

By/ Li Jieqian
1. Introduction to the Issues
At the end of 2022, the release of ChatGPT by OpenAI in the United States sparked discussions about AIGC (Artificial Intelligence Generated Content), such as the capabilities of ChatGPT, which jobs are most likely to be replaced by AIGC, and the application of AIGC in specific industries, bringing advanced AI technology into the work and lives of ordinary people. Before this breakthrough, AIGC had a long history of development, limited to small-scale experiments, research fields, or commercial scenarios. AIGC stands for Artificial Intelligence Generated Content. AIGC models can be classified based on different standards, such as image models, text models, video models, audio models, and multimodal large models. Following the explosion of AIGC, technology companies in China quickly launched several high-quality large model products, such as Baidu’s Wenxin Yiyan, Alibaba’s Tongyi Qianwen and Tongyi Wanxiang, KIMI.AI from the company Moon Dark Side, and Tencent’s Hunyuan. With the rapid development of AIGC technology and the influx of products, related legal issues have also arisen. Based on the differences in the types of content generated by models and the disputes that have occurred, AIGC related to text-to-image and image-to-image generation is more likely to lead to disputes. The discussions in theory and practice mainly cover several aspects: first, whether the works fed to train AIGC large models require authorization and what kind of authorization is necessary; second, the liability for infringement of AI-generated content; and third, the copyrightability and ownership of AI-generated content.
2. Several Issues Related to AIGC and Copyright
1. Works Stored During AIGC Training Should Obtain Authorization
Computational power, algorithms, and data are the three driving forces behind AI development. The rapid development of the internet has provided massive amounts of data for AIGC algorithm training. From the perspective of the R&D and production process of AI large models, it can be divided into four stages: data collection, cleaning, training, and application. This process inevitably involves the reproduction of a large amount of copyrighted content. According to the aforementioned data processing flow, there is no user access to relevant works at a personally selected time or place before the application stage, which does not involve the right of communication through the internet. Under the existing framework of China’s Copyright Law, it is difficult for this behavior to meet the conditions for fair use, nor does it fall under statutory licensing. The Supreme People’s Court’s opinion on fully leveraging the role of intellectual property trials to promote the great development and prosperity of socialist culture and promote the coordinated development of the economy mentions that in special circumstances where it is necessary to promote technological innovation and commercial development, factors such as the nature and purpose of the work’s usage, the nature of the work used, the quantity and quality of the portion used, and the impact of the usage on the potential market or value of the work should be considered. If the usage does not conflict with the normal use of the work and does not unreasonably harm the legitimate interests of the author, it can be considered fair use. Although the aforementioned opinion cannot be directly used as a basis for judgment, it provides reasoning space and judgment ideas, which will affect the determination of infringement and liability in court cases. Among the existing cases related to AIGC, the “Ultraman Case” is the closest to the determination of infringement in the use of materials during the training stage. Unfortunately, the defendant was a service provider and not the model training entity, and the evidence presented in the litigation was insufficient.
The “Interim Measures for the Management of Generative Artificial Intelligence Services” stipulates in Article 7 that generative AI service providers must carry out pre-training and optimization training data processing activities in accordance with the law. If it involves intellectual property rights, they must not infringe upon the intellectual property rights legally enjoyed by others. It can be seen that theoretically, works stored during the training stage should obtain authorization for reproduction rights. In practice, a large amount of material is also obtained through legitimate channels; however, there are indeed many works used without authorization. In practice, due to the relative concealment and non-dissemination of works used during the training stage, it is difficult for rights holders to discover the existence of infringement. Infringement is more often exposed during the application stage, as seen in the “Ultraman” case, where the rights holder discovered the infringement. Implementing corresponding compliance measures during the generation stage can further avoid the expansion of “infringement.” Of course, there may be other infringement risks in data acquisition, such as the destruction of copyright protection technical measures and illegally obtaining data from computer information systems, which will not be elaborated here.
Different countries or regions have varying attitudes toward the use of works for AI training, with some being relatively conservative and others supportive. The French Competition Authority (“ADLC”) imposed a fine of 250 million euros on Google’s parent company, stating that Google’s AI service “Bard” (now called Gemini), launched in July 2023, used content from news agencies and publishers to train its large model without notifying the news agencies, publishers, or ADLC, violating its commitment to cooperate with supervisory trustees. The basis for the punishment was the EU’s 2019 “Copyright Directive for the Digital Single Market,” which requires internet platforms to “make every effort” to obtain permission from copyright holders such as film and music producers, and forced Google to reach a series of copyright commitments with the news industry. In 2018, Japan amended its Copyright Law, establishing a fair use clause in Article 30, Paragraph 4, stating that “use not aimed at appreciating the original value of the work” is permitted. Japan’s Minister of Education, Culture, Sports, Science and Technology, Keiko Nagaoka, stated that Japanese law does not protect copyright materials used in AI training collections, allowing the use of copyright owners’ works for AI model training, whether for non-profit or commercial purposes, including both reproduction and non-reproduction actions.
2. The Rules for Determining Infringement of AI-Generated Content Should Focus on Duty of Care
Currently, there have been cases in China where AI-generated content has been recognized as infringing. In the “Ultraman Case” decided by the Guangzhou Internet Court in 2024, the plaintiff, as the rights holder of the work “Ultraman,” generated substantially similar images by inputting “Ultraman” on the defendant’s website, suing the defendant for unauthorized use of their work to train the AI model and seeking to stop the infringement and claim damages. The court held that the defendant’s website generated images that copied the plaintiff’s work, infringing on the reproduction right, and that part of the content was adapted while retaining the original expression, thus infringing on the adaptation right. The court ordered the defendant to stop the infringement and take technical measures to cease generating images substantially similar to the plaintiff’s work (as the defendant was not the training party of the large model, the request to delete from the database was not supported). In determining the damages, the court considered the defendant’s subjective fault, involving the service provider’s duty of reasonable care, such as complaint reporting mechanisms, risk warnings, AI labeling, etc. Some opinions argue that the defendant in this case was not the actual training party of the large model and, as a data access party, could invoke the “legal source” defense. This article does not agree with that. First, the “legal source” defense in copyright law refers to Article 59 of China’s Copyright Law, which only targets specific behaviors of specific entities in specific usage scenarios, mainly concerning the distribution of copies and the rental of audiovisual, software, and recording products, and does not include adaptation rights, the right of communication through the internet, etc. Second, according to the definition in the “Interim Measures for the Management of Generative Artificial Intelligence Services,” generative AI service providers include organizations and individuals that provide generative AI services through programmable interfaces. Based on the above, the defendant in this case should bear responsibility according to the requirements of the service provider.
AI-generated content is produced based on user input instructions. First, if there are no copyrighted materials at the source, copyright content will not be produced; second, if there are no precise instructions from the user, copyright content will not be produced either. In fact, both the service provider and the user share certain “fault” in the infringement during the content generation stage, and the user bears greater responsibility for subsequent dissemination of the generated content. This article believes that platforms should be required to fulfill their management, supervision, and prevention obligations, warning users of risks through product design, copy prompts, and contractual constraints to reduce the likelihood of infringement. Even if the user’s purpose is to obtain copyrighted works, except for a few cases where there are costs due to payment or membership requirements, most can be obtained through online searches, making it unnecessary to use AI to obtain copies of “Ultraman.” There may be a demand for adapted works of copyrighted content, such as a “National Style Version of Ultraman,” but it should also be limited to personal learning and appreciation. The law clearly stipulates that authorization is required for the dissemination of copyrighted content and its adapted works over the internet and broadcasting; one cannot claim that using AI to generate substantially similar works means they are not infringing and can be used freely. In the “Ultraman” case, if the service provider had designed the content generation rules, the plaintiff’s rights content might not have appeared directly, as this article randomly tested a text-to-image AIGC platform, which did not generate content substantially similar to the rights work.
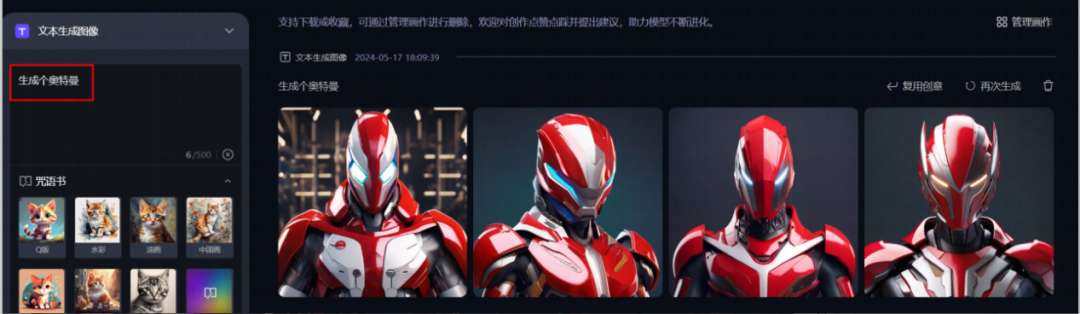
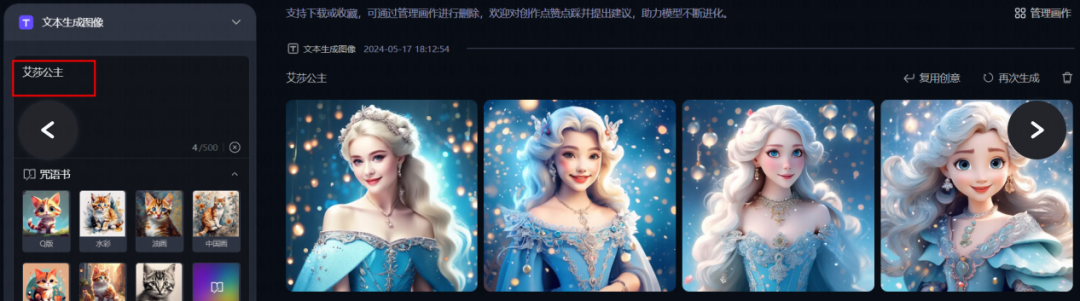
3. AI-Generated Content Has Copyright Protection Space
China’s Copyright Law protects works that are original intellectual achievements in the fields of literature, art, and science, which belong to Chinese citizens, legal persons, or unincorporated organizations. It can be seen that AI-generated content is eligible for copyright protection if it meets the following criteria: (1) it belongs to the fields of literature, art, and science; (2) it has originality; (3) it is expressed in a certain form; (4) it is an intellectual achievement. Considering the situation of AI-generated content mentioned above, it generally meets criterion (3), and depending on the specific generated content, it is relatively easy to determine whether it meets criterion (1), while the difficulty lies in the judgment of originality and intellectual achievement. This dilemma is faced universally by various countries. In the past, people also created using tools, but the tool’s functionality was stronger while human intellectual achievements were more direct. AI-generated content, especially graphical and video content, can generate complex content based on user input keywords and prompts. At this point, is the input content a thought or an expression? Is the generated image created by the user or “created” by AIGC? Focusing on text-to-image and image-to-image AI, different products and the specific generation processes of different works vary. It can be as simple as generating a final draft from a single word, multiple words, and parameters, or repeatedly selecting and optimizing images to finalize the draft, or generating images and then editing them to completion, etc. The degree to which human originality, intellectual achievement, and the extent included in the aforementioned different content may affect the final judgment of the copyrightability of AI-generated content.
There are many discussions and divergences in academia regarding the copyrightability of AI-generated content. Some opinions argue that AI-generated works do not meet the originality requirement, asserting that the content generated by AI is the result of applying algorithms, rules, and templates, essentially still belonging to executing established processes and methods, and obtaining a determined result through computation, fundamentally differing from personalized intellectual creation. Copyright law protects and encourages individuals engaged in creative activities with their intellect, and AI-generated content should not receive copyright protection. Other opinions suggest that the copyrightability of AI-generated content should be analyzed specifically. When a user inputs prompts in a single round, it is abstract thought, which cannot be protected by copyright law; however, when the user guides the AI to repeatedly modify based on the initial draft output, after multiple rounds of linear improvement, the user may make personalized choices and adjustments to many expressive details in the work, thus making a contribution of originality. Additionally, some opinions, from the perspective of legislative policy and purpose, combined with economic analysis, argue against granting originality to AI-generated content, as doing so would further lead to data scarcity, distorted incentives, and reduced revenue. Academic discussions are more inclined toward theoretical research, which helps clarify legal issues. Based on the analysis of several existing cases related to AI-generated content in China, there is significant space for AI-generated content to be recognized as works, and the attribution of rights to the works should be judged based on the agreements between users and platforms.
We also note the U.S. Copyright Office’s stance on the registration of content generated using artificial intelligence. The Copyright Office rejected the registration of an image named “SURYAST” as a work, citing that it “lacked the human authorship necessary to support a copyright claim.” “SURYAST” was generated by Mr. Sahni in the AI software RAGHAV, where he uploaded a photo he took and a style image (Vincent van Gogh’s The Starry Night) and input a value to adjust the style, after which RAGHAV generated the image. Mr. Sahni did not make any other adjustments to the generated image. U.S. copyright law requires that works be “original works of authorship fixed in any tangible medium of expression.” The court held that “works of authorship” require human creation of the work and rejected Mr. Sahni’s registration application.

(Image One)

(Image Two)
In the copyright registration of the AIGC content “Zarya of the Dawn,” the Copyright Office held a similar view. Ms. Kashtanova applied to register a comic work titled “Zarya of the Dawn,” which consists of 18 pages, including text, images, and arrangements of images. The images were generated using the AI software Midjourney. According to the applicant’s evidence, her use of Midjourney was merely as a tool, which included her originality. The generation process involved inputting text prompts, selecting from multiple generated images for further processing, adjusting or modifying prompts continuously, and a large number of process images were selected and adjusted. However, the Copyright Office ultimately believed that the images generated using Midjourney did not reflect human creation and were not protected by copyright law.

(A frame from the comic “Zarya of the Dawn”)

(A process image from “Zarya Holding a Postcard” in “Zarya of the Dawn”)
In the case of “The Gentle Breeze Brings Warmth,” the plaintiff used the Stable Diffusion software to generate the image in question by inputting prompts and published it online under the name “The Gentle Breeze Brings Warmth,” later being sued for unauthorized use by the defendant. Regarding whether the plaintiff’s use of AI-generated content constitutes a work protected by China’s Copyright Law, the court believed that in terms of intellectual achievement, the plaintiff made certain intellectual contributions during the image generation process, such as designing the presentation of characters, choosing prompts, arranging the order of prompts, setting related parameters, and selecting the image that met expectations. In terms of originality, the image in question reflects the plaintiff’s choices and arrangements. Different individuals can input new prompts and set new parameters to generate different content. Ultimately, the court determined that the image in question met the copyright law’s requirements for artistic works, as it belongs to the field of art, has originality, and is an intellectual achievement expressed in a certain form.
The copyright registration case of “Zarya of the Dawn” and the case of “The Gentle Breeze Brings Warmth” are similar in that both involve images generated by AI software. However, the conclusions regarding whether they constitute works under copyright law differ. Certainly, the software used in the two cases is different, and the operation and creative space also vary, but based on the generation processes described in the cases, this article believes that “The Gentle Breeze Brings Warmth” does not show more human intellectual achievement in creation compared to “Zarya of the Dawn.”
3. Compliance Suggestions Related to AIGC
Given the analysis above, if AI providers train and generate content after obtaining authorization, they need to pay attention to analyzing the corresponding copyright rights based on the usage scenarios and different stages of use to avoid situations where there is authorization but the final use exceeds authorization. Since the objective use of unauthorized copyrighted content during large model training is likely to occur, and the generated content may substantially resemble others’ works, the users of the generated content also face significant uncontrollable risks. As a result, existing legal provisions and judicial practices may expose AI service providers and users of generated content to liability for infringement. Relevant parties need to fulfill their duty of care in the product and service processes, clarifying rights and responsibilities.
1. Provider’s Product Design Level
For text-to-image products, it is recommended to set up a keyword library to recognize and process specific IP names. When users input specific IP names, the algorithm should generate content that is similar but not substantially similar, as tested in the text-to-image AI where “Ultraman” and “Princess Elsa” were generated. From the user’s experience perspective, it can also enhance user awareness by prompting that there are copyright risks associated with the input content before generating the aforementioned images. For products that include user-uploaded images, it is essential to clearly inform users of copyright rights and responsibilities at the time of upload.
From the perspective of accountability after an infringement occurs, service providers can use watermark technology and service logs to identify the users who generated the content and relevant information to clarify the parties involved and pursue breach of contract liability.
2. Provider’s Service Norms Level
In accordance with the “Interim Measures for the Management of Generative Artificial Intelligence Services” and related requirements, industry practices, and judicial opinions, it is recommended that AIGC service providers sign agreements with users of AIGC, clearly defining the rights and obligations of both parties, such as the duty of care regarding generated content, usage restrictions, liability assumptions, and copyright ownership. The copyright-related clauses in the agreement should specify that they must not induce AI infringement, must not input infringing content, users are responsible for the rights of uploaded content, and it should be explicitly stated that generated content is limited to personal learning purposes and cannot be disseminated through the information network without permission, etc., highlighted through bold or pop-up points to draw users’ attention.
Additionally, providers should establish and improve complaint and reporting mechanisms, providing convenient access for complaints and reports; and label generated content such as images and videos in accordance with the “Regulations on the Management of Deep Synthesis of Internet Information Services.” Through the above measures, enhance and improve the provider’s duty of care in services, reducing the likelihood and consequences of infringement.
Notes and References
[1] (2024) Yue 0192 Civil First 113
[2] Wang Qian: “On the Qualitative Nature of AI-Generated Content in Copyright Law,” published in Legal Science, 2017, Issue 5.
[3] Cui Guobin: “User’s Original Contribution in AI-Generated Works,” published in China Copyright, 2023, Issue 6.
[4] Zhu Ge, Cui Guobin, Wang Qian, Zhang Huyue: Is AI-Generated Content (AIGC) Protected by Copyright Law?
[5] See U.S. Copyright Office, Review Board decision on SURYAST (December 11, 2023), https://copyright.gov/ai/, last visited on May 29, 2024.
[6] See U.S. Copyright Office, Registration Decision on Zarya of the Dawn (Feb. 21, 2023), https://copyright.gov/ai/, last visited on May 29, 2024.
[7] (2023) Jing 0491 Civil First 11279
(This article is published with authorization and only represents the author’s views. It may not be reproduced without permission.)
SHIPA
Recent Hot Articles

