
1. What is Machine Learning
Machine learning, is a branch of artificial intelligence that specifically studies how computers can simulate or realize human learning behavior. It trains models through various algorithms and uses these models to recognize and predict new problems.
Essentially, machine learning is a way of extracting patterns from data or past experiences to optimize the performance standards of computer programs.
2. What Problems Does It Solve
It solves problems with complex rules. If simple rules can be implemented, there is no need to use machine learning algorithms.When ACM World Champion Devin Yan joined Baidu in 2009, all of Baidu’s search and advertising were based on 10,000 expert rules.With the help of machine algorithms, Devin Yan increased Baidu’s advertising rules from 10,000 to 100 billion.Correspondingly, Baidu’s revenue increased eightfold within four years.
3. The Relationship Between Three Terms
Artificial Intelligence > Machine Learning > Deep Learning
Machine learning that applies neural networks with multiple hidden layers is defined as deep learning.
4. Requirements for AI Product Managers
-
Familiarity with the machine learning process (see the third part of the article);
-
Understanding the classification of problems that machine learning can solve (see the fourth part of the article);
-
Understanding the basic principles of algorithms;
-
Understanding the dependencies between data, algorithms, and computing resources in engineering practice, etc.
2. Basics of Machine Learning
1. The Basis of Machine Learning – Data
Artificial intelligence products consist of three parts: data, algorithms, and computing power, with data being the foundation.
 Image Source: http://www.sohu.com/a/160316515_680198
Image Source: http://www.sohu.com/a/160316515_680198
The success of top global AI scientist Fei-Fei Li is inseparable from the ImageNet dataset of millions of images.
“One major change that ImageNet brought to the AI field is that people suddenly realized that building datasets is the core of AI research,” said Fei-Fei Li:“People really understood that datasets are as crucial to research as algorithms.”“If you only look at 5 pictures of cats, you only know those 5 camera angles, lighting conditions, and at most 5 different types of cats.But if you have seen 500 pictures of cats, you can find commonalities from more examples.”
How large should the data volume be?
-
Thousands:Basic requirement, can solve simple handwritten digit recognition problems, such as MNIST;
-
Tens of thousands:General requirement, can solve image classification problems, such as CIFAR-100;
-
Millions:Quite good, such as ImageNet, accuracy around 2%, surpassing human performance by 5.1%.
AI products not only require quantity from data but also quality. The standards for measuring data quality include the four R’s:Relevancy (primary factor), Reliability (key factor), Range, and Recency.
Data Acquisition Sources:
-
ICPSR:www.icpsr.umich.edu
-
U.S. Government Open Data:www.data.gov
-
University of California, Irvine:archive.ics.uci.edu/ml
-
DataTang:www.datatang.com
3. The Machine Learning Process
The machine learning process can be divided into the following main steps:Goal definition, data collection, data preprocessing, model training, accuracy testing, parameter tuning, model output.
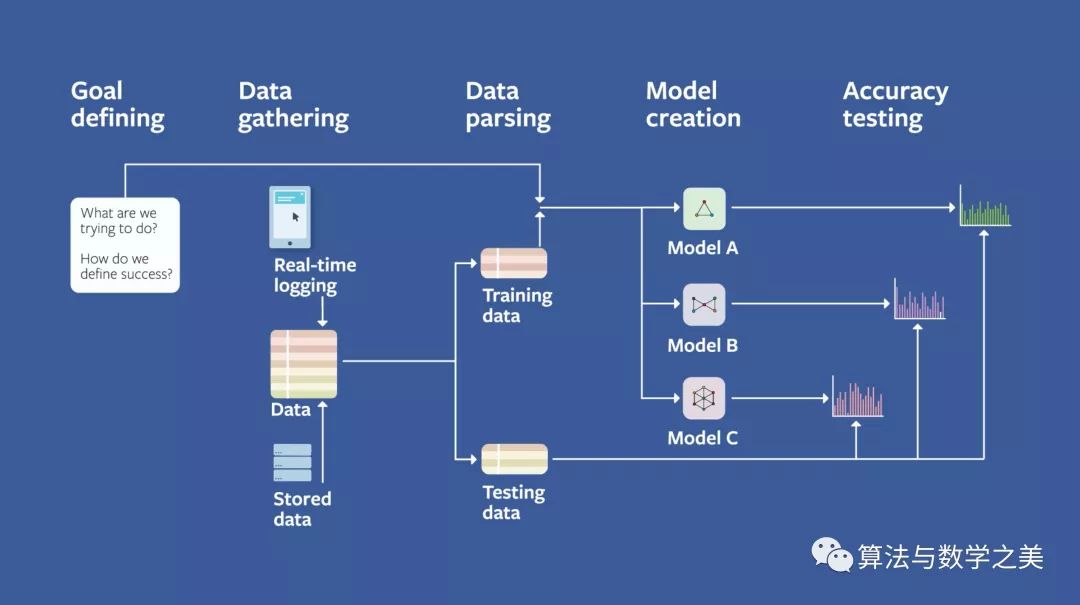 Image Source: https://research.fb.com/the-facebook-field-guide-to-machine-learning-video-series/
Image Source: https://research.fb.com/the-facebook-field-guide-to-machine-learning-video-series/
Breaking Down the Machine Learning Process:
Identify the essence of the problem machine learning aims to solve and the criteria for measurement.
The goals of machine learning can be divided into:Classification, regression, clustering, anomaly detection, etc.
Raw data is collected from various channels as the input source for the machine learning process.
Common preprocessing in data mining includes data cleaning, data integration, data transformation, data reduction, and data discretization.
Deep learning data preprocessing includes data normalization (including sample scale normalization, mean subtraction per sample, and standardization) and data whitening.Data needs to be divided into three datasets: the training set (training set) used to train the model, the validation set (validation set) used for parameter tuning during development, and the test set (test set) used for testing.
The quality of data labeling is crucial for the success rate of algorithms.
Model training process:Whenever data is input, the model outputs a prediction result, which is used to adjust and update the set of W and B, then train with new data until a model that can predict close to the true result is trained.
Test the model using the test set prepared in the third step of data preprocessing.
Parameters can be divided into two categories: one is hyperparameters that need to be manually set before training (learning), and the other is parameters that do not usually need to be manually set and can be automatically adjusted during training.
Parameter tuning often relies on experience and intuition to explore optimal values, which is more an art than a science and is a key aspect of assessing the capabilities of algorithm engineers.
The model ultimately outputs the interface or dataset for practical application scenarios.
4. Algorithm Classification
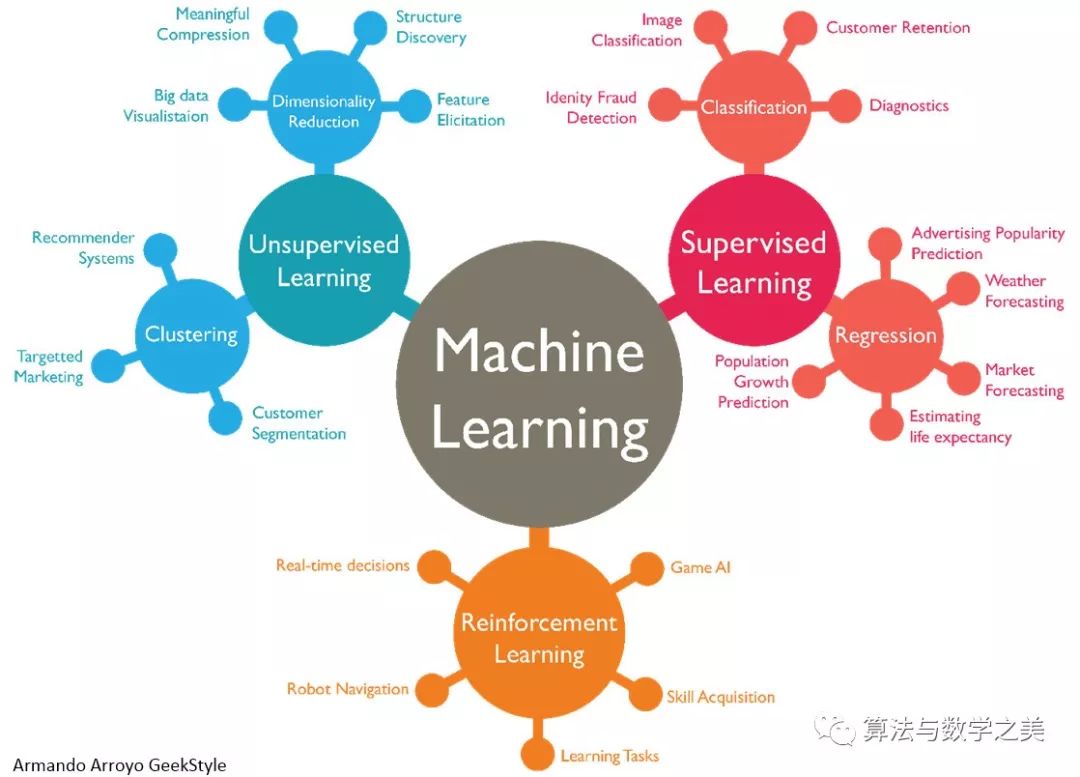 Image Source: https://www.datasciencecentral.com/profiles/blogs/machine-learning-can-we-please-just-agree-what-this-means
Image Source: https://www.datasciencecentral.com/profiles/blogs/machine-learning-can-we-please-just-agree-what-this-means
Machine learning encompasses various algorithms, typically classified by the way models are trained and the tasks they solve.
1. According to the different training methods, it can be divided into
Definition:Supervised learning refers to a system learning from training samples with labeled information to predict the label information of unknown samples as accurately as possible.
Common supervised learning algorithms include:Artificial Neural Networks, Bayesian, Decision Trees, Linear Classifiers (SVM Support Vector Machines), etc.
(2) Unsupervised Learning
Definition:Unsupervised learning refers to a system learning from training samples without labeled information to discover hidden structural knowledge in the data.
Common unsupervised learning algorithms include:Artificial Neural Networks, Association Rule Learning, Hierarchical Clustering, Cluster Analysis, Anomaly Detection, etc.
(3) Semi-Supervised Learning
Meaning:Semi-supervised learning refers to a system learning not only from training samples with labeled information but also from some samples with unknown labels.
Common semi-supervised learning algorithms include:Generative Models, Low-Density Separation, Graph-Based Methods, Co-Training, etc.
(4) Reinforcement Learning
Definition:Reinforcement learning refers to a system learning from unlabeled information but receiving feedback signals (i.e., immediate rewards) from samples to learn a mapping from states to actions that maximizes cumulative rewards; the immediate reward can be seen as an evaluation of the action taken in a certain state of the system.
Common reinforcement learning algorithms include:Q-Learning, State-Action-Reward-State-Action (SARSA), DQN (Deep Q Network), Policy Gradients, Model-Based RL, Temporal Difference Learning, etc.
Definition:Transfer learning refers to improving learning on a new task by transferring knowledge from related tasks that have already been learned. Although most machine learning algorithms are designed to solve single tasks, the development of algorithms that facilitate transfer learning is a continuous focus of the machine learning community.
Transfer learning is common for humans; for instance, learning to recognize apples may help in recognizing pears, or learning to play the keyboard may help in learning the piano.
Common transfer learning algorithms include:Inductive Transfer Learning, Transductive Transfer Learning, Unsupervised Transfer Learning, Transitive Transfer Learning, etc.
Definition:Deep learning refers to multi-layer artificial neural networks and the methods for training them.A single layer of neural networks takes a large matrix of numbers as input, applies nonlinear activation functions to weight them, and generates another dataset as output.
This is similar to the working mechanism of the biological brain, where multiple layers of organized connections form a neural network “brain” for precise and complex processing, just like humans labeling images of objects.
Common deep learning algorithms include:Deep Belief Networks, Deep Convolutional Neural Networks, Deep Recurrent Neural Networks, Deep Boltzmann Machines, Stacked Autoencoders, Generative Adversarial Networks, etc.
The difference between transfer learning and semi-supervised learning:Transfer learning’s initial model is complete, while semi-supervised learning’s labeled portion cannot form a complete model.
2. According to the different tasks solved, it can be divided into
(1) Binary Classification Algorithms, addressing non-binary problems.
(2) Multi-Class Classification Algorithms, addressing multiple categories that are not strictly binary.
(3) Regression Algorithms, typically used to predict specific numerical values rather than classifications.In addition to different output results, other methods are similar to classification problems.Quantitative output, or continuous variable prediction, is called regression; qualitative output, or discrete variable prediction, is called classification.
(4) Clustering Algorithms, aiming to discover potential patterns and structures in data.Clustering is often used to describe and measure the similarity between different data sources and categorize data sources into different clusters.
(5) Anomaly Detection, which refers to detecting and marking abnormal or atypical points in the data, sometimes also referred to as deviation detection.Anomaly detection may seem similar to supervised learning problems, as both are classification problems.Both predict and judge the labels of samples, but the distinction is significant, as the positive samples (anomalies) in anomaly detection are very few.
3. Requirements for AI Product Managers
Product managers should understand and grasp the basic logic, best use scenarios, and data requirements of each common algorithm.
-
Establish a necessary knowledge system for good communication with R&D personnel;
-
Provide necessary assistance when the team needs it;
-
Identify and assess risks, costs, and expected outcomes during the product iteration process.
5. Comparison of Various Algorithms
1. Comparison of Algorithms and Learning Processes
-
Supervised Learning – Classroom:A curious student acquires knowledge and information from a teacher, who provides right or wrong indications and informs the learning process of final answers;
-
Unsupervised Learning – Self-Study:The process of a student studying independently without a teacher;
-
Reinforcement Learning – Self-Assessment:A method of evaluating predictions without teacher prompts.
2. Factors Affecting Algorithm Applicability
3. Advantages and Disadvantages of Algorithms and Applicable Scenarios
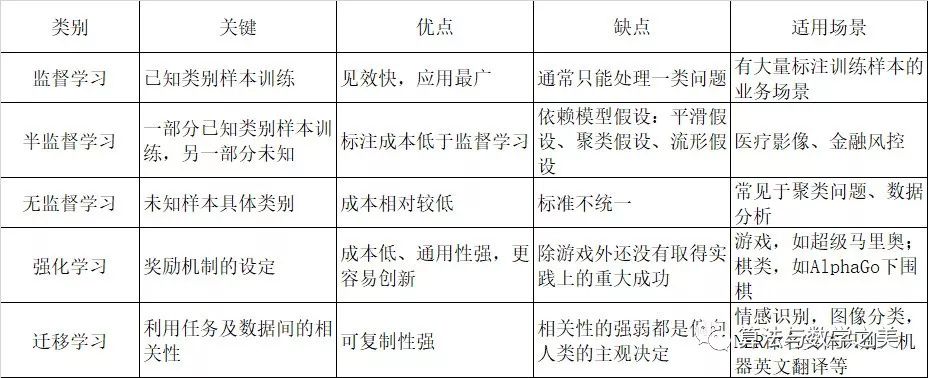
(1) Currently, supervised learning and reinforcement learning are the most widely used and effective machine learning methods.
(2) Deep learning will be introduced in a separate article later.
(3) Semi-supervised learning relies on three model assumptions to ensure good learning performance.
Two samples that are close in dense data areas have similar class labels, while their class labels tend to differ when separated in sparse areas.
When two samples are located in the same clustering cluster, they are likely to have the same class label. This assumption’s equivalent definition is the Low Density Separation Assumption, which states that the decision boundary should pass through sparse data areas, avoiding classifying samples from dense data areas on both sides of the decision boundary.
Embedding high-dimensional data into low-dimensional manifolds, when two samples are in a small local neighborhood within the low-dimensional manifold, they have similar class labels.
-
“Practical Natural Language Processing – Principles and Applications of Chatbot Technology,” Wang Haofen, Shao Hao, et al.
-
“AI Product Manager: Exploring the Design Logic of Human-Computer Dialogue Systems,” Zhu Pengzhen
-
“AI Product Manager: A Handbook for PMs in the AI Era,” Zhang Jingyu
-
“Illustrated Machine Learning,” Sugiyama Masaru
-
https://www.stateoftheart.ai/
-
https://www.stateof.ai/
-
https://www.easyaihub.com/
-
https://blog.csdn.net/daisy9212/article/details/49509899
-
http://www.sohu.com/a/160316515_680198
-
https://research.fb.com/the-facebook-field-guide-to-machine-learning-video-series/
-
https://www.datasciencecentral.com/profiles/blogs/machine-learning-can-we-please-just-agree-what-this-means
-
https://blog.csdn.net/weixin_42137700/article/details/87355812
————
Editor ∑Gemini
Source: Sohu · Everyone is a Product Manager
☞ A plate of braised pork tells you: Where is the difference between undergraduate, master’s, and doctoral degrees?
☞ Modern mathematics is indeed changing the world
☞ Stories of mathematicians
☞ Classic | The Geometric Meaning of Singular Value Decomposition (SVD)
☞ Do you understand algorithms? How to earn millions in a year
☞ His scientific career can be described as an accelerator, becoming a doctoral supervisor at 30, elected as an academician of the Chinese Academy of Sciences at 38, and a member of the German Academy of Sciences at 40…
The beauty of algorithm mathematics WeChat public account welcomes submissions
Submissions related to mathematics, physics, algorithms, computer science, programming, etc., will be compensated upon adoption.
Submission email: [email protected]

