
This article is approximately 1800 words long and is recommended to be read in 5 minutes. This article will deeply introduce the 7 core functions of the torch.utils.data module in PyTorch, which can help you better manage and manipulate data.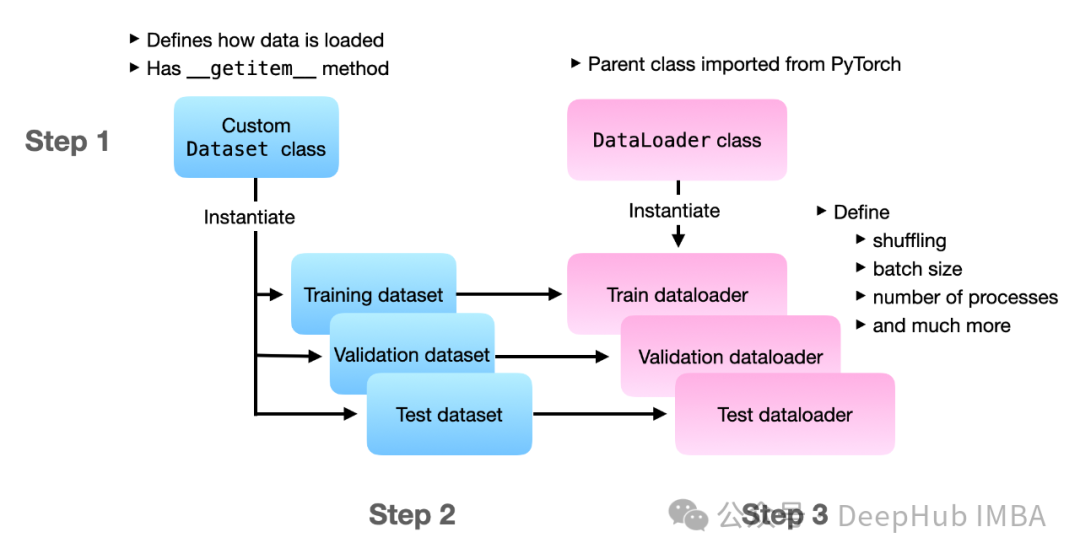
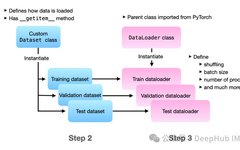
1. Dataset Class
-
__len__ method: Returns the size of the dataset -
__getitem__ method: Retrieves a sample based on the given index
import torch from torch.utils.data import Dataset
class CustomDataset(Dataset): def __init__(self, data, labels): self.data = data self.labels = labels
def __len__(self): return len(self.data)
def __getitem__(self, idx): return self.data[idx], self.labels[idx]
# Create a simple dataset data = torch.randn(100, 5) # 100 samples, each with 5 features labels = torch.randint(0, 2, (100,)) # Binary classification labels
dataset = CustomDataset(data, labels) print(f"Dataset size: {len(dataset)}") print(f"First sample: {dataset[0]}")
2. DataLoader
-
Batch loading data -
Automatic shuffling of data -
Multi-process data loading for improved efficiency -
Custom data sampling strategies
from torch.utils.data import DataLoader
# Using the previously created dataset batch_size = 16 dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=2)
for batch_data, batch_labels in dataloader: print(f"Batch data shape: {batch_data.shape}") print(f"Batch labels shape: {batch_labels.shape}") break # Only print the first batch
3. Subset
-
Experimenting with a data subset -
Splitting the dataset into training, validation, and test sets
from torch.utils.data import Subset import numpy as np
# Create a subset containing the first 20% of the original dataset dataset_size = len(dataset) subset_size = int(0.2 * dataset_size) subset_indices = np.random.choice(dataset_size, subset_size, replace=False)
subset = Subset(dataset, subset_indices) print(f"Subset size: {len(subset)}")
# Create a new DataLoader using the subset subset_loader = DataLoader(subset, batch_size=8, shuffle=True)
4. ConcatDataset
-
Merge data from different sources -
Create larger and more diverse training sets
from torch.utils.data import ConcatDataset
# Create two simple datasets dataset1 = CustomDataset(torch.randn(50, 5), torch.randint(0, 2, (50,))) dataset2 = CustomDataset(torch.randn(30, 5), torch.randint(0, 2, (30,)))
# Merge datasets combined_dataset = ConcatDataset([dataset1, dataset2]) print(f"Combined dataset size: {len(combined_dataset)}")
# Create DataLoader using the combined dataset combined_loader = DataLoader(combined_dataset, batch_size=16, shuffle=True)
5. TensorDataset
-
Directly using tensor data -
Simplifying the usage process of already pre-processed data
from torch.utils.data import TensorDataset
# Create feature and label tensors features = torch.randn(1000, 10) # 1000 samples, each with 10 features labels = torch.randint(0, 5, (1000,)) # 5-class problem
# Create TensorDataset tensor_dataset = TensorDataset(features, labels)
# Create DataLoader using TensorDataset tensor_loader = DataLoader(tensor_dataset, batch_size=32, shuffle=True)
for batch_features, batch_labels in tensor_loader: print(f"Feature shape: {batch_features.shape}, Label shape: {batch_labels.shape}") break
6. RandomSampler
-
Increase randomness in training -
Reduce the risk of model overfitting
from torch.utils.data import RandomSampler
# Using the previously created dataset random_sampler = RandomSampler(dataset, replacement=True, num_samples=50)
# Create DataLoader using RandomSampler random_loader = DataLoader(dataset, batch_size=10, sampler=random_sampler)
for batch_data, batch_labels in random_loader: print(f"Random sampled batch size: {batch_data.shape[0]}") break
7. WeightedRandomSampler
-
Sample minority classes more frequently -
Balance class distribution and improve the model’s sensitivity to minority classes
Code Example:
from torch.utils.data import WeightedRandomSampler import torch.nn.functional as F # Assume we have an imbalanced dataset imbalanced_labels = torch.tensor([0, 0, 0, 0, 1, 1, 2]) class_sample_count = torch.tensor([(imbalanced_labels == t).sum() for t in torch.unique(imbalanced_labels, sorted=True)]) weight = 1. / class_sample_count.float() samples_weight = torch.tensor([weight[t] for t in imbalanced_labels]) # Create WeightedRandomSampler weighted_sampler = WeightedRandomSampler(samples_weight, len(samples_weight)) # Create a simple dataset imbalanced_dataset = TensorDataset(torch.randn(7, 5), imbalanced_labels) # Create DataLoader using WeightedRandomSampler weighted_loader = DataLoader(imbalanced_dataset, batch_size=3, sampler=weighted_sampler) for batch_data, batch_labels in weighted_loader: print(f"Sampled labels: {batch_labels}") break
Conclusion
About Us
Data派THU, as a data science public account, backed by Tsinghua University Big Data Research Center, shares cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, striving to build a platform for gathering data talents, and creating the strongest group of data in China.

Sina Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today’s Headlines: 数据派THU