Click the card below to follow the “Computer VisionDaily” public account
AI/CV heavy content delivered promptly
Reprinted from: Machine Heart | Edited by: Du Wei, Chen Ping
An input facial image can actually generate diverse styles of anime characters. Researchers from the University of Illinois at Urbana-Champaign have achieved this with a novel GAN transfer method that realizes a “one-to-many” generation effect.
In the field of GAN transfer, researchers can build a mapping that takes a facial image as input and outputs an anime character representation. Various research methods have emerged, such as the Disney fairy tale face effect previously launched by Tencent Weishi.
During the transfer process, the content part of the image may be retained, but the style part must change because the same face can be represented in multiple ways in animation. This means that the transfer process is a one-to-many mapping that can be represented as a function to accept content codes (i.e., recovered from the facial image) and style codes (which are latent variables) to generate anime faces. However, some important constraints must be followed.
-
First is control: changing the input face to change the content of the anime face (e.g., the anime face should turn with the input face);
-
Second is consistency: rendering the same latent variable for the real face should match the style closely (e.g., the anime face will not change style with the input face’s turn under the premise of not changing the latent variable);
-
Finally, coverage: each anime face can be obtained using combinations of content and style, allowing for all possible anime representations.
Recently, researchers from the University of Illinois at Urbana-Champaign proposed a new GAN transfer method called GANs N’ Roses (abbreviated as GNR). This multimodal framework directly formalizes the mapping of style and content. In simple terms, the researchers demonstrated a method that takes the content code of a facial image as input and outputs anime characters with various randomly selected style codes.

Technically, the researchers derived a generative adversarial loss based on a simple and effective definition of content and style, which guarantees the diversity of the mapping, meaning that diverse styles of anime characters can be generated from a single content code. Under reasonable assumptions, this mapping is not only diverse but can also correctly represent the probability of anime characters conditioned on the input face. In contrast, current multimodal generative methods fail to capture styles in anime. Numerous quantitative experiments show that compared to SOTA methods, the GNR method can generate a wider variety of anime styles.
How does GNR’s generation effect look? Let’s first look at a demo image of an anime character inspired by the Girl with a Pearl Earring:
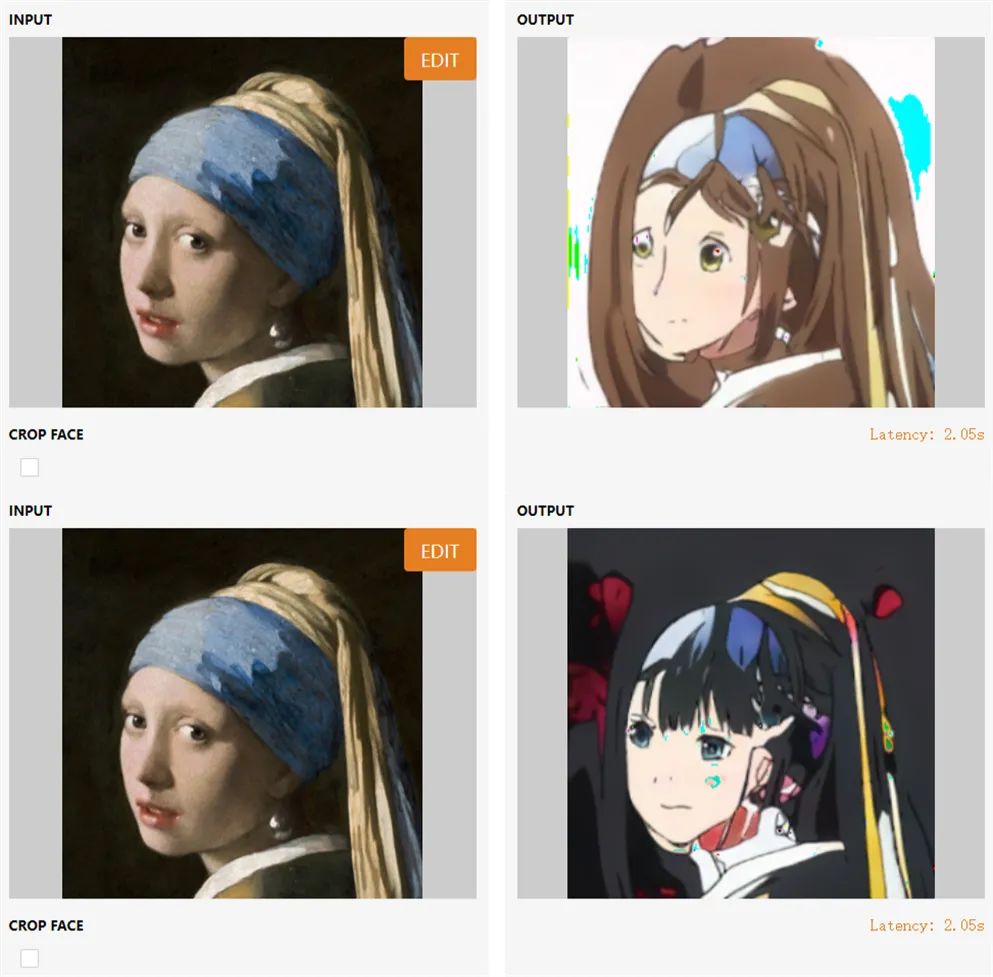
Currently, users can also try it out by simply uploading their images to generate their anime characters with one click. Machine Heart tested the generation effect with an image of Portuguese football star Cristiano Ronaldo, em…:
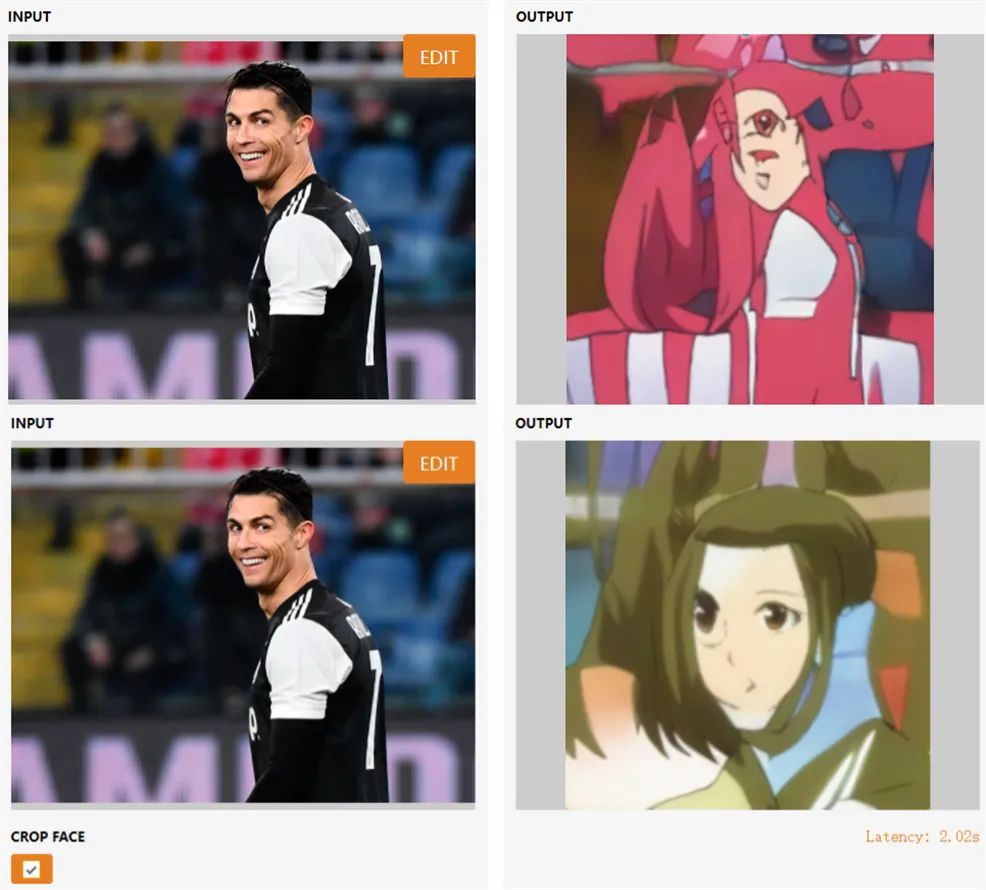
Meanwhile, without any training on videos, the GNR method can also achieve video-to-video transfer.

Given two domains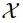 ,
, 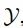
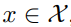 , the goal is to generate a set of different
, the goal is to generate a set of different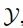 in the target domain with semantic content similar to x. The study elaborates on the details of the conversion from domain
in the target domain with semantic content similar to x. The study elaborates on the details of the conversion from domain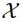 to
to 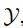 in detail. As shown in Figure 2, GANs N’ Roses consists of an encoder E and a decoder F, which can be used for both directions. The encoder E decomposes the image x into content code c(x) and style code s(x). The decoder F receives the content and style codes and generates the appropriate image from
in detail. As shown in Figure 2, GANs N’ Roses consists of an encoder E and a decoder F, which can be used for both directions. The encoder E decomposes the image x into content code c(x) and style code s(x). The decoder F receives the content and style codes and generates the appropriate image from 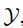 .
The encoder and decoder together form a generator. At runtime, this generator is used by passing images to the encoder to retain the generated content code c(x), obtaining some other related style codes s_z, and then passing this pair of codes to the decoder. The study aims for the final anime content to be controlled by content encoding and the style to be controlled by style encoding.
.
The encoder and decoder together form a generator. At runtime, this generator is used by passing images to the encoder to retain the generated content code c(x), obtaining some other related style codes s_z, and then passing this pair of codes to the decoder. The study aims for the final anime content to be controlled by content encoding and the style to be controlled by style encoding.
But what is content and what is style? The core idea of GANs N’Rose is to define content as the position of things and style as the appearance of things. This can be achieved through the idea of data augmentation. A set of relevant data augmentations is selected, where under all conditions: style is invariant, content is variable. Note that this definition is conditioned on data augmentation—different sets of data augmentation will lead to different style definitions.
To ensure users can obtain different styles of anime, there are currently three strategies: first, styles can be generated simply from randomly selected style codes s_z; second, the decoder has properties that can recover s_z from the decoder; third, a deterministic penalty function can be written to enforce different style codes to decode differently; however, none of these strategies are satisfactory.
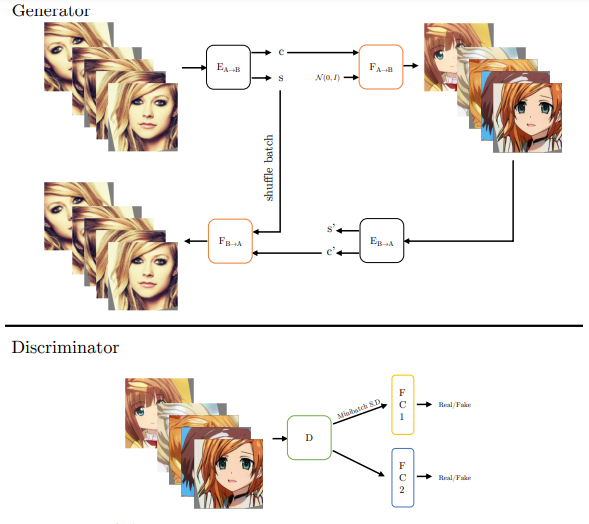
The study provides a new approach to the definitions of style and content. That is, a mapping F(c, s; θ) must be learned, which takes content code c and style code s to generate anime faces.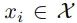 represents a single image randomly selected from the data, T(·) represents the function that applies randomly selected augmentations to that image, P(C) represents the distribution of content codes, P(Y) represents the real distribution of real anime (etc.),
represents a single image randomly selected from the data, T(·) represents the function that applies randomly selected augmentations to that image, P(C) represents the distribution of content codes, P(Y) represents the real distribution of real anime (etc.), 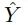 is the generated anime image. Here it must be c(xi) ∼ P(C). Since style is defined as content that does not change under augmentation, a reasonably chosen augmentation should imply that c(T(x_i)) ∼ P(C), meaning that applying random augmentations to the image leads to content codes being examples of previous content codes. This assumption is reasonable; if it is severely violated, the image augmentation training classifier will not work.
is the generated anime image. Here it must be c(xi) ∼ P(C). Since style is defined as content that does not change under augmentation, a reasonably chosen augmentation should imply that c(T(x_i)) ∼ P(C), meaning that applying random augmentations to the image leads to content codes being examples of previous content codes. This assumption is reasonable; if it is severely violated, the image augmentation training classifier will not work.
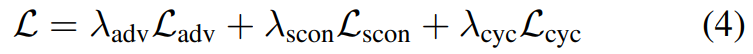
In the experimental section, the study conducted experiments with a batch size of 7, λ_scon = 10, λ_cyc = 20, λ_adv = 1. The network architecture is based on StyleGAN2[9], with a style code dimension of 8. The Adam optimizer [12] was used for 300k batch iterations on all networks, with a learning rate of 0.002. Random augmentations used on input images included random horizontal flips, rotations between (-20,20), scaling (0.9,1.1), translations (0.1,0.1), and shear (0.15). Images were enlarged to 286 × 286 and randomly cropped to 256 × 256. The dataset mainly used the selfie2anime dataset [10] along with additional experiments from AFHQ [1].
Generally speaking, when given the same source image and different random style codes, GNR produces different images. The style codes drive the appearance of hair, eyes, nose, mouth, color, etc., while the content drives the posture, face size, and position of facial features. Figure 4 shows that GNR outperforms other SOTA multimodal frameworks in quality and diversity.
Images generated by GNR exhibit different colors, hairstyles, eye shapes, facial structures, etc., while other frameworks can only generate different colors.

Comparison of multimodal results with SOTA transfer frameworks.
The study also compared with AniGAN [14] in Figure 5. Note that even though AniGAN was trained on a larger and more diverse dataset, this study was able to generate images with better, more diverse, and higher quality. Furthermore, AniGAN generates at a resolution of 128 × 128, while this study generates at a resolution of 256 × 256.

The ablation study shown in the figure below demonstrates that the diversity discriminator plays an important role in ensuring diverse outputs (Figure 6). The experiments indicate that the diversity discriminator significantly promotes GNR to output more diverse and realistic images.

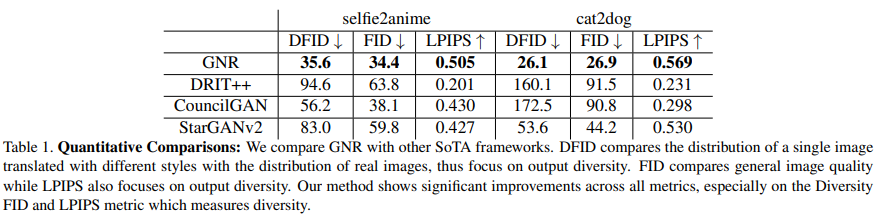
Table 1 quantitatively evaluates GNR using diversity FID, FID, and LPIPS. In all experiments in Table 1, the study found that GNR significantly outperformed other SOTA frameworks on all metrics. Both DFID and LPIPS focus on the diversity of images, and the scores of these metrics quantitatively confirm that the generated images by this study are more diverse than those from other frameworks.
The study defines style and content such that when a face moves in a frame, the style should not change, but the content will change. Specifically, content encodes the location of features, while style encodes the appearance of features. In turn, content encoding should capture all frame-to-frame motion to synthesize anime videos without the need for training on time series.
The study applied GNR frame by frame to facial videos, then assembled the generated frames into a video. The results in the second row of Figure 3 show that GNR produces images that move according to the source while maintaining a consistent appearance over time.


Download the above paper and code
Reply in the backend: GNR to download the paper PDF and code
Download the Neural Network Drawing Tool
Reply in the backend: Drawing Tool, to download the tool for drawing neural network structures!
Download PyTorch Learning Materials
Reply in the backend: PyTorch Resources to access the most comprehensive PyTorch introductory and practical materials!
CVPR 2021 Paper Collection Download
Reply in the backend:CVPR2021, to download the collection of CVPR 2021 papers and open-source codes
Recommended Downloads
82-page “Modern C++ Tutorial”: Quickly get started with C++ 11/14/17/20 (includes Chinese PDF download)
Douban rating 9.4! “Introduction to Statistical Learning” now has a Python version (includes PDF and code download)
▲ Click the card above to follow us
