediate experience!
🔗 Model Link: https://modelers.cn/models/zhipuai/cogagent-9b-20241220 (adapted for Ascend card)
CogAgent-9B-20241220 is a dedicated agent task model trained based on GLM-4V-9B.This model requires only a screenshot as input (no HTML or other text representations) to predict the next GUI operation based on any user-specified task, combined with historical actions. Thanks to the universality of screenshots and GUI operations, CogAgent can be widely applied in various GUI interaction scenarios, such as personal computers, mobile phones, and in-car devices.
Compared to the first version of the CogAgent model open-sourced in December 2023, CogAgent-9B-20241220 has achieved significant improvements in GUI perception, reasoning prediction accuracy, action space completeness, task universality, and generalization, and supports bilingual (Chinese and English) screenshot and language interaction.
CogAgent-9B
Paper:
-
https://arxiv.org/abs/2312.08914
Code:
-
https://github.com/THUDM/CogAgent
Model:
-
Huggingface: https://huggingface.co/THUDM/cogagent-9b-20241220
-
MoLe Community:https://modelers.cn/models/zhipuai/cogagent-9b-20241220 (adapted for Ascend card)
Technical Documentation:
-
https://cogagent.aminer.cn/blog#/articles/cogagent-9b-20241220-technical-report
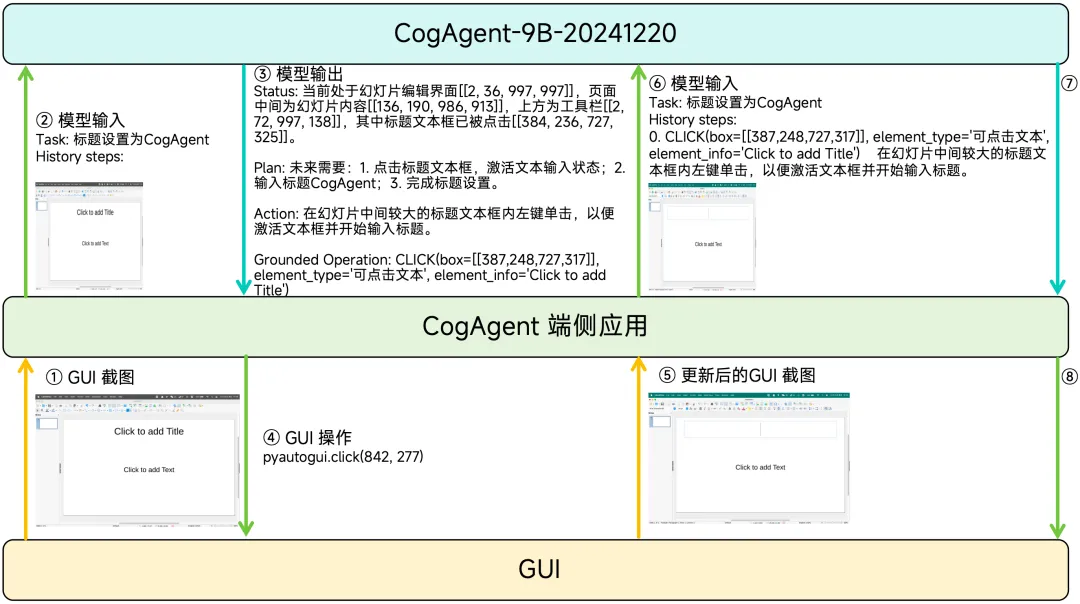
Execution Process
-
Thinking Process (Status & Plan): CogAgent explicitly outputs the understanding of the GUI screenshot and the thinking process for deciding the next action, including status (Status) and plan (Plan), with output content controllable through parameters.
-
Natural Language Description of the Next Action (Action): The natural language description of the action will be added to the historical action record to facilitate the model’s understanding of the executed action steps.
-
Structured Description of the Next Action (Grounded Operation): CogAgent describes the next operation and its parameters in a structured manner similar to a function call, making it easier for the client application to parse and execute the model output. Its action space includes GUI operations (basic actions, such as left-clicking, text input, etc.) and anthropomorphic behaviors (advanced actions, such as launching applications, calling language models, etc.).
-
Sensitivity Judgment of the Next Action: Actions are divided into “general operations” and “sensitive operations”, the latter referring to actions that may lead to irreparable consequences, such as clicking the “send” button in an “email sending” task.
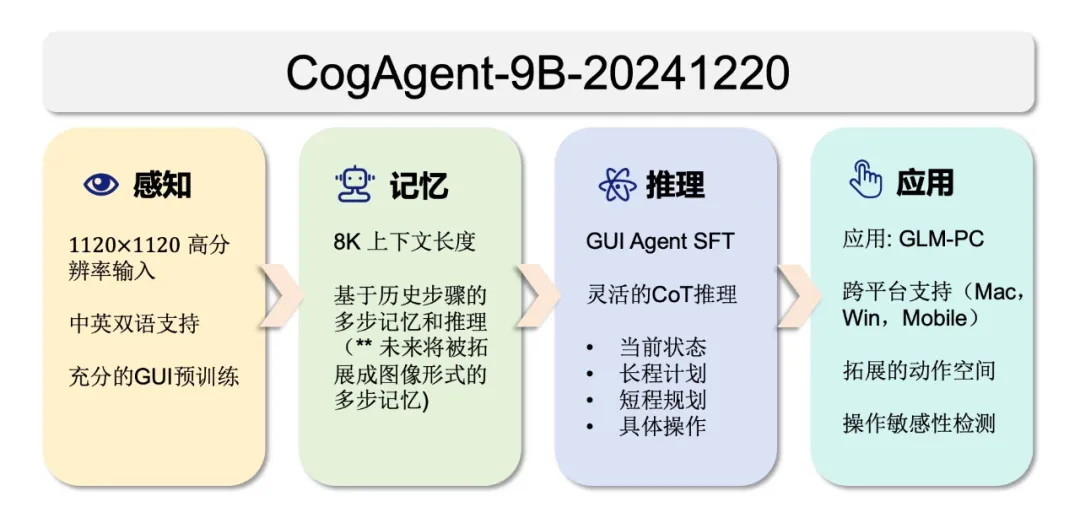
Model Upgrade
-
GUI Referring Expression Generation (REG): Predicting the layout representation corresponding to a certain area on the screenshot.
-
GUI Referring Expression Comprehension (REC): Predicting the position of a certain element in the screenshot. This method has been applied in multiple GUI understanding data constructions and GUI agent work. In the original paper, we used 400,000 web page data to construct 140 million REC & REG training samples. Based on this, we further expanded and optimized the training data, adding layout data from desktop and mobile applications to make the model more adaptable to real application scenarios.
-
GUI instruction tuning: Integrating GUI-related multi-task data, deepening the model’s understanding of GUI content and functions, and enabling initial Q&A capabilities. A wide range of open-source data and privately collected data was used.
-
GUI agent SFT: Equipping the model with comprehensive GUI agent reasoning capabilities, training data includes open-source datasets (such as Mind2Web) and additional collected cross-platform multi-application data.
Evaluation Results
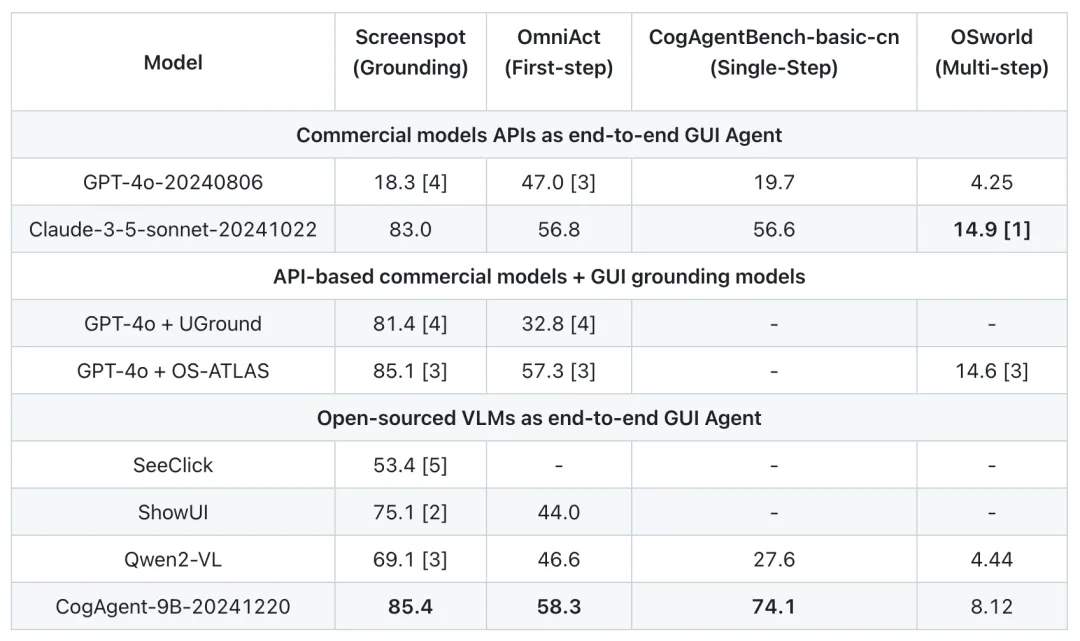
Results show that CogAgent achieved leading results in GUI positioning (Screenspot), single-step operation (OmniAct), Chinese step-wise leaderboard (CogAgentBench-basic-cn), and multi-step operation (OSWorld), only slightly lagging behind Claude-3.5-Sonnet specialized for Computer Use and GPT-4o combined with an external GUI Grounding Model on OSworld.
Click to read the original text, directly access the CogAgent-9B open-source model address