
Author: Lars Hulstaert
Translated by: Wu Jindi
Proofread by: Nicola
This article is approximately 2000 words, suggested reading time is 9 minutes.
This article will discuss different techniques that can be used to explain machine learning models.
Most machine learning systems need to be able to explain to stakeholders why specific predictions are made. When selecting the appropriate machine learning model, we often weigh accuracy against interpretability:
-
Accuracy vs. Black-Box:
Black-box models such as neural networks, gradient-boosted models, or complex ensembles often provide high accuracy. The inner workings of these models are difficult to understand, and they cannot estimate the importance of each feature to the model’s predictions, nor is it easy to understand how different features interact with each other.
-
Weaker vs. White-Box:
On the other hand, simpler models like linear regression and decision trees have weaker predictive power and do not always model the inherent complexity of the dataset (i.e., feature interactions). However, these are easy to understand and explain.
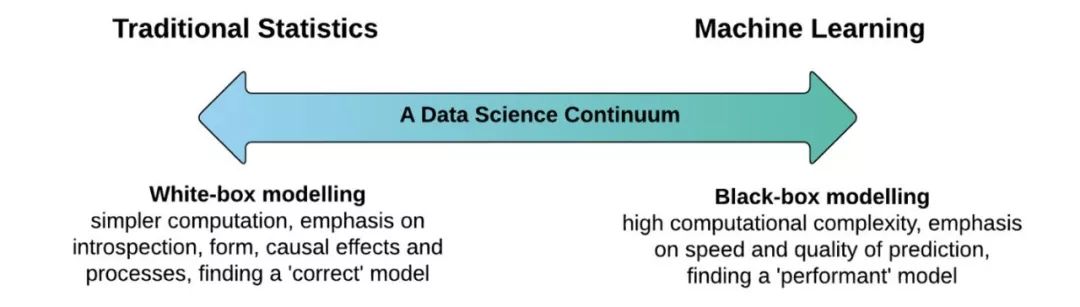
Image from Applied.AI
The trade-off between accuracy and interpretability depends on an important assumption that “interpretability is an inherent property of the model.”
“Interpretability is an inherent property of the model”
https://www.inference.vc/accuracy-vs-explainability-in-machine-learning-models-nips-workshop-poster-review/
However, I firmly believe that with the right “interpretability techniques,” any machine learning model can be made more interpretable, although the complexity and cost may be higher for some models than others.
In this blog post, I will discuss different techniques that can be used to explain machine learning models. The structure and content of this blog post are primarily based on the H20.ai Machine Learning Interpretability booklet. If you want to learn more, I highly recommend reading this H20.ai booklet or other materials written by Patrick Hall!
H20.ai Machine Learning Interpretability Booklet
Patrick Hall
http://docs.h2o.ai/driverless-ai/latest-stable/docs/booklets/MLIBooklet.pdf
Model Properties
The degree of interpretability of a model is often associated with two properties of the response function. The model’s response function f(x) defines the input (features x) and output (target f(x)) relationship between input and output. Depending on the machine learning model, this function has the following characteristics:
-
Linearity: In a linear response function, the association between features and the target is expressed linearly. If a feature changes linearly, we also expect the target to change linearly at a similar rate.
-
Monotonicity: In a monotonic response function, the relationship between features and the target always moves in one direction (increasing or decreasing) across the feature domain and is independent of other feature variables.
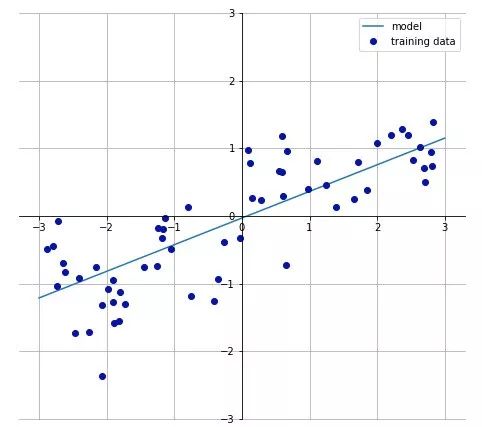
Examples of simple linear and monotonic response functions (1 input variable x, 1 response variable y)
A linear regression model is an example of a linear monotonic function, while random forests and neural networks are examples of models that exhibit highly nonlinear and non-monotonic response functions.
The following slides by Patrick Hall illustrate why white-box models (with linear and monotonic functions) are often preferred when clear and simple model explanations are needed. The top chart shows that as age increases, the quantity purchased increases. The global response function has a linear and monotonic relationship, which is easy for all stakeholders to understand.
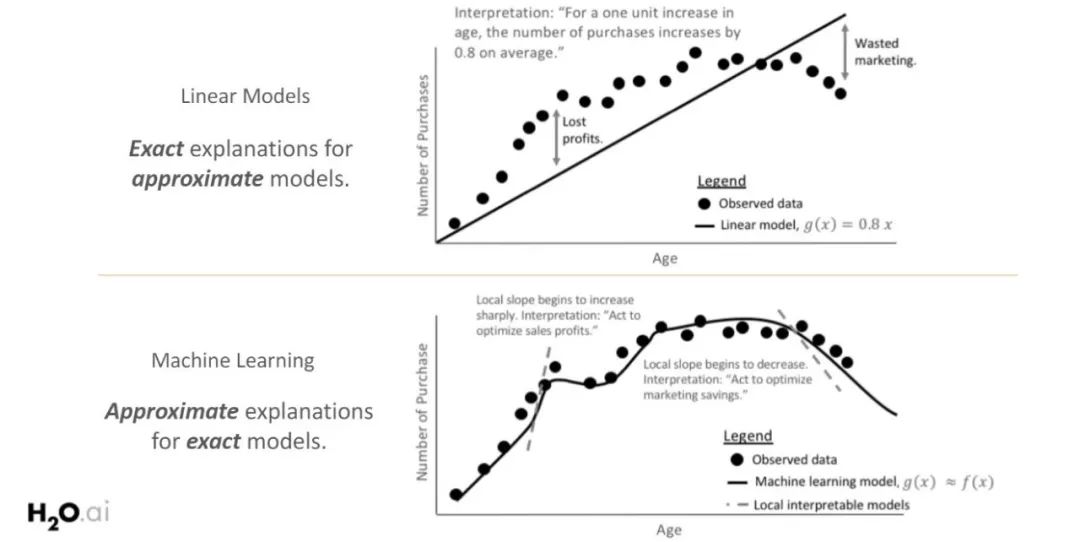
However, due to the linear and monotonic constraints of white-box models, an important part of the trend is overlooked. By exploring more complex machine learning models, while the response function may only be linear and monotonic in a local range, it can better fit observed data. To explain model behavior, it is necessary to study the model in a local range.
In both global and local contexts, the scope of model interpretability is inherently related to the complexity of the model. Linear models exhibit the same behavior across the entire feature space (as shown in the above figure), making them globally interpretable. The relationship between input and output is often constrained by complexity and local explanations (i.e., why did the model make a certain prediction at a specific data point?), while local explanations default to global explanations.
For more complex models, it is more difficult to define the global behavior of the model and requires local explanations of small regions of the response function. These small regions are more likely to exhibit linear and monotonic behavior, thereby achieving more accurate explanations.
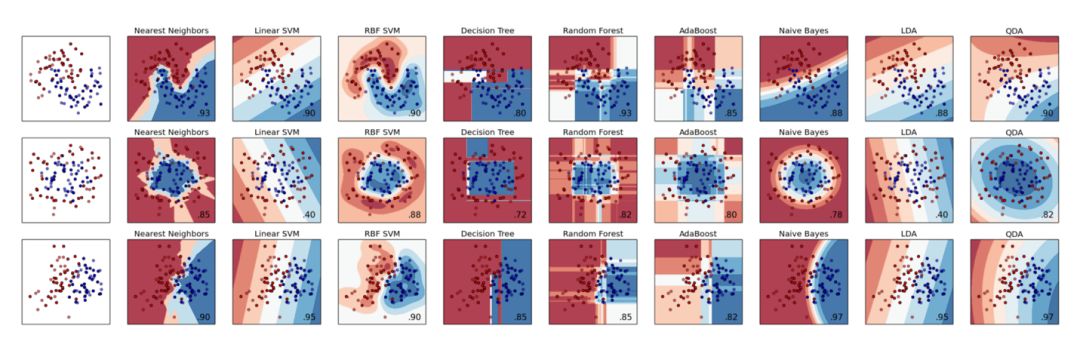
ML libraries (such as scikit-learn) allow for quick comparisons between different classifiers. When the size and dimensions of the dataset are constrained, results can be explained. In most real-world problems, this will no longer be the case.
In the remainder of this blog post, I will focus on two model-agnostic techniques that provide global and local explanations. These techniques can be applied to any machine learning algorithm and achieve interpretability by analyzing the response function of the machine learning model.
Interpretability Techniques
1. Surrogate Models
Surrogate models are models used to explain more complex models. Linear models and decision tree models are commonly used due to their simplicity in interpretation. Surrogate models are created to represent the decision-making process of complex models (response functions) and are trained on the input and model predictions rather than on the input and target.
Surrogate models provide a layer of global interpretability over nonlinear and non-monotonic models, but they should not be completely relied upon. Surrogate models cannot perfectly represent the underlying response function nor capture complex feature relationships. They primarily serve as a “global summary” of the model. The following steps illustrate how to build a surrogate model for any black-box model:
-
Train the black-box model.
-
Evaluate the black-box model on the dataset.
-
Select an interpretable surrogate model (usually a linear model or decision tree).
-
Train the interpretable model on the dataset and its predictions.
-
Determine the error metrics of the surrogate model and interpret the surrogate model.
2. LIME
The general idea behind LIME is similar to that of surrogate models. However, LIME does not build a global surrogate model that represents the entire dataset, but instead constructs local surrogate models (linear models) that explain predictions in local regions of interest. For a deeper explanation of LIME, refer to the blog post on LIME.
LIME provides an intuitive method to explain the model predictions for a given data point.
The following steps illustrate how to build a LIME model for any black-box model:
-
Train the black-box model.
-
Sample points in the local region of interest. Sample points can be retrieved from the dataset or generated artificially.
-
Weight new samples based on proximity to the region of interest. Fit a weighted interpretable (surrogate) model on the diverse dataset.
-
Interpret the local surrogate model.
Conclusion
You can use several different techniques here to enhance the interpretability of your machine learning models. Although these techniques are becoming increasingly powerful with advancements in the field, it is important to continually compare different techniques. One technique I have not discussed is Shapley values. To learn more about this technique, please see Christoph Molnar’s book “Interpretable Machine Learning.”
Interpretable Machine Learning
Christoph Molnar
https://christophm.github.io/interpretable-ml-book/
Original Title:
Black-box vs. white-box models
Original Link:
https://towardsdatascience.com/machine-learning-interpretability-techniques-662c723454f3
Translator’s Profile

Wu Jindi, a first-year master’s student in computer science at Syracuse University. I thrive in challenging situations, and my goal is to be a cool girl who goes to bed early and rises early.
Translation Group Recruitment Information
Job Description: A meticulous heart is needed to translate well-selected foreign articles into fluent Chinese. If you are an international student in data science/statistics/computer science, or working overseas in related fields, or confident in your language skills, you are welcome to join the translation group.
What You Can Gain: Regular translation training to improve volunteers’ translation skills, enhance understanding of cutting-edge data science, overseas friends can stay connected with domestic technological applications, and the background of Data Party THU provides good development opportunities for volunteers.
Other Benefits: You will be partnered with data scientists from well-known companies and students from prestigious universities such as Peking University, Tsinghua University, and overseas.
Click the end of the article “Read the original” to join the Data Party team~


Click “Read the original” to embrace the organization